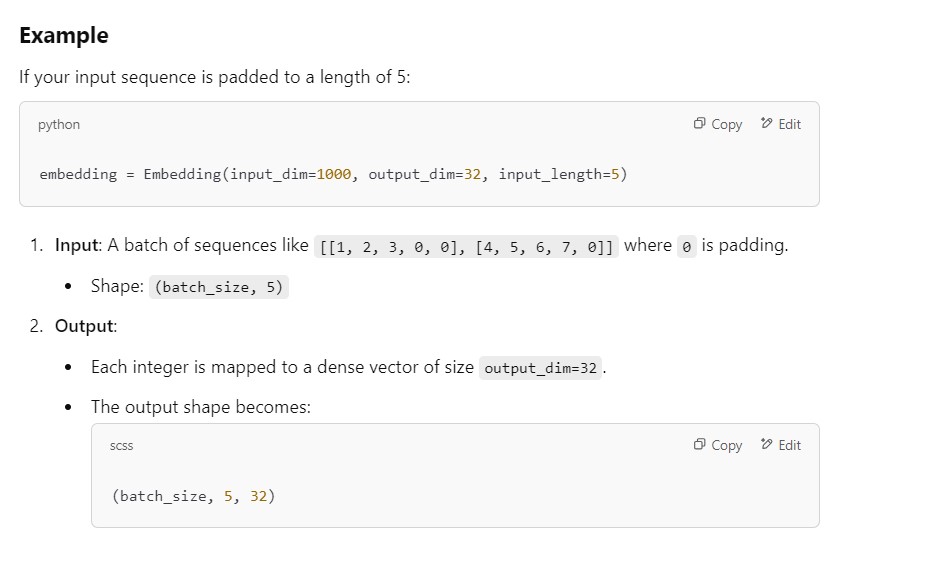
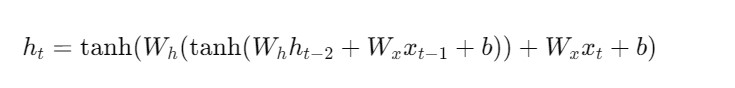how in case of One-to-One Architecture input_length can be 5 but not in one to many processes the sequence as a whole. and entire input sequence step by step (or token by token).
what is the difference Architecture of Recurrent Neural Network (RNN)
Why RNN Uses Same Weights For Every Words?
Super Note:
The RNN architecture depends on how it takes input and produces output.
In One-To-One architecture , return_sequences=False is set False , because we want the model to output a single value (or vector) after processing the entire input sequence. This is typical for tasks where we want to map an entire sequence (input) to a single output.
If we set return_sequences=False d our rnn model will process all the words in a sentence one by one and finally produces the output.
If we set return_sequences=True d out model will give output for each word one by one.
The RNN architecture depends on how it takes input and produces output.
In One-To-One architecture , return_sequences=False is set False , because we want the model to output a single value (or vector) after processing the entire input sequence. This is typical for tasks where we want to map an entire sequence (input) to a single output.
(2) RNN One To One Architecture
A One-to-One RNN (Recurrent Neural Network) is the simplest type of RNN architecture where there is exactly one input and one output.
This architecture is commonly used for tasks where the input-output mapping is straightforward and there is no temporal or sequential dependency.
One-to-one RNNs are used for classification tasks where the input data points don’t depend on previous elements.
Example One -to-One: – Email Spam Detection
# Build the RNN model
model = Sequential([
Embedding(input_dim=1000, output_dim=32, input_length=5),
SimpleRNN(units=16, return_sequences=False),
Dense(1, activation='sigmoid')
])
From the above example we can understand that for one-to-one architecture also we can have “input_length” of 5.
Here the set of 5 words will be considered as single input.
As we have set return_sequence = False, our RNN layer will process all the 5 words one after another and produces a single output.
(3) RNN One To Many Architecture
An RNN one-to-many architecture refers to a model setup where the RNN processes a single input sequence and produces multiple outputs.
This means that while there is one input sequence, the model generates a sequence of multiple outputs, typically one for each timestep or for a predefined sequence length.
Example One To Many – Next Word Prediction
# Build the One-to-Many RNN Model
model = Sequential([
Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=1),
SimpleRNN(rnn_units, return_sequences=True), # Outputs a sequence
Dense(vocab_size, activation='softmax') # Predict the next word for each timestep
])
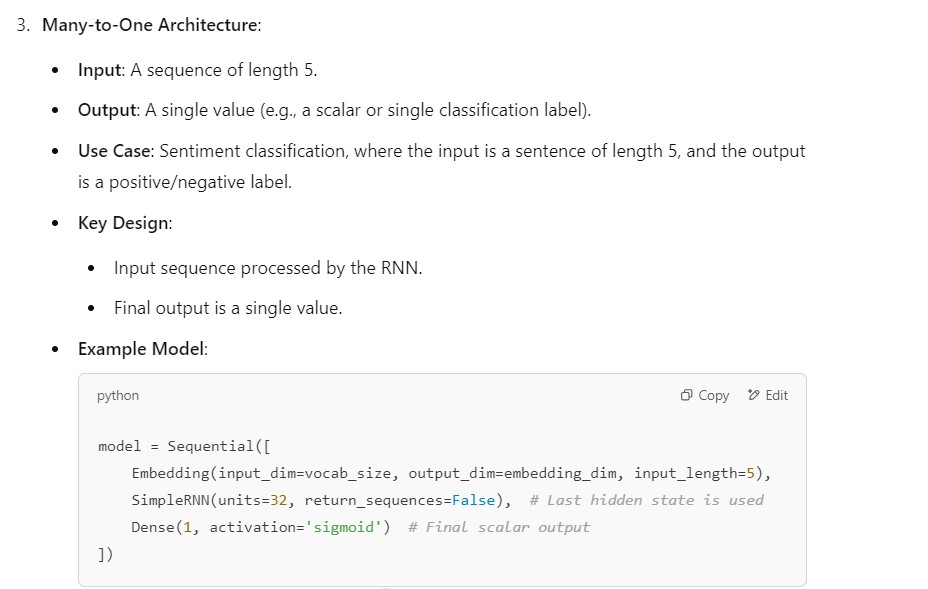
(4) RNN Many To One Architecture
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(vocab_size, 50, input_length=max_sequence_length))
model.add(tf.keras.layers.SimpleRNN(128, return_sequences=True)) # Many-to-Many RNN
model.add(tf.keras.layers.Dense(vocab_size, activation='softmax')) # Predict next word for each timestep
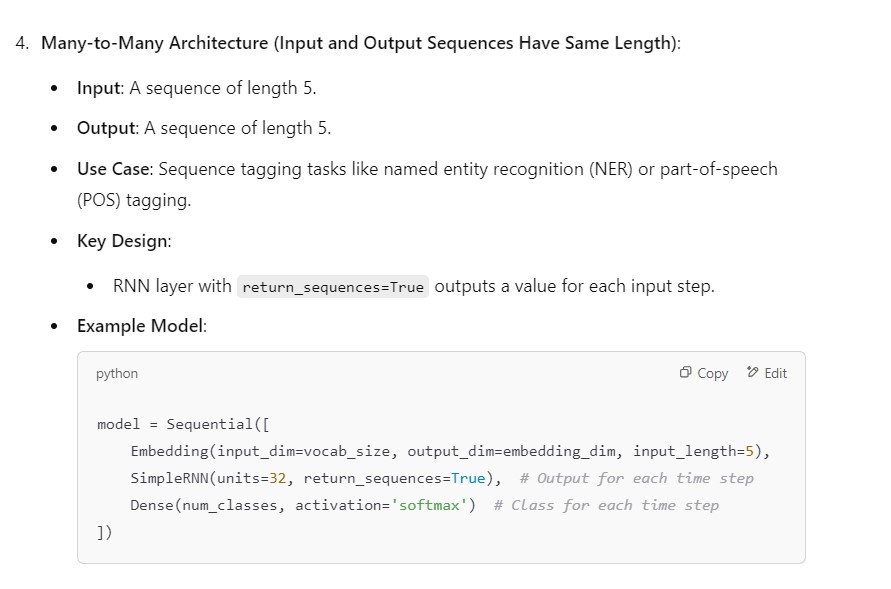
(5) RNN Many To Many Architecture
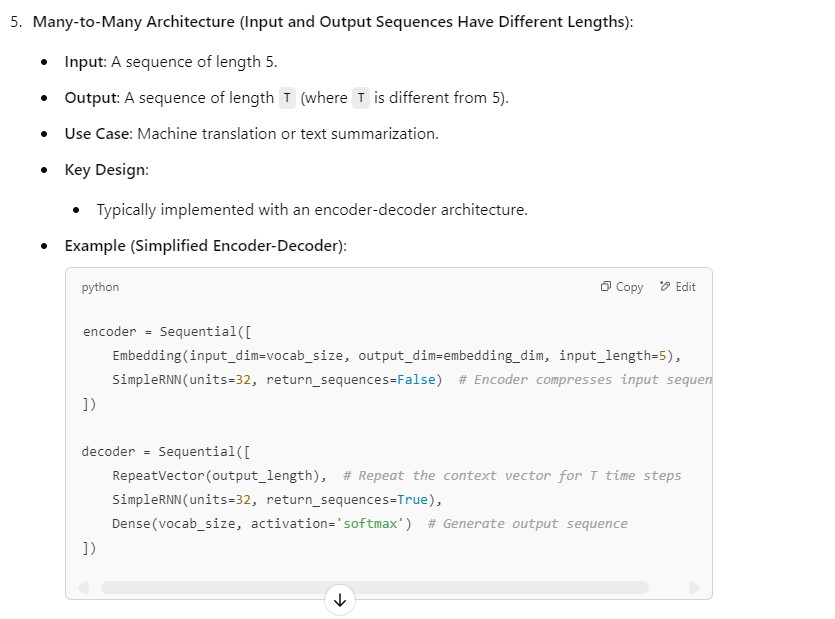
(6) how in case of One-to-One Architecture input_length can be 5 but not in one to many
The distinction between the One-to-One and One-to-Many architectures lies in how the input and output are processed, rather than the value of input_length itself.
Let me clarify why input_length=5 is valid in One-to-One but not typically applicable in One-to-Many.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense
model = Sequential([
Embedding(input_dim=1000, output_dim=32, input_length=5), # Sequence of length 5
SimpleRNN(32, return_sequences=False), # Outputs only the final hidden state
Dense(1, activation='sigmoid') # Single scalar output
])
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense, RepeatVector, TimeDistributed
model = Sequential([
Embedding(input_dim=1000, output_dim=32, input_length=1), # Single token input
SimpleRNN(32), # Processes the single input
RepeatVector(5), # Repeats context for each output step
SimpleRNN(32, return_sequences=True), # Generates a sequence
TimeDistributed(Dense(1000, activation='softmax')) # Output sequence
])
(7) processes the sequence as a whole. and entire input sequence step by step (or token by token).what is the difference
(8) Architecture of Recurrent Neural Network (RNN)
(9) Why RNN Uses Same Weights For Every Words?
Let’s explain mathematically how using different weights at each time step in an RNN leads to a situation where it doesn’t retain information from previous tokens, i.e., how the network becomes unable to process the sequence context.
Super Note:
By keeping Wh constant we are applying the same transformation for every time step.
If we change Wh for every time step the initial (h1) will be different when it comes to (h2).
Hence by keeping (Wh) constant we will apply same transformation to (h1) in (h2) also, hence we will keep the initial (h1) value intact.