
Multi Head Attention
Table Of Contents:
- Disadvantages Of Self Attention Mechanism.
- What Is Multi-Head Attention ?
- How Multi Headed Attention Works ?
(1) Disadvantages Of Self Attention.

- The task is read the sentence and tell me the meaning of it.
- Meaning-1: An astronomer was standing and another man saw him with a telescope.
- Meaning-2: An astronomer was standing with a telescope and another man just saw him.
- In this sentence we are getting two different meaning of a single sentence.
How Self Attention Will Works On This Sentence ?
- The self attention will find out the similarity of each word with the rest of the words.
- There is a chance that we will get a higher relationship between Man and Telescope.
- If Man and Telescope having higher relationship then the then it will have Meaning-1 as an output.
- There will be also another interpretation if we have higher relationship between Astronomer and Telescope.
- In this case the output will me Meaning-2.
Problem With Self Attention:
- The problem with self attention is it can only capture a single perspective of the sentence.
- With a single self attention we can’t capture the multiple perspective of a single sentence.
Real World Scenario:

- For a text summarization task if we are using a single headed self attention we will never be able to derive multiple summary of a text.
(2) What Is Multi-Head Attention ?
- The above problem is solved using the Multi-Head attention mechanism.
- Instead of using a single self attention approach we can use more than one self attention mechanism.
- Each self attention mechanism will capture different relationships in a single sentence.
How Multi Head Self Attention Works?
- Let us take 2 self attention and see how it works.
- Step-1: Generate 6 Query, Key and Value pair metrics for 2 self attention approach
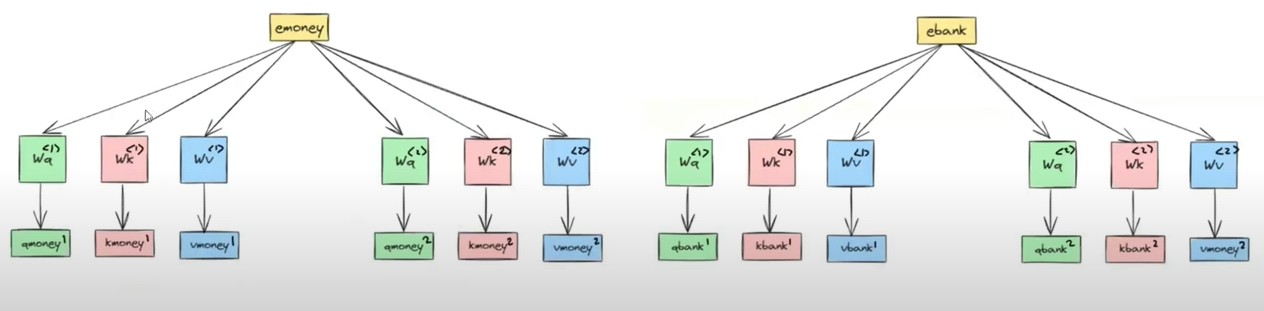
- For a single self attention technique we will have 3 metrices Wq(1), Wk(1), Wv(1)
- By using this 3 metrics we will get Qmoney(1), Kmoney(1) and Vmoney(1) as 3 component vectors.
- If we are using 2nd self attention in our model it will also have it own metrices Wq(2), Wk(2), Wv(2)
- By using this 3 metrics we will get Qmoney(2), Kmoney(2) and Vmoney(2) as 3 component vectors.
- In the above diagram we have displayed the 2 different self attention approach.
- We have taken for two words ‘Money’ and ‘Bank’.
- With this approach we are getting 2 sets of Query , Key and Value vectors for a single word.
- Output = [Qmoney1, Qmoney2], [Kmoney1, Kmoney2], [Vmoney1, Vmoney2].
- Step-2: Apply Separate Self Attention For Same Word Using Different Key, Value , Query metrics.
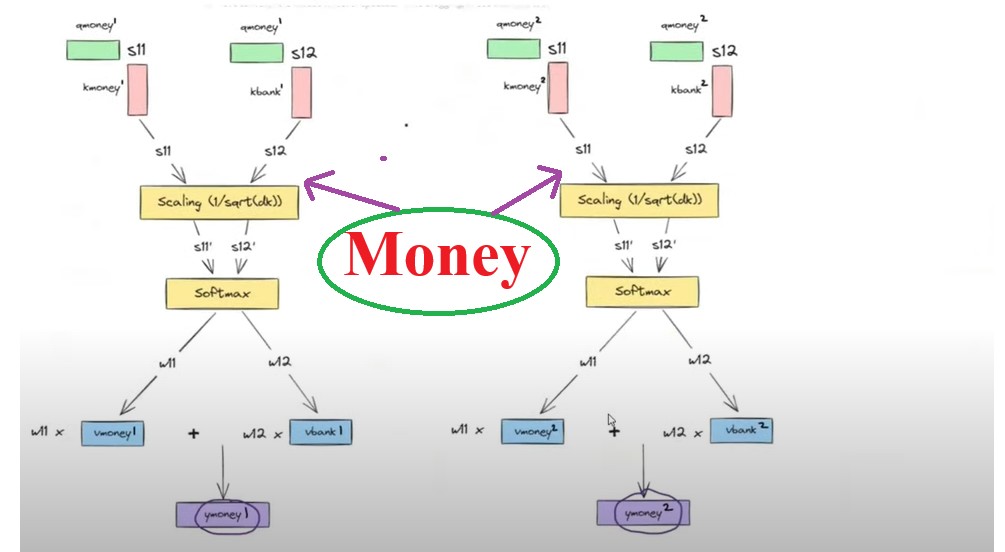
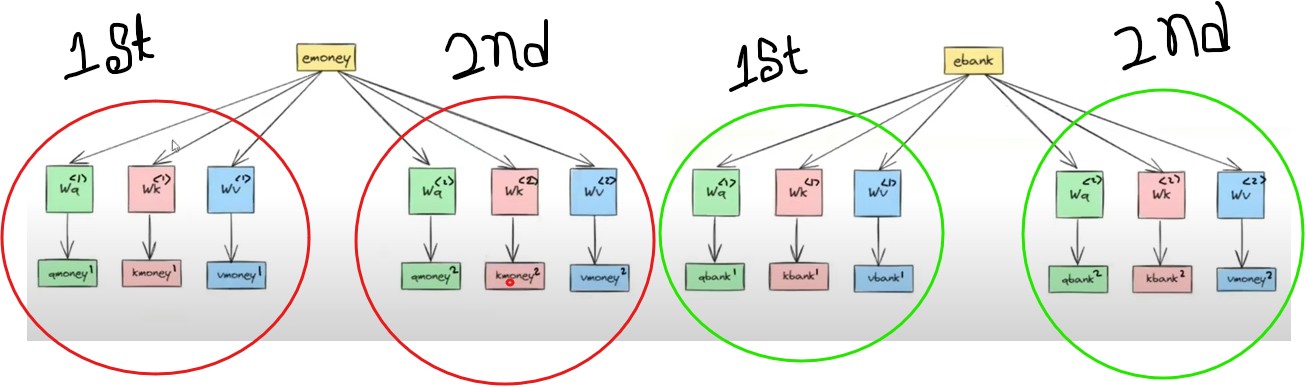
- Let us apply self attention technique for the word “Money”.
- In the above diagram we can see that we have two separate self attention models.
- Each self attention model uses its own Key, Value and Query metrics.
- The resultant output will be the 2 different context vectors for the same word ‘Money’.
- eMoney = Ymoney(1) and Ymoney(2).
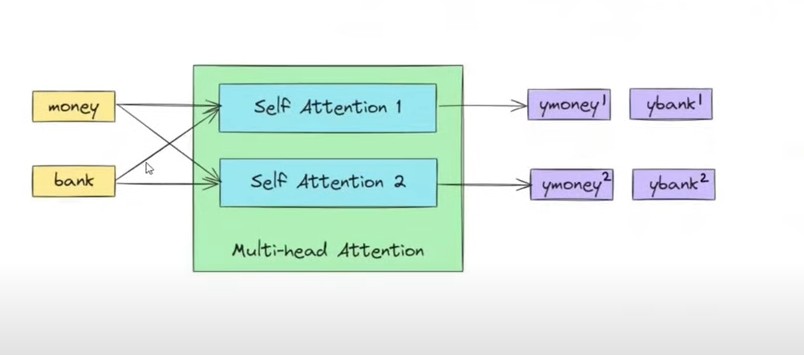
- Above diagram shows how using 2 different self attention technique we can get the 2 separate context vectors for a same word.
- Here we are sending the word ‘Money’ to the both ‘Self Attention 1’ and ‘Self Attention 2’.
- Similarly we are passing the word ‘Bank’ to the both ‘Self Attention 1’ and ‘Self Attention 2’.
- As an output we are getting Ymoney(1), Ybank(1) and YMoney(2), Ybank(2).
- Note: In original Transformer paper researchers are using 8 self attention nodes.
(3) How Multi Headed Attention Works?
Understand It In Metrics Format.
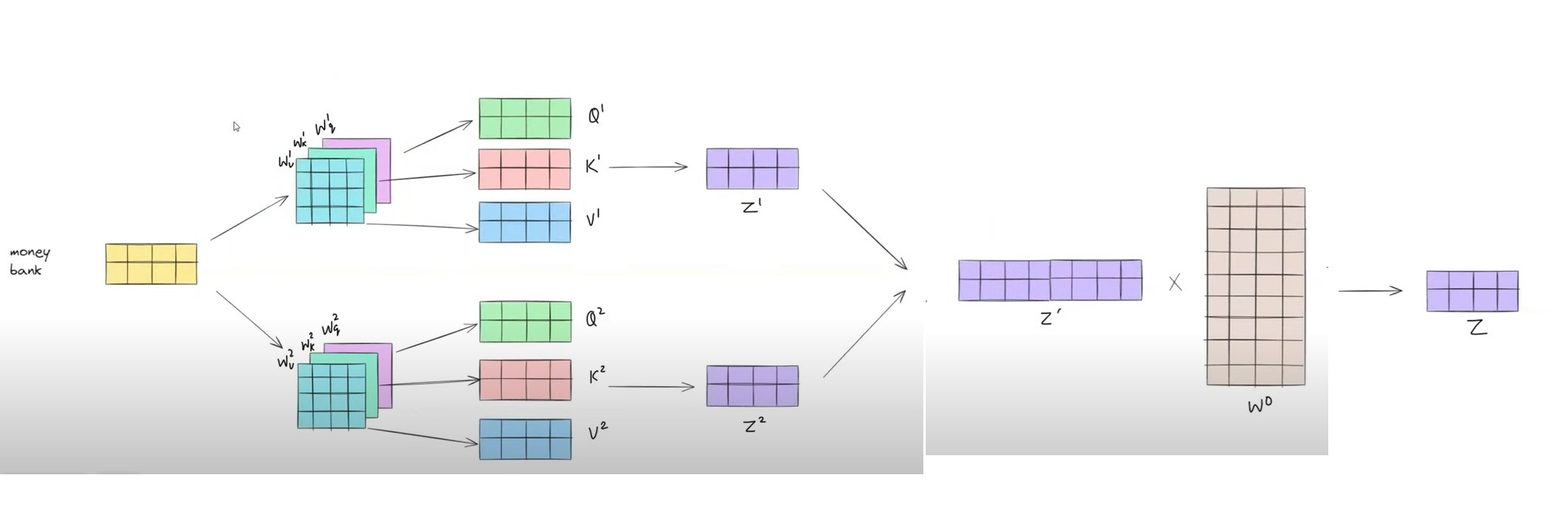
Step-1: Generate Static Embedding Of Input Words
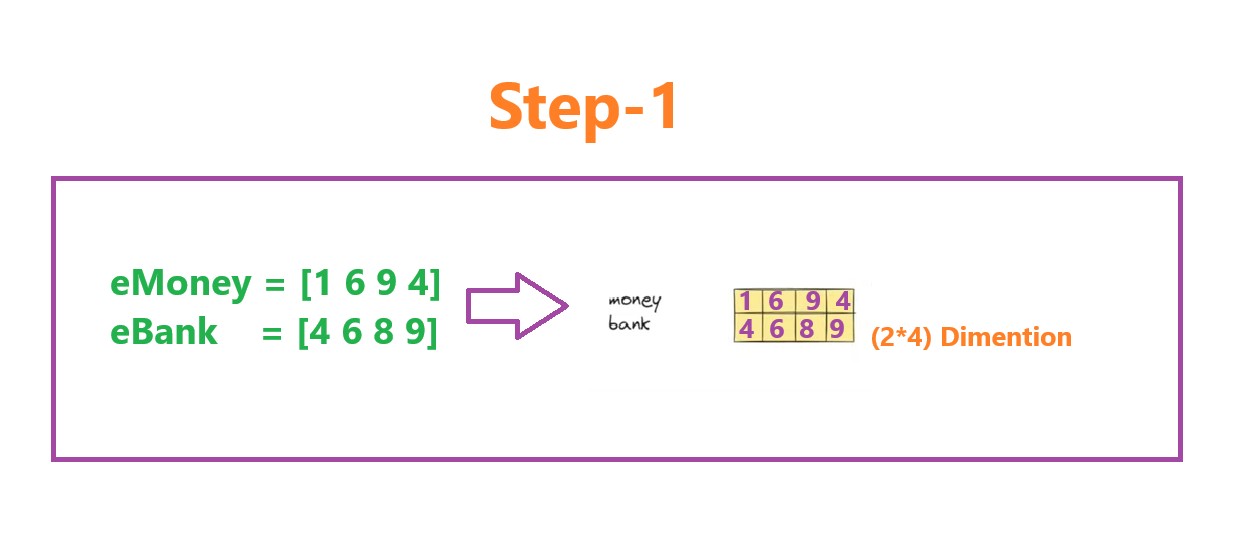
- First step is to generate the static embedding of the input words.
- In our example we have two words “Money Bank”.
- We convert this individual words as vectors and pass it as 2*4 dimension vector metrics.
Step-2: Generate 2 Separate Metrics(Query, Key , Value) For 2 Self Attention Model
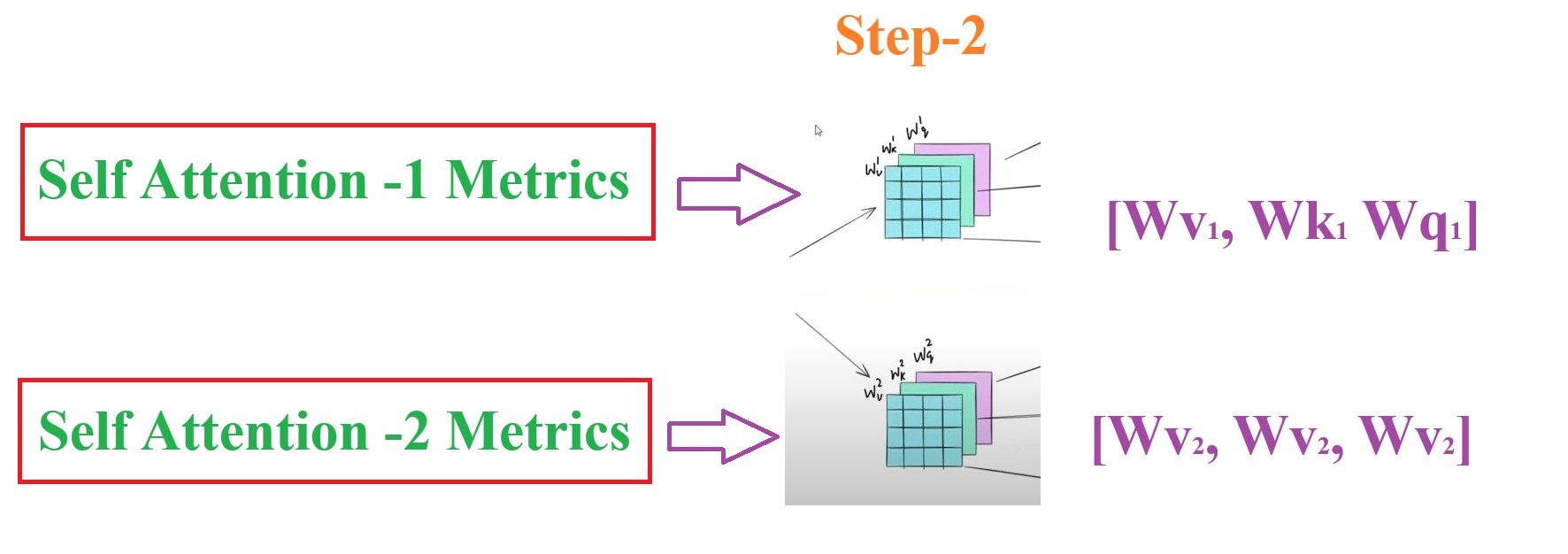
- In the second step we prepare the 6 different metrices which are key, value and query metrices.
- First 3 will be for first Self Attention node and another 3 will be for 2nd self attention node.
- These metrics are derived from the training process from the input data.
Step-3: Generate Individual Query, Key and Value Vectors For Each Word
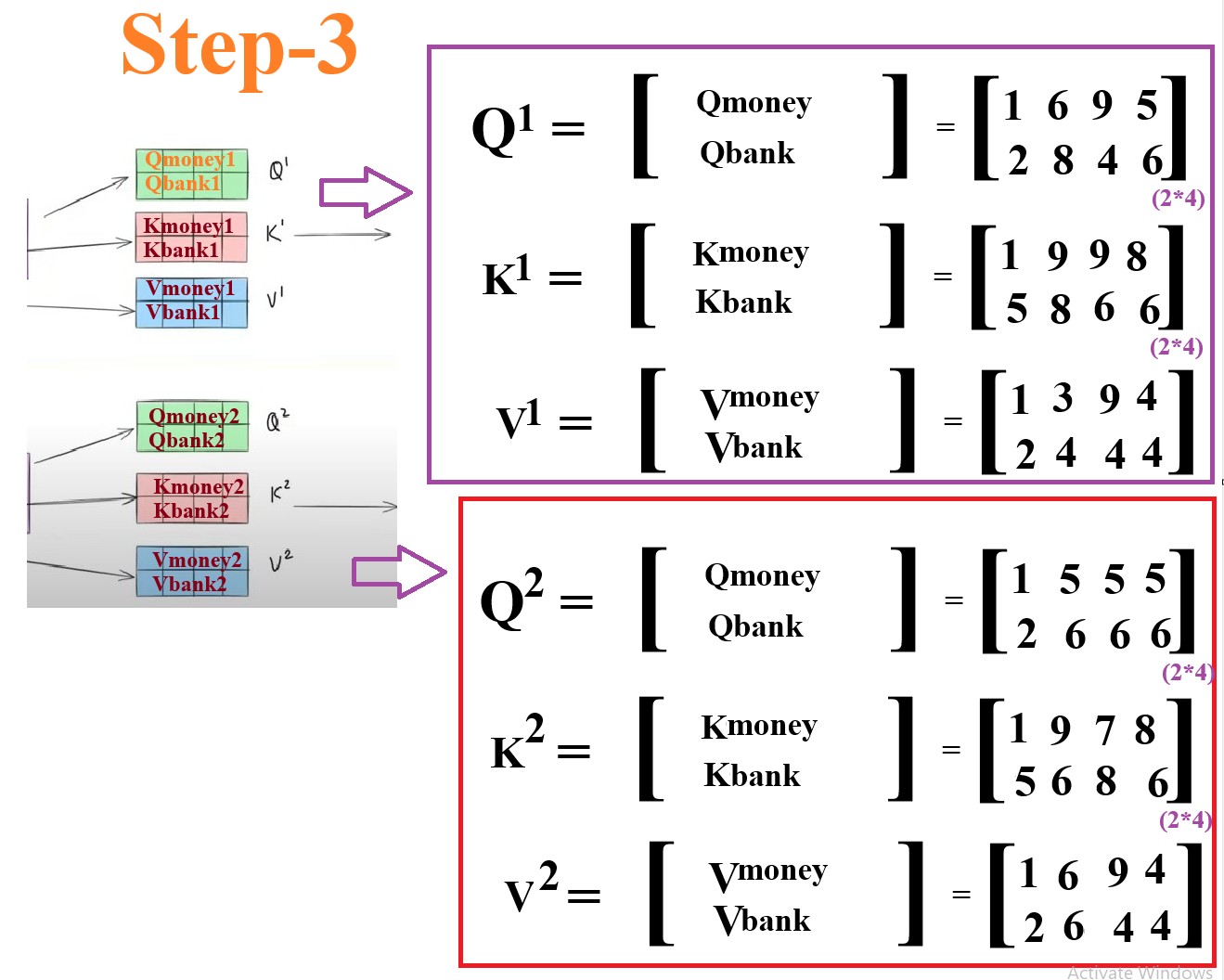
- Third step is to get the 3 component vectors for individual words.
- From 1st Self Attention Node:
- Money = Qmoney1, Kmoney1, Vmoney1
- Bank = Qbank1, Kbank1, Vbank1
- From 2nd Self Attention Node:
- Money = Qmoney2, Kmoney2, Vmoney2
- Bank = Qbank2, Kbank2, Vbank2
- Q1 will be the combination of the Qmoney and Qbank hence it will be the 2*4 dimensional vector.
Step-4: Apply The Self Attention On Individual Words.
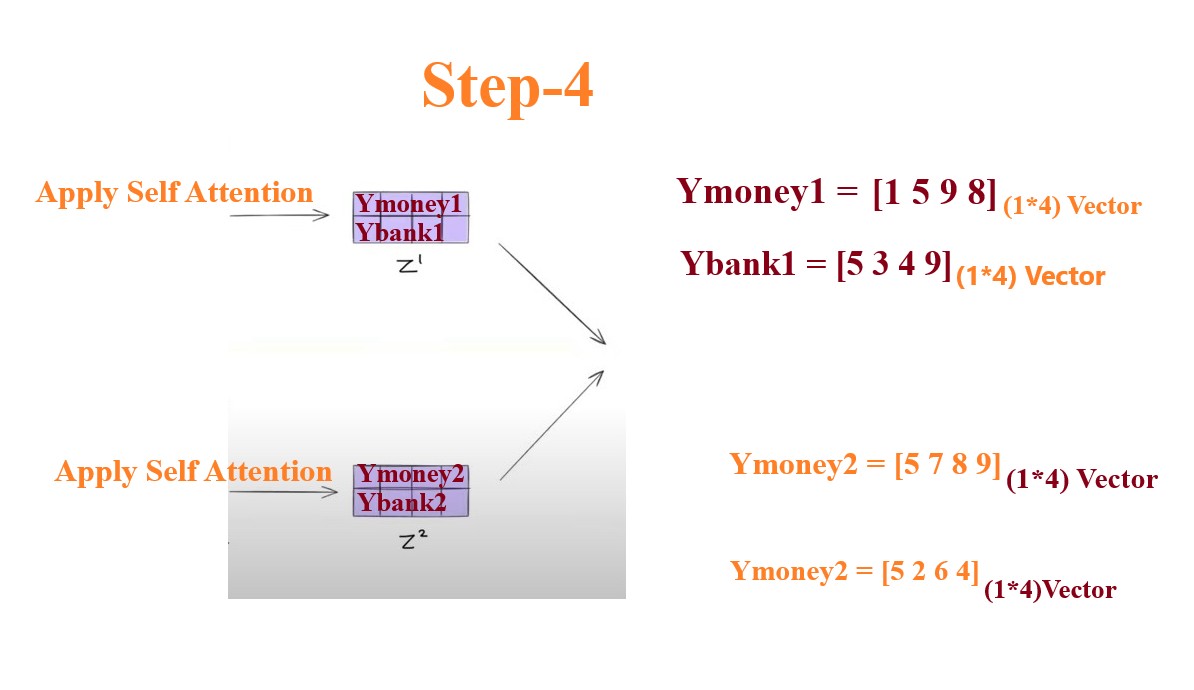
- Step-4 is to apply the self attention technique to the output of the step-3.
- From 1st self attention we will get Ymoney1 and Ybank1 and from the 2nd self attention we will get Ymoney2 and Ybank2.
- These are the contextual output from the self attention mechanism.
- So here we are getting 2 different perspective of a single word.
- Money = Ymoney1 and Ymoney2.
- Bank = Ybank1 and Ybank2.
Step-5: Concatenate The Z1 and Z2 vectors into the single (2*8) Vector

- Step-5, Now we concatenate Z1 and Z2 vectors to combine the 2 different meanings of a single word.
- We need to convert the Z` of (2*8) vector to the original input shape of (2*4) vector.
Step-6: Do Linear Transformation Of Z` Vector
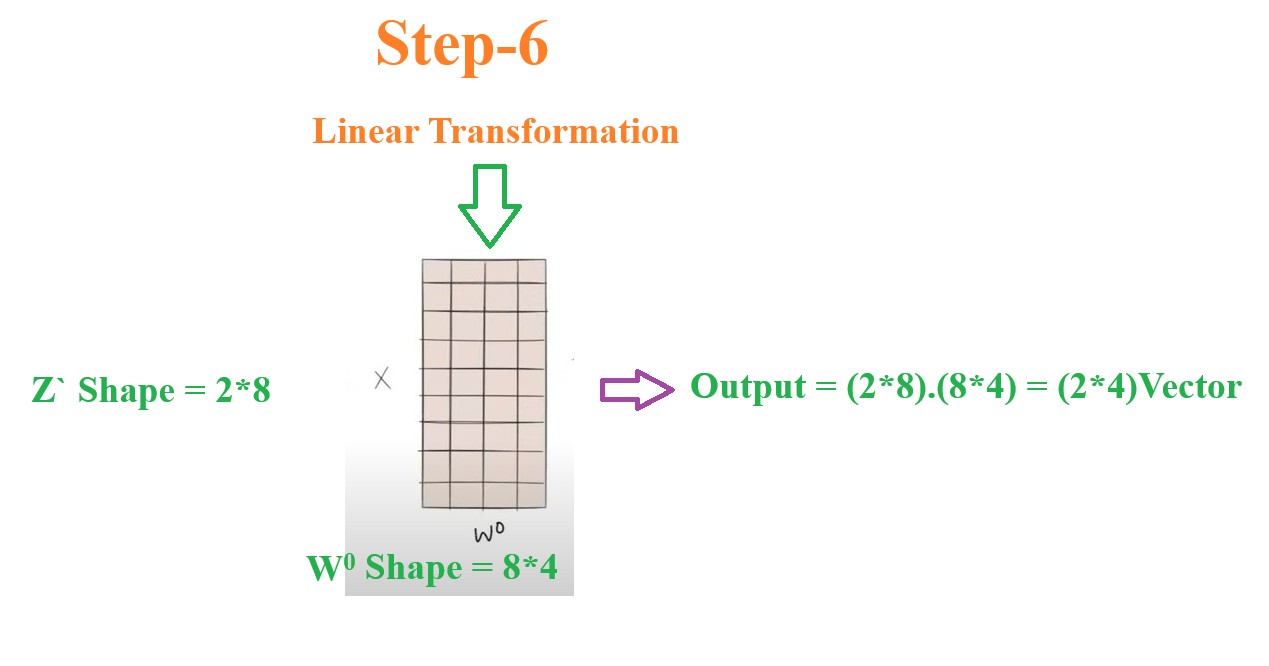
- We need to convert our output context vector into the same input shape.
- Now our output vector Z` is of shape = (2*8)
- But our input shape is equals to (2*4).
- Hence we need to do the linear transformation of the Z` vector.
- To do this wee need to multiply it with a matrix of size (8*4)
- This (8*4) metrics will be derived from the training process.
- The intuition behind this (2*8) metrics is it will draw the balance between the two perspectives of the word, if one perspective is more dominant it will keep that or if two perspectives are of same importance it will keep both.
- Hence Output = (2*8)(8*4) = (2*4).
Step-7: Derive The Final Output

- Now we will get the final output of the shape of (2*4) same as the input shape.
- This output will have a mix of both the perspective of the same words ‘Money’ and ‘Bank’.
Step-8: Original Paper Architecture.
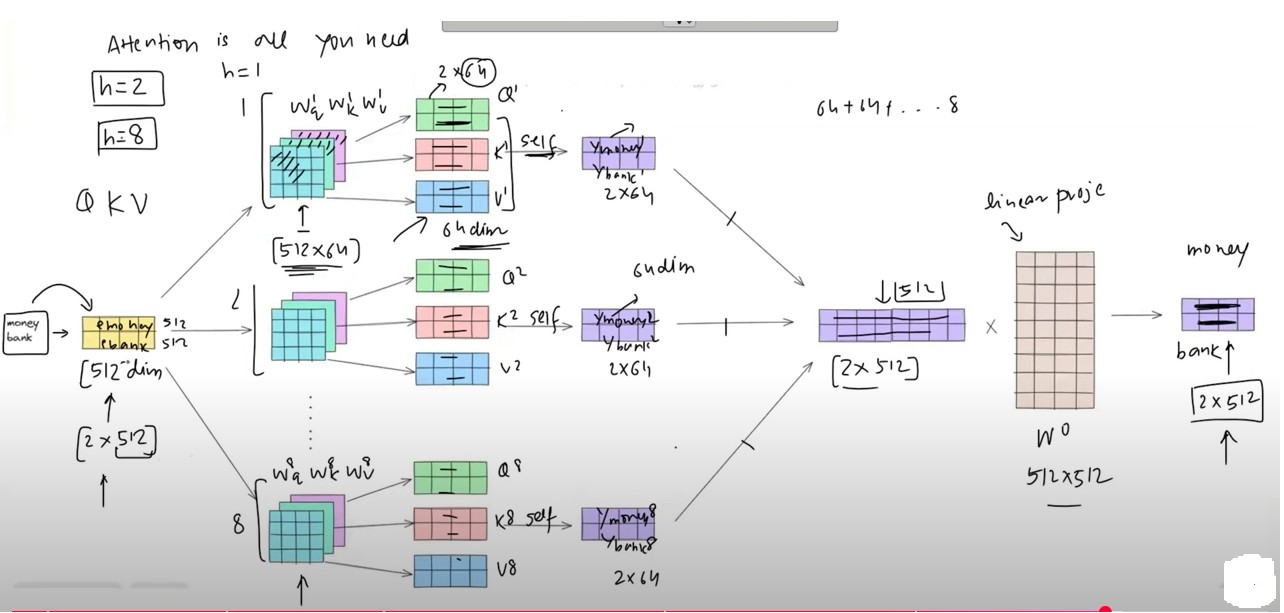
- In the original paper we have 8 attention heads.
Step-9: Visualizing The Attention Scores
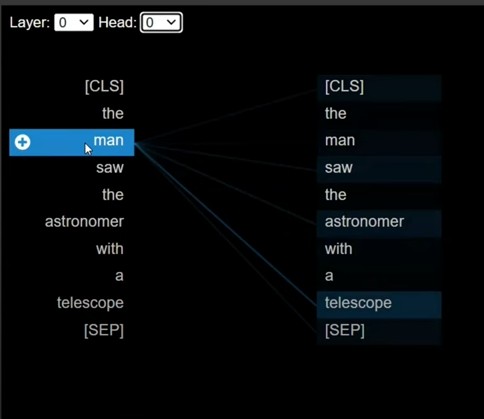
- This diagram is for Self Attention-1
- In the above example we can see that man and telescope are highly similar.
- Means there vectors are quite nearer to each other.

- This output is for self attention – 2
- In the above example we can see that man and astronomer are highly similar.
- Means there vectors are quite nearer to each other.