-

Accuracy, Precision, Recall, F1-Score
Confusion Metrics, Accuracy, Precision, Recall, F1-Score Table Of Contents: Confusion Metrics Accuracy Precision Recall F1-Score Specificity (True Negative Rate) Fall-Out : False Positive Rate (FPR) Miss Rate: False Negative Rate (FNR) Balanced Accuracy Example Of Confusion Metrics Confusion Metrics For Multiple Class (1) Confusion Metrics A confusion matrix is a tabular representation of the performance of a classification model. It helps visualize and understand how well a model’s predictions align with the actual outcomes, especially in binary and multi-class classification. (2) Structure Of Confusion Metrics Definition: (3) Accuracy For imbalanced dataset Accuracy will give the wrong impression about the model
-
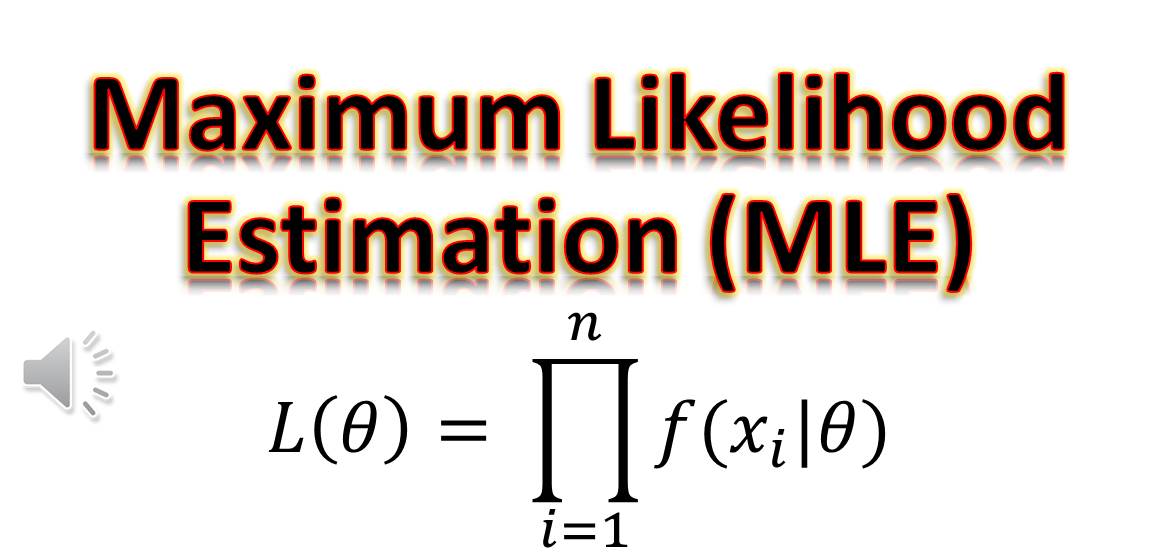
Why We Use Maximum Likelihood Estimation In Logistic Regression?
Why We Use Maximum Likelihood Estimation In Logistic Regression? Maximum Likelihood find out where the Probability is maximum. Minimizing the Loss identifies where the loss is minimum. Table Of Contents: Difference In Maximizing Likelihood and Minimum Loss. (1) How To Find Maximum Likelihood? (2) Maximum Likelihood For Logistic Regression (3) Difference In Maximizing Likelihood and Minimum Loss. (2) Why Differentiating To Zero Gives Us Maximize Log-Likelihood: Differentiating a function and setting it equal to zero helps us find the critical points, which could be maxima, minima, or saddle points. In the context of Maximum Likelihood Estimation (MLE), this principle is
-
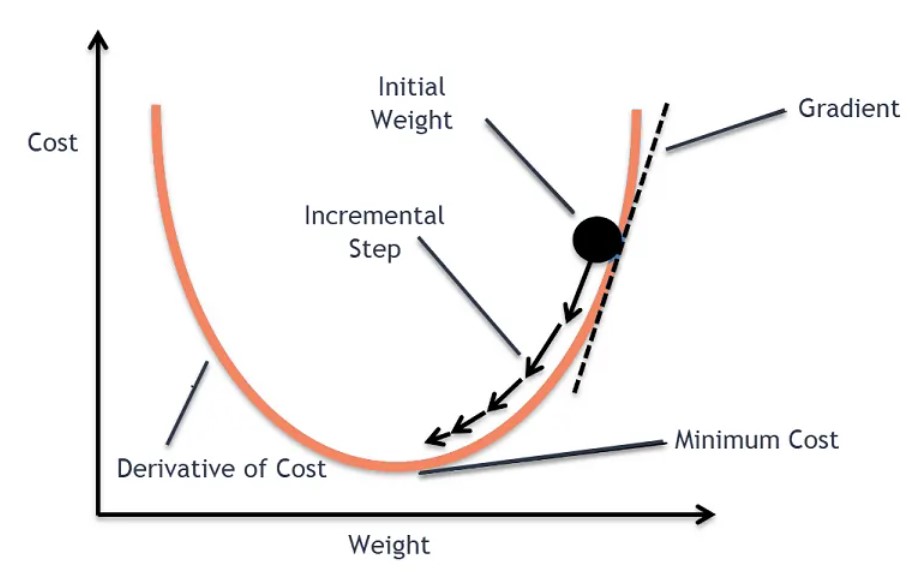
Why We Don’t Use Gradient Descent Algorithm In Linear Regression?
Why We Don’t Use Gradient Descent Algorithm In Linear Regression? Table Of Contents: hI (1) Reason We do apply gradient descent to linear regression, but often it’s not necessary because linear regression has a closed-form solution that is computationally efficient for small to medium-sized datasets. Let me explain: Closed-Form Solution for Linear Regression Here we can directly take the derivative of the Loss function and equate it to zero. Then we can solve the equation to get the optimal value of the beta. How Can We Directly Equate A Single Derivative To Zero To Get The Beta Value. We can
