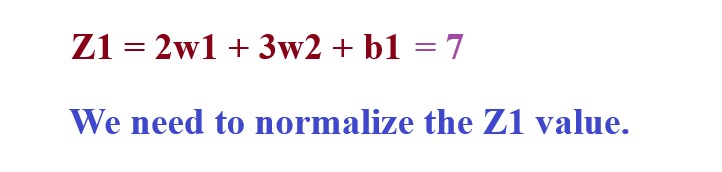Why Batch Normalization Does Not Works On Sequential Data ?
(1) What Is Normalization?
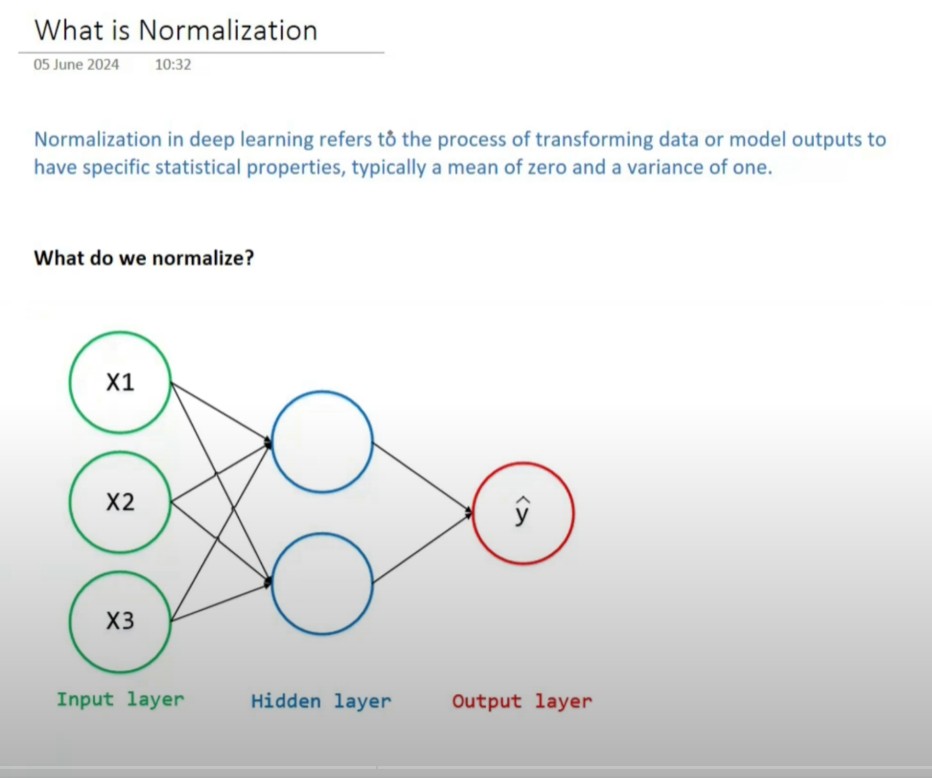
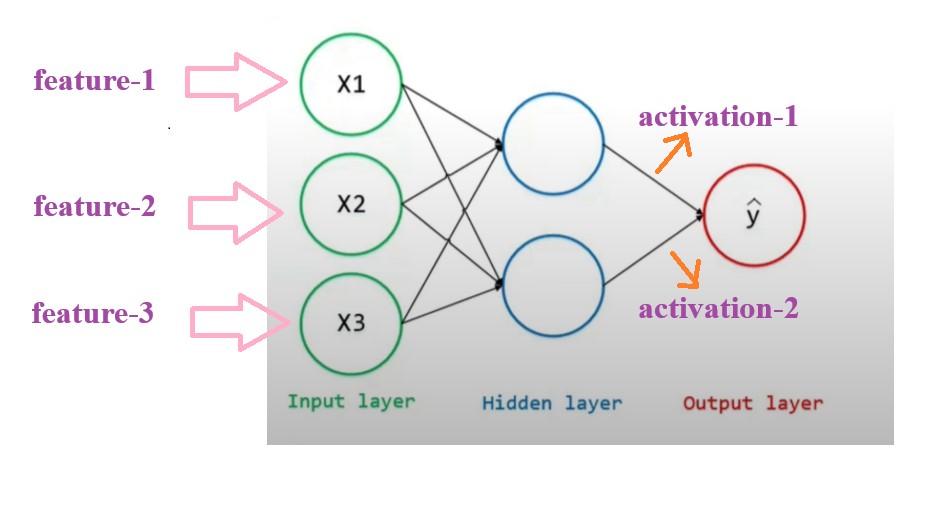
What We Are Normalizing ?
Generally you normalize the input values which you pass to the neural networks and also you can normalize the output from an hidden layer.
Again we are normalizing the hidden layer output because again the hidden layer may produce the large range of numbers, hence we need to normalize them to bring them in a range.
(3) Why Batch Normalization Does Not Works On Sequential Data ?
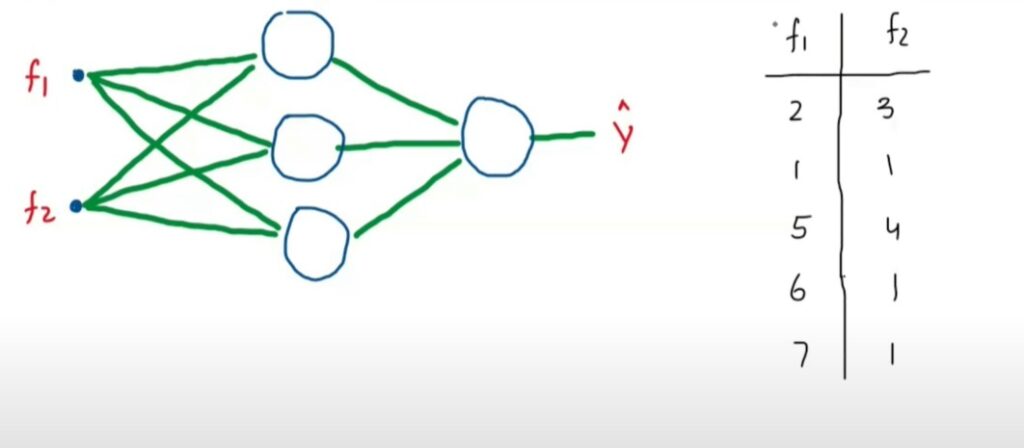
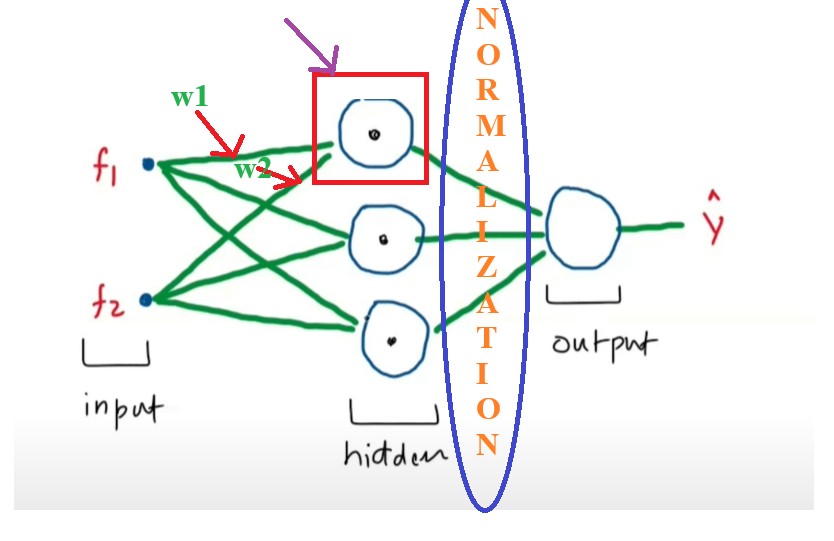
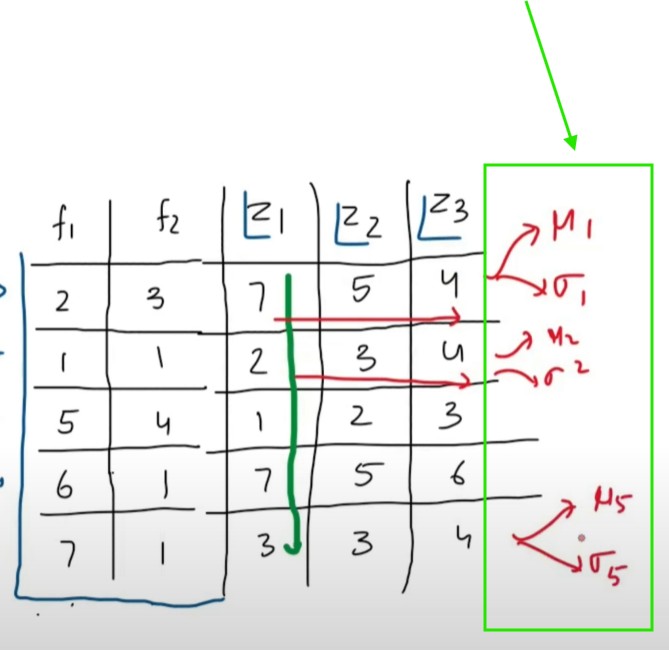
Suppose we have f1 and f2 as input and we will train our neural network on this input.
Lets apply Batch Normalization on the output of the first layer and see what’s the problem.
We will send data in batches to this neural network.
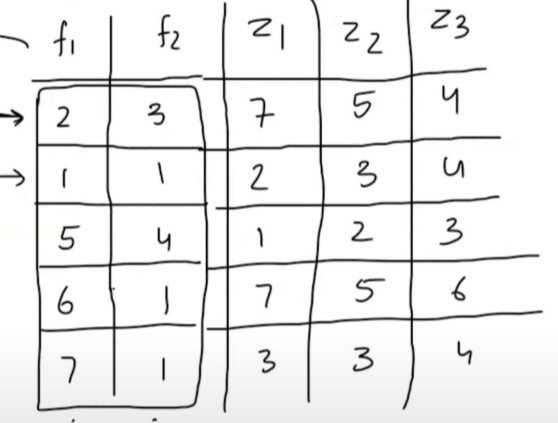
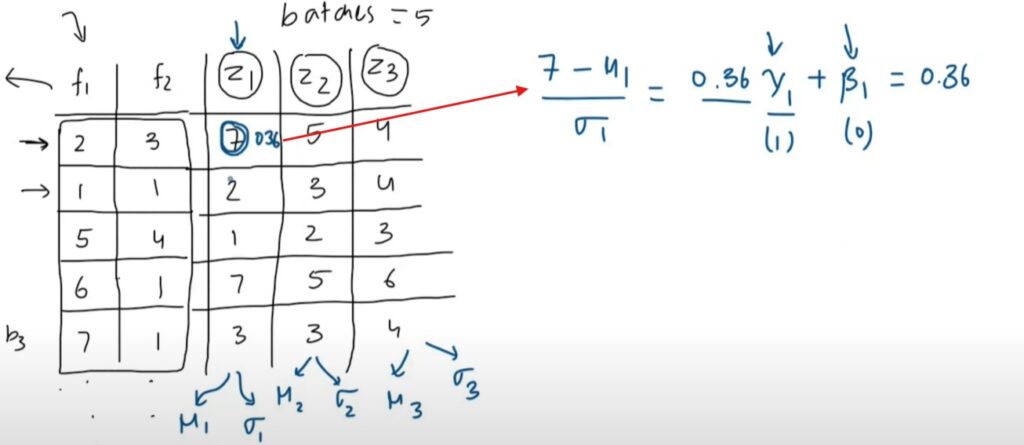
Lets take Batch Size = 5,
First we will send the first row records which is (2 , 3).
And lets focus on the first node and its two incomingweights(w1, w2).
We will calculate the activation value for the 3 nodes for every input value.
We will have the output for first node.
Like this we will calculate the output for other 2 nodes.
We will have (Z1, Z2 ,Z3) as an output for every inputfeature value.
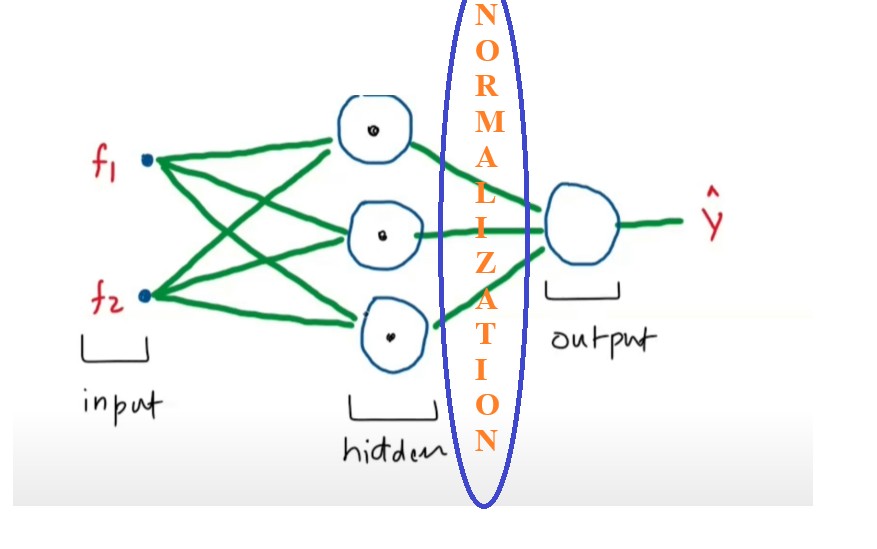
Now we need to normalize the Z1, Z2 and Z3 values.
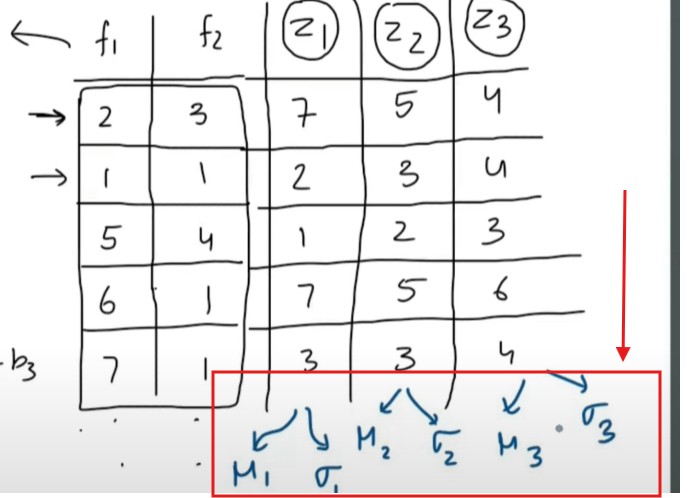
We will calculate the mean and standard deviation of the each output and normalize them.
We will apply the batch normalization to the every value of the (Z1, Z2 AND Z3).
We will apply learnableparametergamma and beta.
Why Do Batch Normalization Does not Works On Sequential Data?
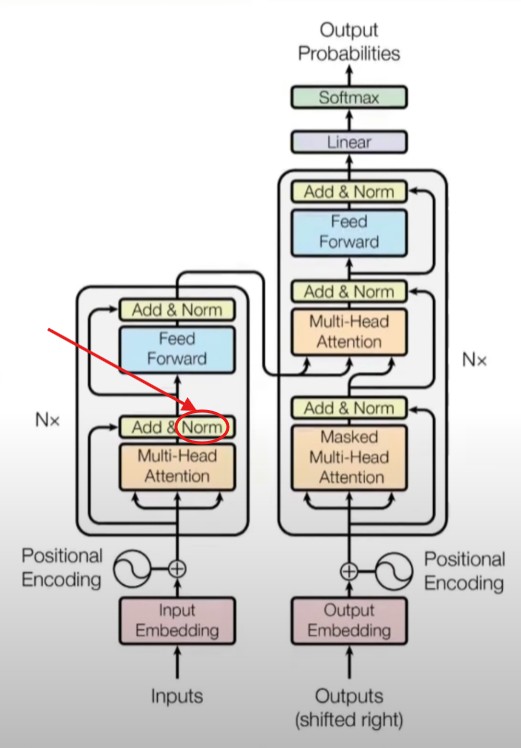
In the Transformer architecture the Normalization is applied to the output of the Self Attention mechanism.
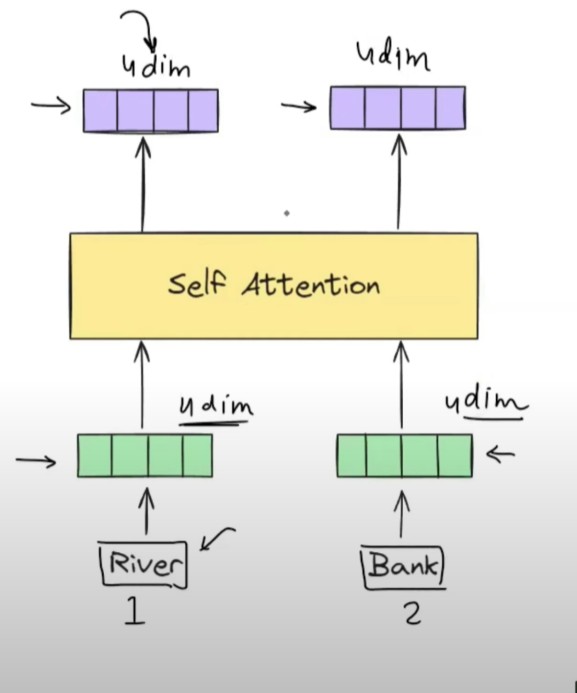
Let us see how the output for the self attention comes if we pass sentences as an input.
At a time i will send 2 sentences to my self attention model.
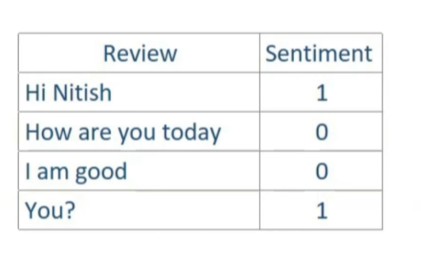
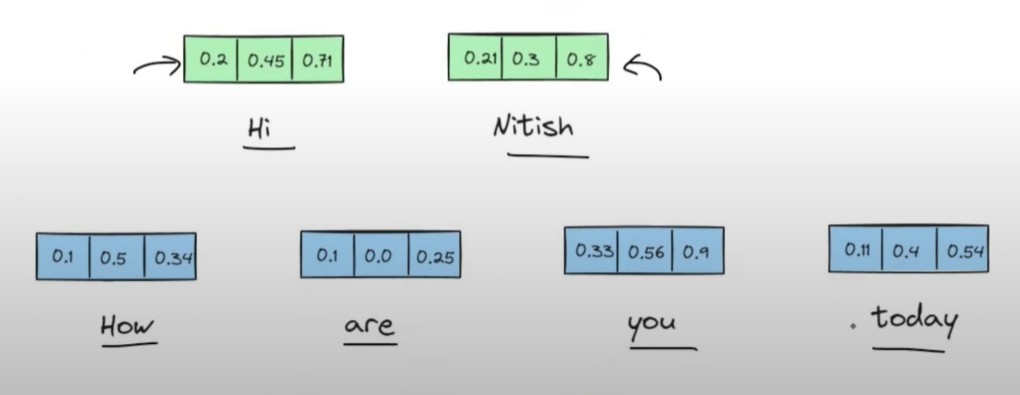
Sentence-1: Hi Nitish
Sentence-2: How Are You Today.
Hence my Batch Size = 2.
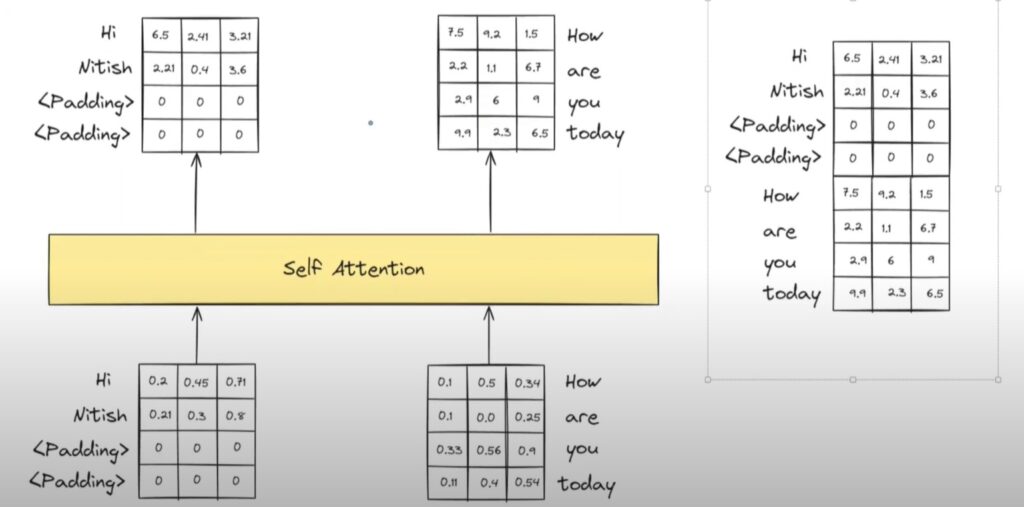
First I will calculate the embedding vector for each word. Like shown in below image.
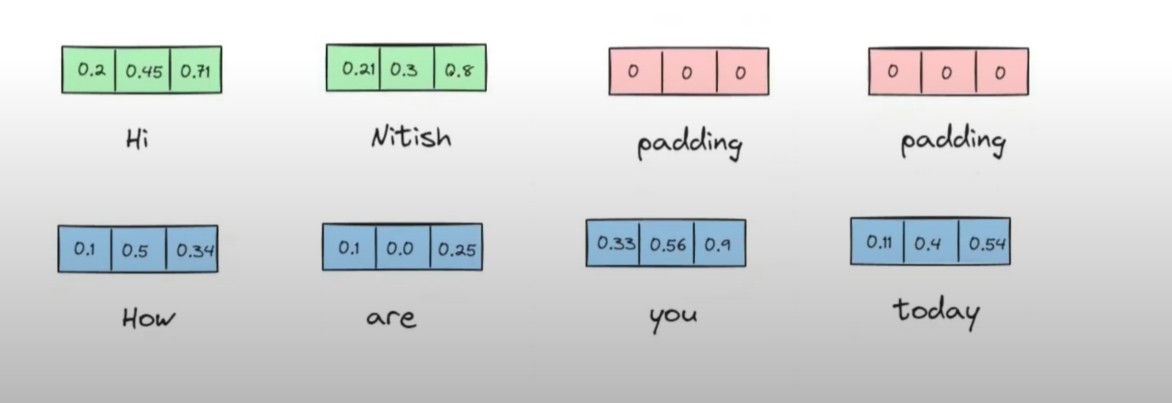
The problem here is in the 1st sentence we have only 2 words and in the 2nd sentence we have 4 words.
You have to make sure the length of each sentence should be same.
You will use the concept of padding to make same length sentence.
After padding your embedding vector will looks like this.
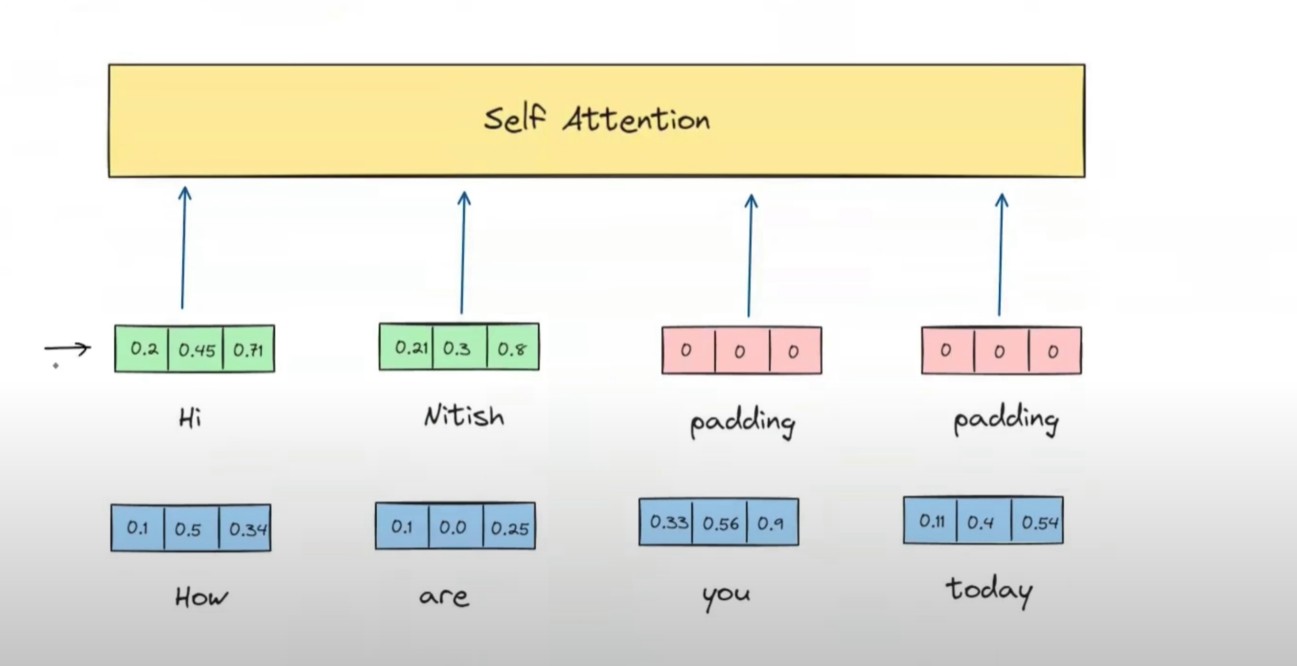
Now the input to the Self Attention will looks like this.
And we need to calculate the contextual embedding of each words in a sentence using the Self Attention.
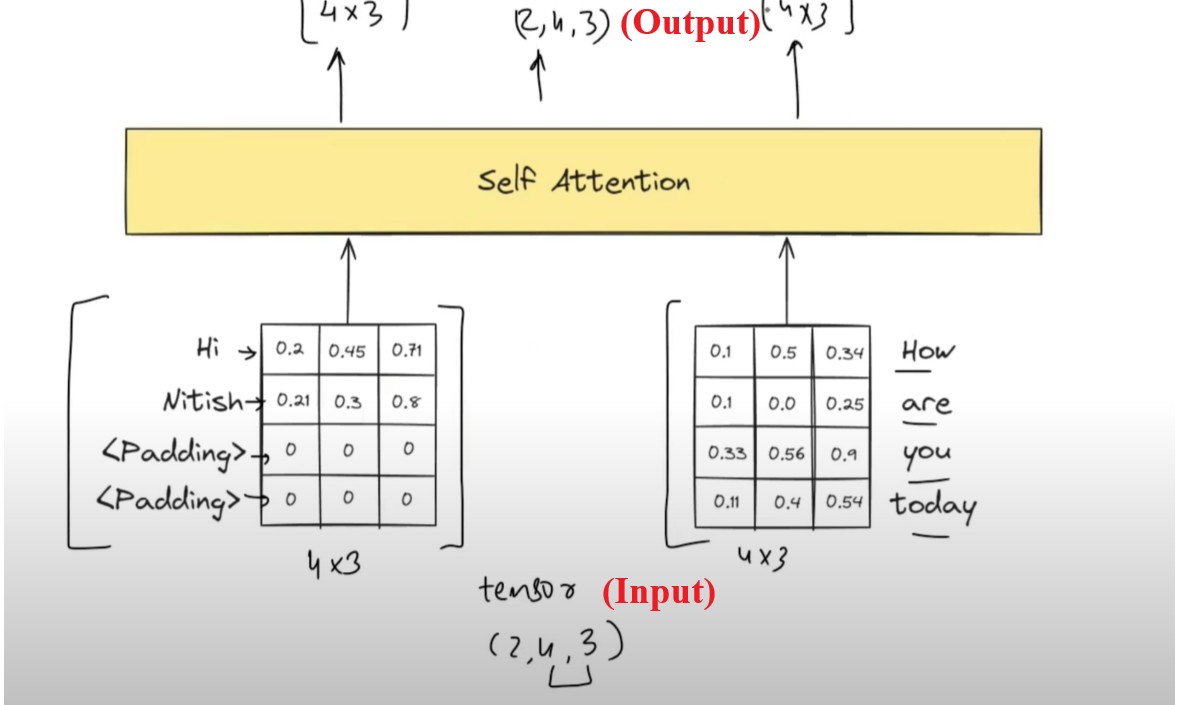
Now we will simplify it and convert it into a matrix format.
And it will be passed at the same time to my Self Attention model.
Individual matrix shape is 4*3 and we have 2 matrices.
We will combine and form it as a tensor of (2 ,4 , 3) and pass it as an input.
In output also we will receive (2 ,4 , 3) tensor vector.
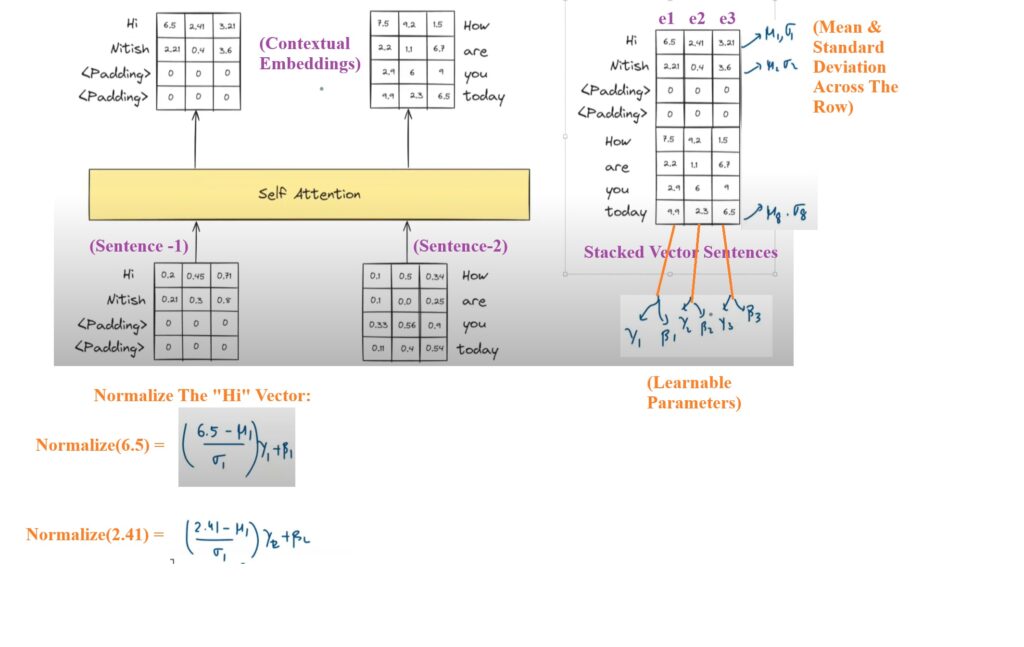
In the output you have contextual embedding of each word. for Hi = [0.2 0.45 0.71].
Since the output numbers are in different distribution of numbers.
we need to apply the normalization technique to it.
Lets apply the Batch Normalization to the output of the Self Attention model.
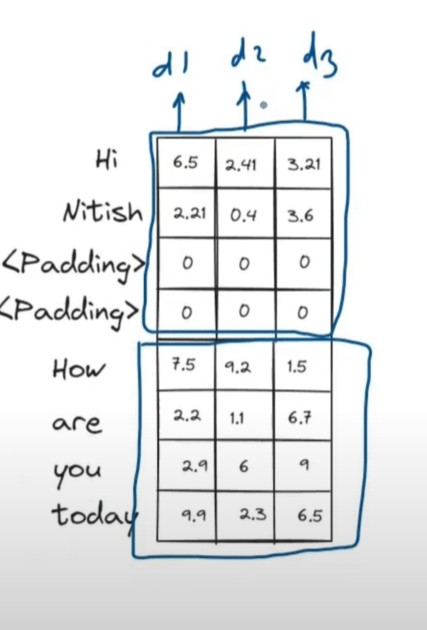
We will stack the two matrices one after another and apply the batch normalization to it.
We will have 3 different dimensions d1, d2 and d3.
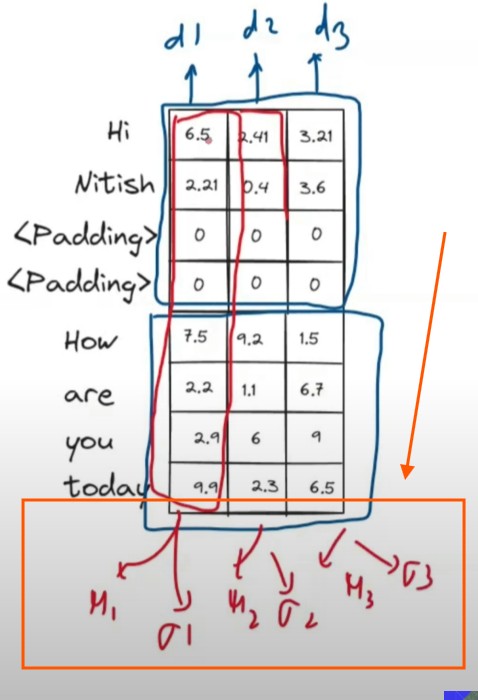
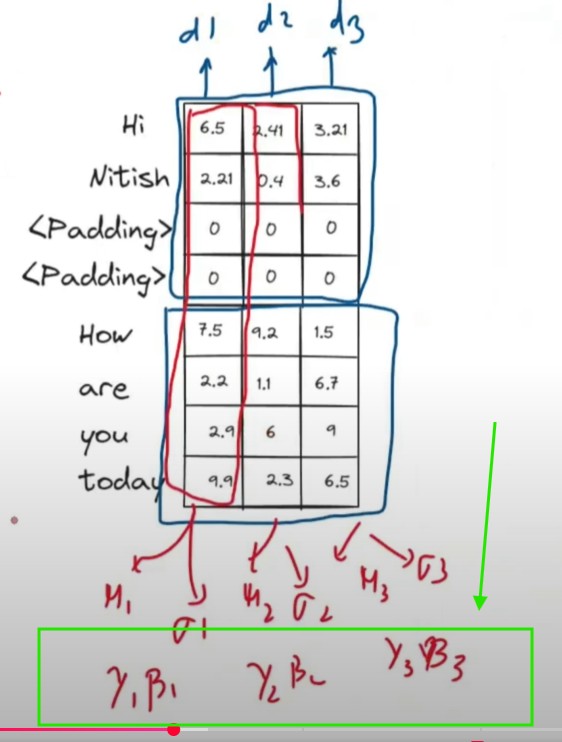
We will normalize in the column direction.
We will calculate the mean and variance of each dimension of the output vector.
We will also have the shifting and scaling learnable parameters of the individual dimension
Problem With Batch Normalization:
We have taken 2 sentences and the longsentence is having 4 words on it.
If my Batch Size = 32 and the long sentence is having 100 words in it AND OTHER SENTENCES IS HAVING 30 WORDS ON AN AVERAGE.
Now the Consequences will be there will be lot of zeros in the sentences having 30 words.
If you want to calculate the mean and standard deviation of a particular column you will see lot of zeros in that column hence the mean and standarddeviation will not be the true representation of that column.
Because we have added artificially zeros to that column to match the length of the input sentences.
Hence we can’t apply Batch Normalization to the matrix to normalize the values.
You can applyBatch Normalization easily to the normal tabular data but you can’t apply it in a sequential data.
(4) How Layer Normalization Solves The Problem Of Batch Normalization?
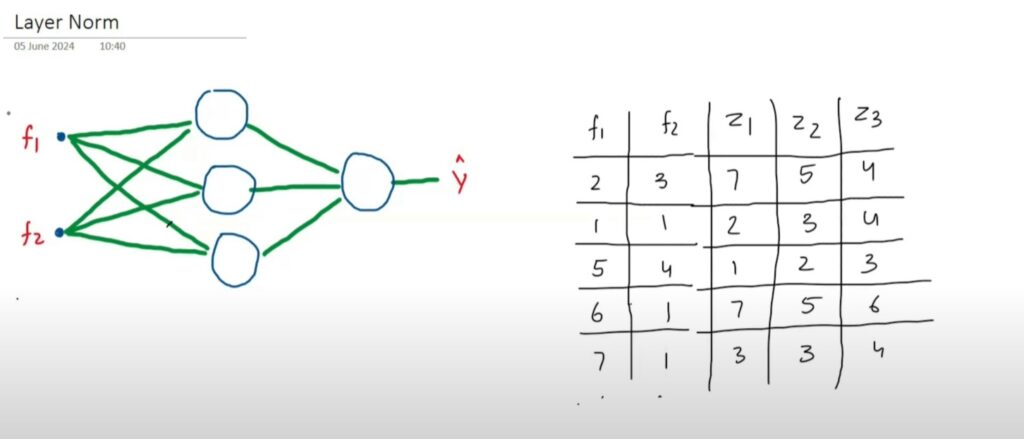
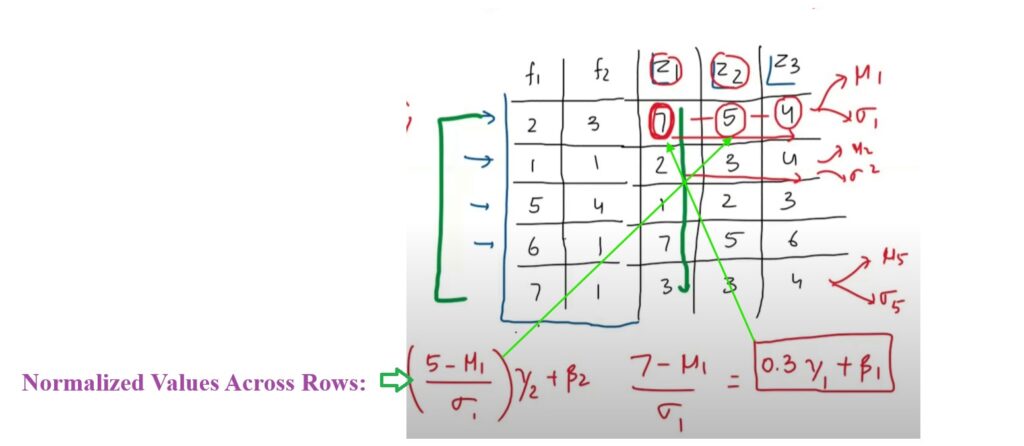
We will see how we can apply the Layer Normalization to the same input data and the (Z1, Z2, Z3 ) as an activation outputs from the first layer.
When you do a Batch Normalization you do normalization across the column direction but when you do Layer normalization you normalize across the row.
When you do a Batch Normalization you do normalization across the column direction but when you do Layer normalization you normalize across the row.
You will calculate the mean and standard deviation across row.
In first row (7 ,5 ,4) in second row we will calculate for (2, 3, 4) etc.
We will normalize each value across the row and will apply the learnable parametersbeta and gamma to each value.
Why it is more logical to apply Layer Normalization in Transformer lets explore.
Lets apply normalization to the self attention output embedding vector.
Here we will calculate the mean and standard deviation across row.
And the learnable parametersgamma and beta values will have for each embedding value.
Finally we will normalize individual values using mean and variance across that row and use the beta and gamma value.
What’s The Benefit We Got In Layered Normalization ?
When we do Layer Normalization across the rows it don’t have any effect of zerospresent in the other rows because we are normalizing across the row.
Hence the Normalization process will be effective and accurate as compared to the Batch Normalization.