
Transformer – Masked Self Attention
Table Of Contents:
- Transformer Decoder Definition.
- What Is Autoregressive Model?
- Lets Prove The Transformer Decoder Definition.
- How To Implement The Parallel Processing Logic While Training The Transformer Decoder?
- Implementing Masked Self Attention.
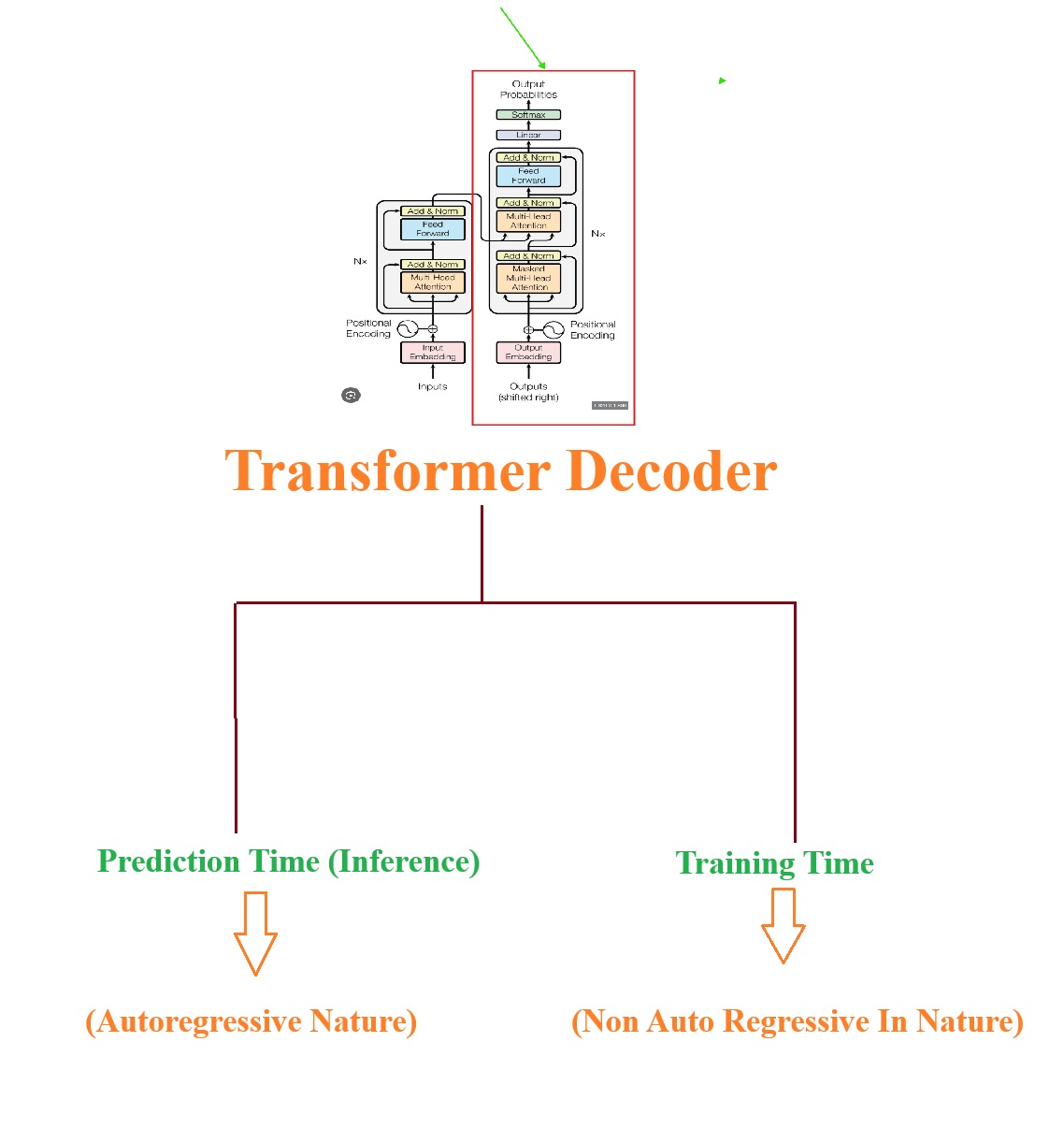
(1) Transformer Decoder Definition

- From this above definition we can we can understand that the Transformer behaves Autoregressive while prediction and Non Auto Regressive while training.
- This is displayed in the diagram below.
(2) What Is Autoregressive Model?

- Suppose you are making a Machine Learning model which work is predict the stock price,

- Monday it has predicted 29, Tuesday = 25 for to predict for Wednesday it has to consider previously predicted stock price and predict the todays price.
- You have already seen the Autoregressive model in the Deep learning. Let us understand this where you have seen it.
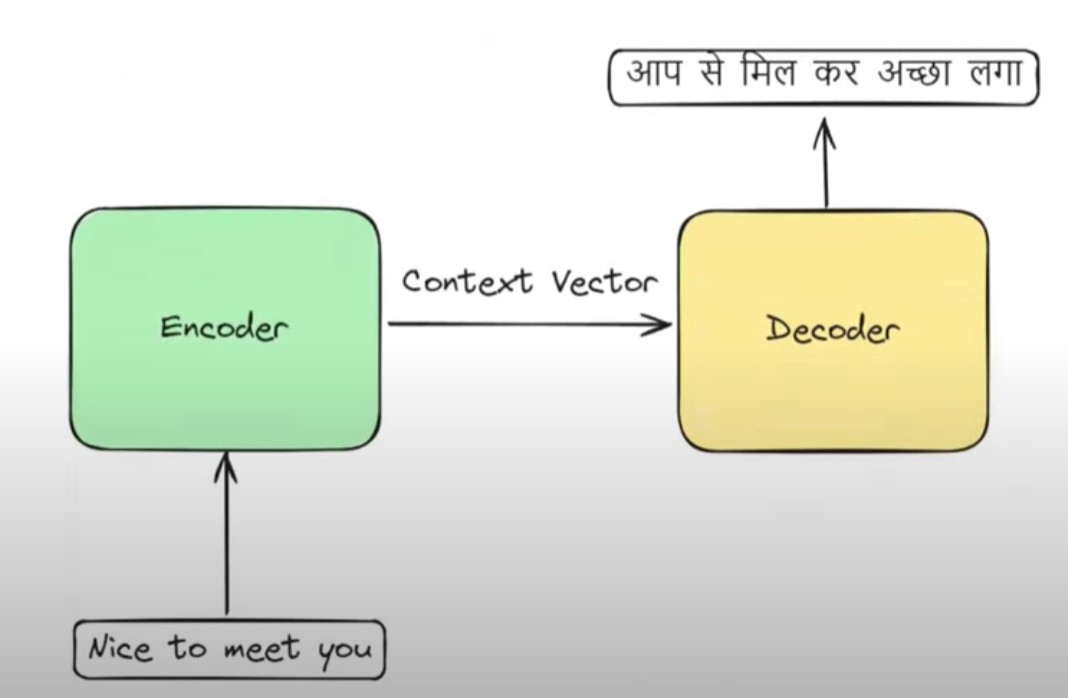
- This is simple Encoder and Decoder architecture.
- Where we are using LSTMs in the encoder and also in the decoder.
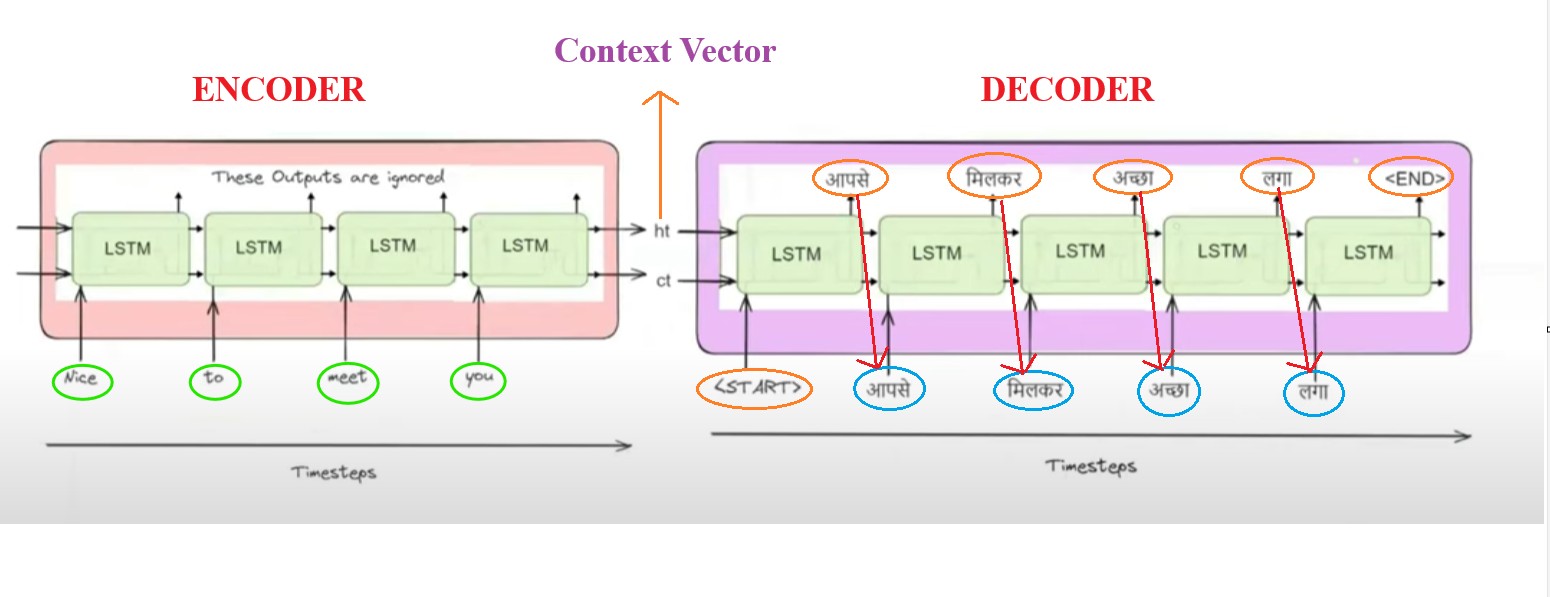
Encoder Side:
- We have 2 parts here 1st one is the Encoder and the 2nd Part is the Decoder.
- In the Encoder we are sending one word at a time ,At first time step we are sending ‘Nice’, 2nd time step we are sending ‘To’, 3rd timestep ‘Meet’ and in 4th timestep ‘you’.
- As this is a sequential model we have to send one word at a time but the Transformer is parallel model where at a time it will process 4 words.
Decoder Side:
- In the Decoder side at 1st timestep it takes the ‘Context Vector’ and the <START> word as input, then it will generate ‘Appse’ as an output.
- In the 2nd time step we send ‘Context Vector’ and ‘Appse’ as an input and it will generate ‘Milkar’ as an output.
- In the 3rd timestep we send the ‘Context Vector’ and ‘Milkar’ as an input and it will generate ‘Ache’ as an output.
- This is how it will continue.
- Here you can notice that to predict the current value it is taking the help of previous predicted values.
- Hence it is behaving like an Autoregressive model.
- All these sequential models like RNN, LSTM, GRUS are Autoregressive models.
Question: Why The Models Can’t Predict All Words At A Time ?
- Why the sequential models are Autoregressive in nature why it can’t predict all the words at a time?
- You can’t predict every words at a single time because the current word depends on the previously generated words.
- You can’t generate the current words without knowing the previously generated words.
- You need the information of the previously generated words to predict the next word.
- This is the fundamental aspect of the sequential model that the next value always depend on the previously generated values.
Question: Why In Transformers the Decoder Is Autoregressive At Prediction Time And Non-Auto Regressive At Training Time?
- The reason behind this behavior is Masked Self Attention.
(3) Lets Prove The Transformer Decoder Definition.
- To prove this we will assume the opposite first, The Decoder is Auto Regressive while Prediction and also in Training.
- Let us prove this with one example.
Transformer Prediction:
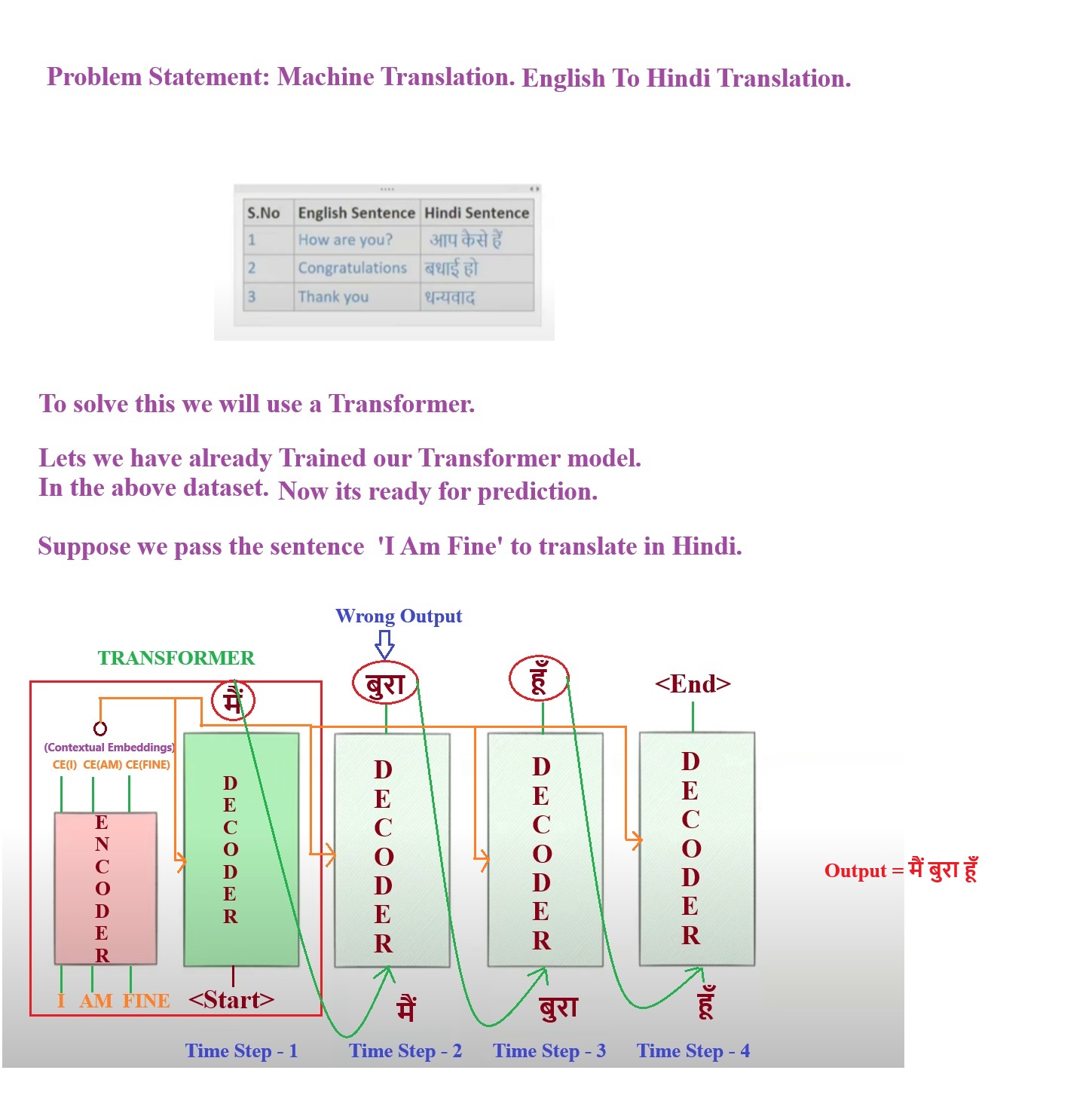
- In the Encoder we will pass “I AM FINE” as input parallelly. And as an output we will get the positional contextual word embedding vectors.
- This Contextual Word embedding vector we will pass as an input to the Decoder at every timestep.
- At 1st timestep we will pass the Contextual Embedding vector and the <Start> keyword and we got ‘मैं’ as an output.
- At 2nd timestep we pass ‘मैं’ and the Contextual embedding as input and we got ‘बुरा’ as an output which is wrong and can be corrected while training.
- Like this we will do till we got <end> as an output.
Transformer Training:
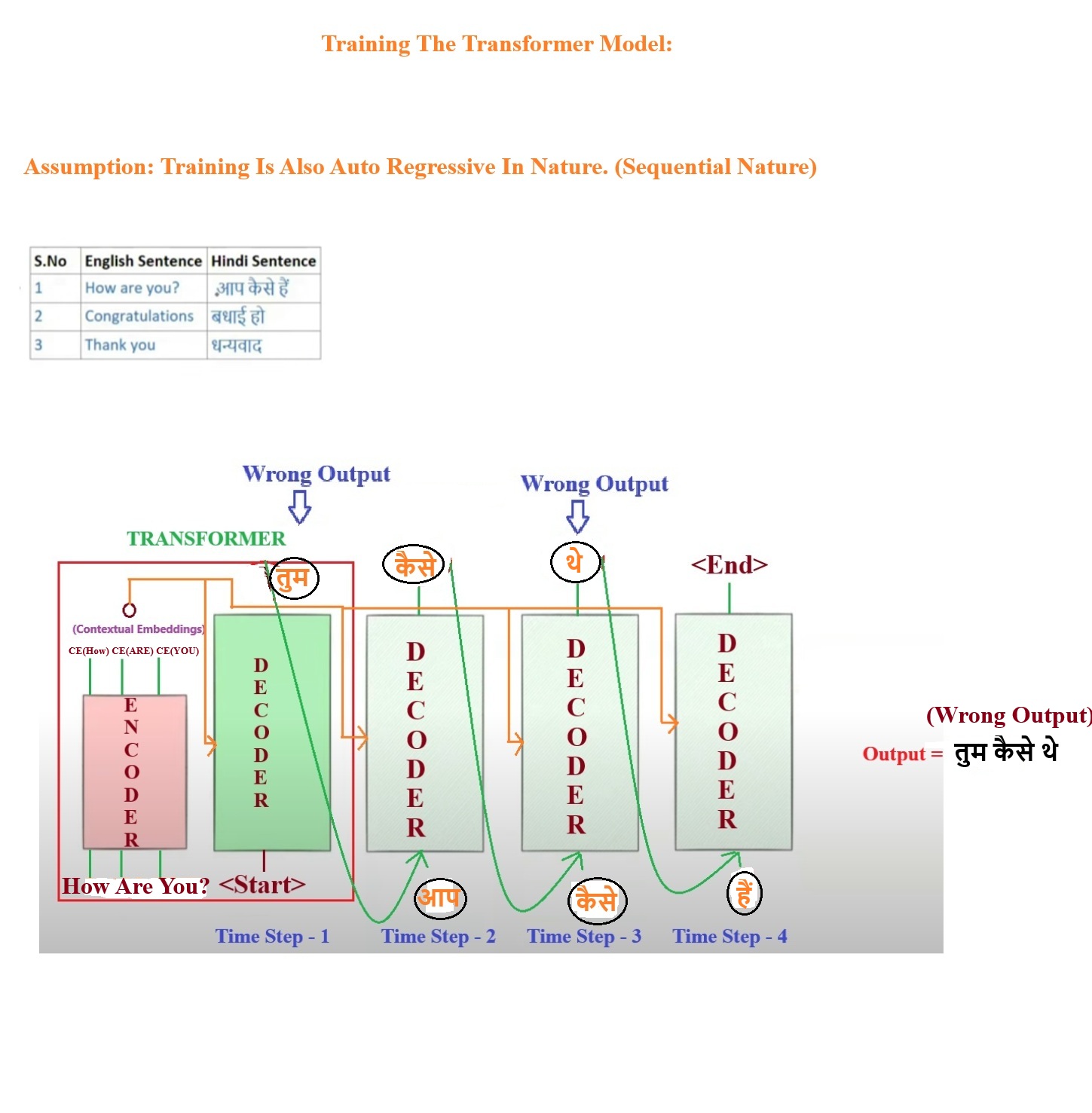
- Now we will train our model with the input dataset.
- First we will pass “How Are You” as an input to the Encoder and it will generate a Contextual Vector.
- This Contextual Vectors we will pass as in input to the Decoder for every time step.
- At 1st time step we pass <Start> as an input to the Decoder and it has produces ‘तुम’ as an output which is wrong.
- At 2nd timestep we send the Contextual Vector and the correct word ‘आप’ as an input to the Decoder, this is called teacher forcing where we will pass correct word as an input to the Decoder while training. The output will be ‘कैसे’ which is correct.
- At 3rd time step we pass ‘कैसे’ as an input and got ‘थे’ as an output which is wrong.
- At 4th time step we pass ‘हैं’ as an input which is the correct input and got <End> as an output.
- Here we have seen that we are using Teacher Forcing means if the student is giving incorrect answer then also we are teaching him the correct answer by passing the correct input.
Important Points:
- Will there be any problem if we make the training process Auto Regressive in nature ?
- There is a big problem have been introduced while making the training process auto regressive.
- If we make our training process Auto Regressive the training will be too much slower.
- To process a single sentence “How Are You?” you have run the Decoder processed 4 times , imagine if you have 1000 word sentences or an entire book to process you need to run your decoder millions of time.
- Hence the training process will be slower if we use auto regressive approach while training.
- Is it compulsory to go sequential processing while doing training ?, the answer is Yes/No.
- But it is compulsory to do sequential processing while doing prediction. In prediction we don’t have any option of without knowing the previous prediction we will not know the current prediction.
- Hence at the time of prediction it is compulsory to process our data sequentially we don’t have any alternative for it.
- But we have an alternative way of processing the data while doing training with the Decoder.
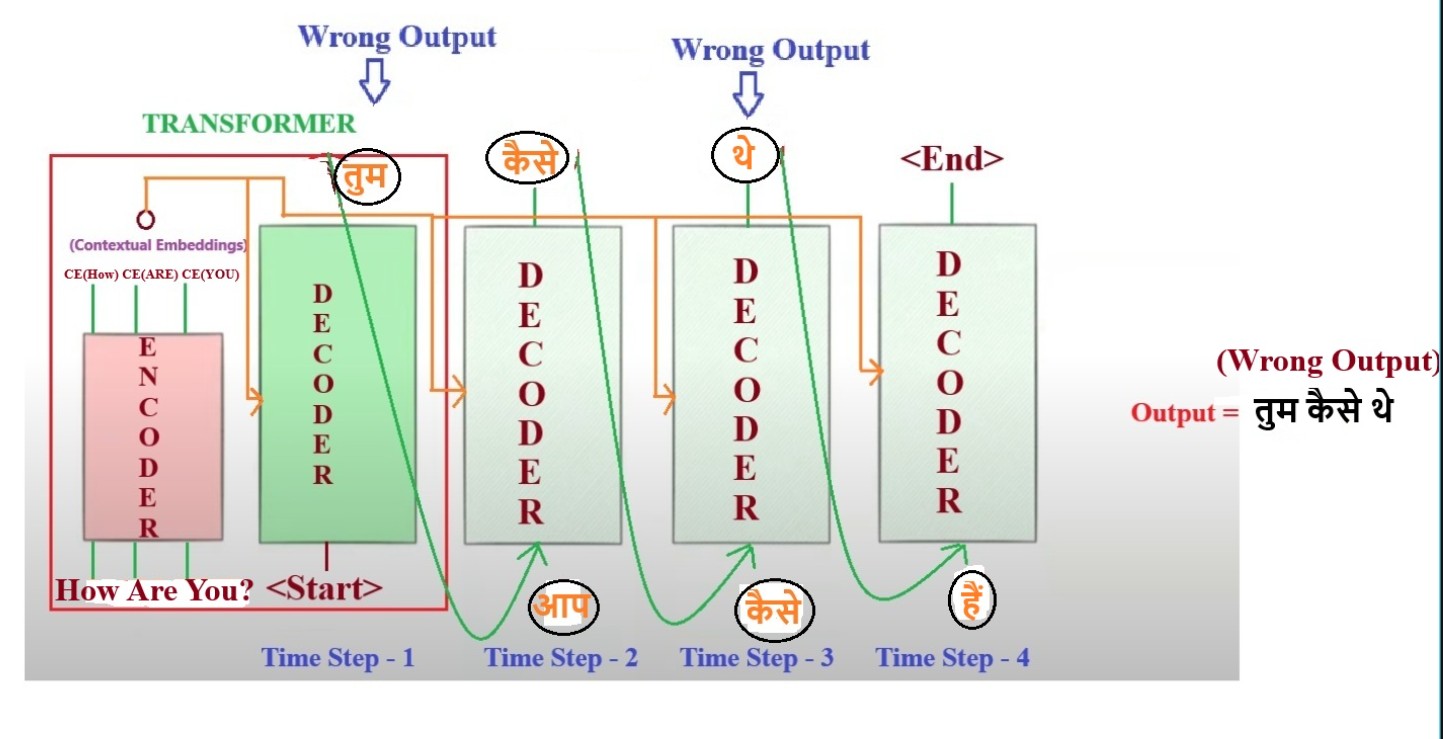
- The above diagram represent the training process of the Transformer.
- Here we can see that whatever may be the Transformer output may be while giving the input we are only sending the correct input to the Decoder.
- In out above example we are getting wrong output while for 1st and 3rd timestep but we are passing the correct input to the Decoder at every time step while training.
- So in training we have a advantage of having all the training dataset available with us we don’t have to depend on the Decoder prediction output to pass it to the next step.
- But while prediction we don’t know the future words to come at 1st timestep, hence we have to go sequentially while prediction.
Important Notes:
- At the time of training we don’t have to process the data sequentially because we don’t have the dependency on the Decoder prediction at each time step, we already have the data to process for every time step while training the Transformer model.
- Due to this parallel processing the training process will get super faster.
(4) How To Implement The Parallel Processing Logic While Training The Transformer Decoder?
- This is not quite easy to implement the parallel processing in the decoder module while training.
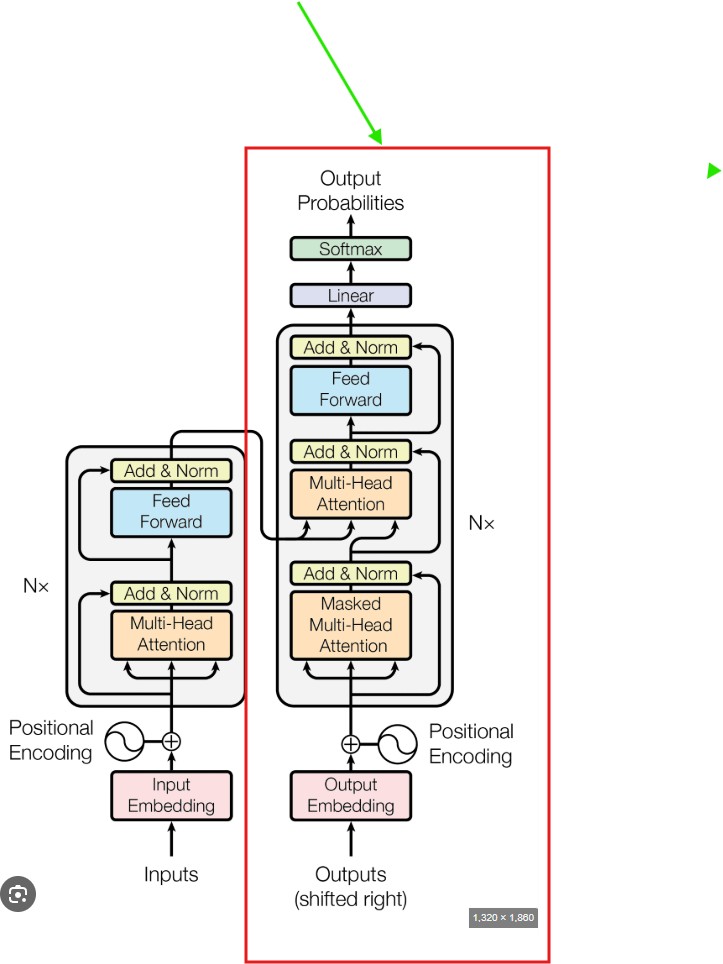
- Let us understand the Decoder working principle first to solve this problem.
- The first part is the Masked Multi Headed Attention model.
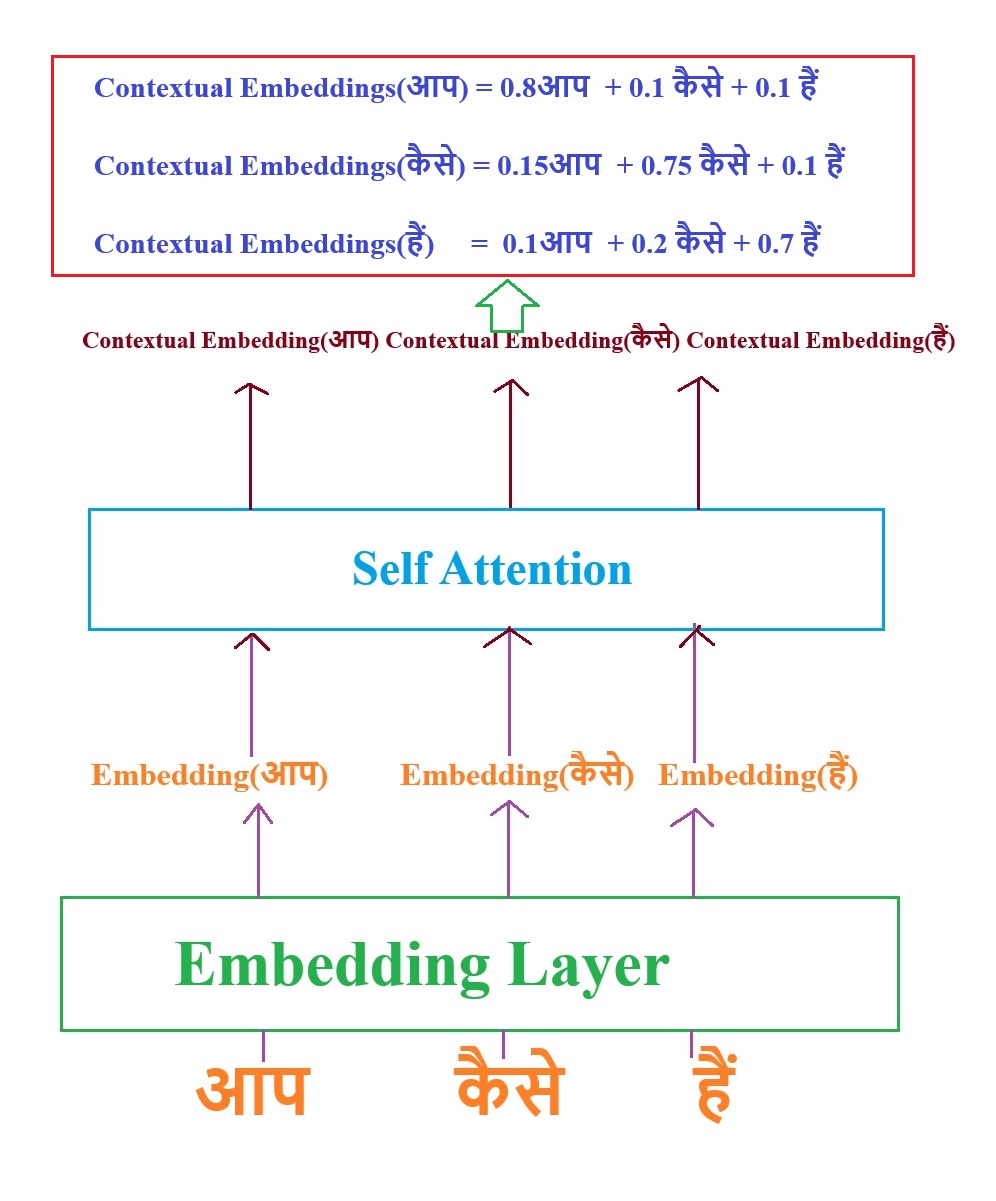
- Lets train the model with the sentence, आप कैसे हैं.
- To send this words as an input we need to convert the words into embedding vectors.
- Hence we have passed the words into the embedding layer. this embedding layer will generate the embeddings without any contextual awareness.
- Hence we need to pass it to the Self Attention model to generate the contextual embeddings of the words.
The Big Mistake:

- From the equation above you can see that to get the current contextual embedding value you are referring to the future embedding values.
- For example at time step 1 you have only ‘आप’, while generating the contextual embedding of the word ‘आप ‘ you are using the future word embedding which are “कैसे” and “हैं”.
- The big problem here is to generate the current token value you are using the future token values. Which is unfair.
- At training time you can do this because you already have the dataset with you, but while prediction you can not do this because you will not have future prediction at a given time step.
- Hence at prediction we can’t derive the contextual embedding values for each word and can’t solve the mathematical equation above.
- This approach is wrong, in Machine Learning you can’t do anything like , one thing you can do it in training but cant do it in prediction.
- Basically you are doing cheating with your model while training you are showing everything correct but while prediction you don’t have those values to predict the next word correctly.
- This is the example of data leakage. Which is, at the training time your model is having some extra information, which you will not have at the time of prediction.
- Problem Is: Your current tokens can able to see the future tokens which you will not get at the time of prediction.
Solution To The Data Leakage:
- You would not have faced the Data Leakage problem if you would have trained your model sequentially.
- In sequential training process you will not be knowing the future values upfront.
- For example for the sentence “आप कैसे हैं “, at first timestep when you have only ‘आप’ you do all the calculations based on “आप” only.
- At 2nd timestep when you have “आप कैसे” you do calculations using this two words only.
- Like this you do calculate the contextual embedding values.
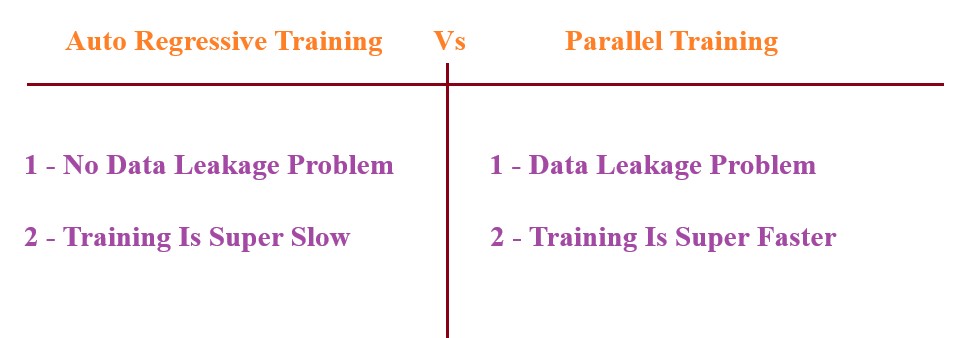
- If i am doing sequential training i am facing the problem and also if we are training the model parallelly i am also facing the problem.
- Is there any smarter way that i can able to solve this issue.
- To solve this you have to understand the How question of self attention because the answer is hidden inside it.
(5) Implementing Masked Self Attention.
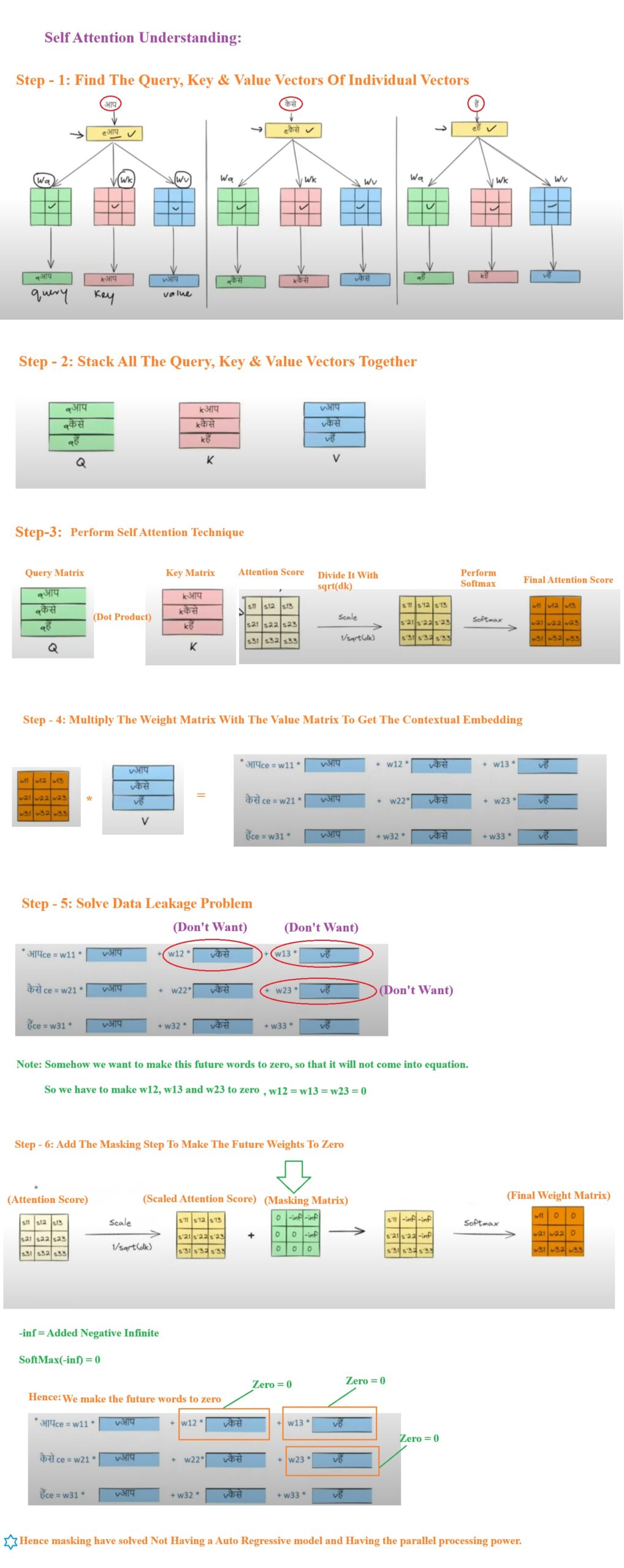
- Step-1: We calculate the Query, Key and Value vectors of the individual word embedding vectors.
- Step-2: Stack all the Query, Key and Value vectors to form a matrix.
- Step-3: Perform the self attention mechanism on the query and key matrix to get the weight matrix.
- Step-4: Multiply the weight matrix with the Value matrix to get the contextual embedding vectors.
- Step-5: To solve the data leakage problem while training we dont want to show the future words to the mode, hence some how we will make the future tokens to zero.
- Step-6: To make the future tokens to zero we introduced the masking matrix at step no3.
- Step-7: The masked matrix will have the -infinite as a value in the position where you want to make your value to zero.
- Step-8: We will sum the masked matrix with the scaled attention scored matrix, s12 + (-inf) = 0.
- Step-9: We passed the summed matrix to the softmax function. and Softmax(-inf) = 0.
- Step-10: Finally we got the weight matrix with 0 as value at position where the future tokens are present.
- Step-11: This is how we have introduced the Not Having A Auto Regressive Model & Having A Parallel Processing power.