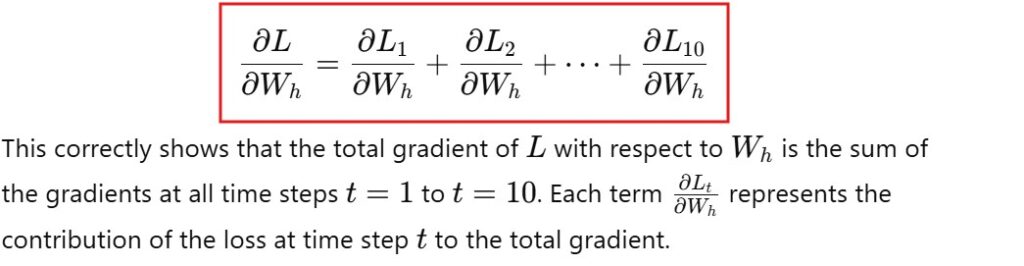How Vanishing Gradient Problems Solved By The LSTM ?
Table Of Contents:
What Is Vanishing Gradient Problem?
Why Does It Occurs In RNN?
(1) What Is Vanishing Gradient Problem?
Thevanishing gradient problem is a challenge that occurs during the training of deep neural networks, particularly in networks with many layers.
It arises when the gradients of the loss function, which are used to update the network’s weights, become extremely small as they are backpropagated through the layers of the network.
This is the gradient calculation with only one layer.
With only one layer you can see that three terms multiplying together.
If you have 10 hidden layers you will have around 30 different terms multiplying together.
If we multiply smaller terms multiple times he result will be even smaller.
As a result the gradient of the error term will be negligible.
Hence the weights updating will not happen or it will happen too slowly.
(2) Why Does RNN Suffers From Vanishing Gradient Problem?
Suppose you are passing a sequence of 10 words.
Here in RNN we need to calculate 2 different weights and 1 biases.
Wh and Wx are the weights.
b is the bias terms.
The weights and biases are being calculated using the below formula.
Here the point to note is that the weights are not calculated during the training process, these new weights are calculated once you pass all the words in a sequence.
Suppose you have 10 words in a sequence the new weight will be calculated once we accumulate gradients for all the time steps.
Below is the calculation of the gradient for all 10 time steps.
You need to sum up all the individual gradients up to that point.
You pass a single word and calculate the loss and calculate the gradient for that time step word.
I fyou have two words you will sum up two gradients like that it will go on.
If you individually calculate the gradients , lets see for L10.
It will looks like below equation.
Here you can see that the gradients uses the chain rule which is the multiplication of different terms.
Once you have a smaller terms in any part, the entire equation will be smaller if we multiply it together.
Note:
In RNN long term memory issue happens because the earlier words will be forgotten by the RNN network due to the vanishing gradient issue.
The 10 word from first, when we calculate its gradient it will be too small or close to zero because of its repeated multiplication.
Hence its contribution toward the weight update will be forgotten
(3) How LSTM Solves The Vanishing Gradient Problem?
LSTM implement the 3 different gates.
LSTM implements two different states one is Cell State and another one the the Hidden State.
Cell state is used to store long term memory.
Hidden state is used to hold the short term memory.
It also has Forgot Gate, input Gate and The Output Gate.
Until unless Forgot Gate tells the network to forget about some words the Long term memory cell state will keep that work till the end.
Hence in this way LSTM remembers the longterm context easily.
Is LSTM also uses the chain rule for longer sequences the gradients will be small again ?
Yes, LSTMs use the chain rule for backpropagation through time (BPTT), which means that the gradients are computed by propagating errors backward through all time steps in the sequence.
While LSTMs mitigate the vanishing gradient problem better than vanilla RNNs, the issue can still occur for very long sequences due to the following reasons: