
Transformer – Cross Attention
Table Of Contents:
- Where Is Cross Attention Block Is Applied In Transformers?
- What Is Cross Attention ?
- How Cross Attention Works?
- Where We Use Cross Attention Mechanism.
(1) Where Is Cross Attention Block Is Applied In Transformers?

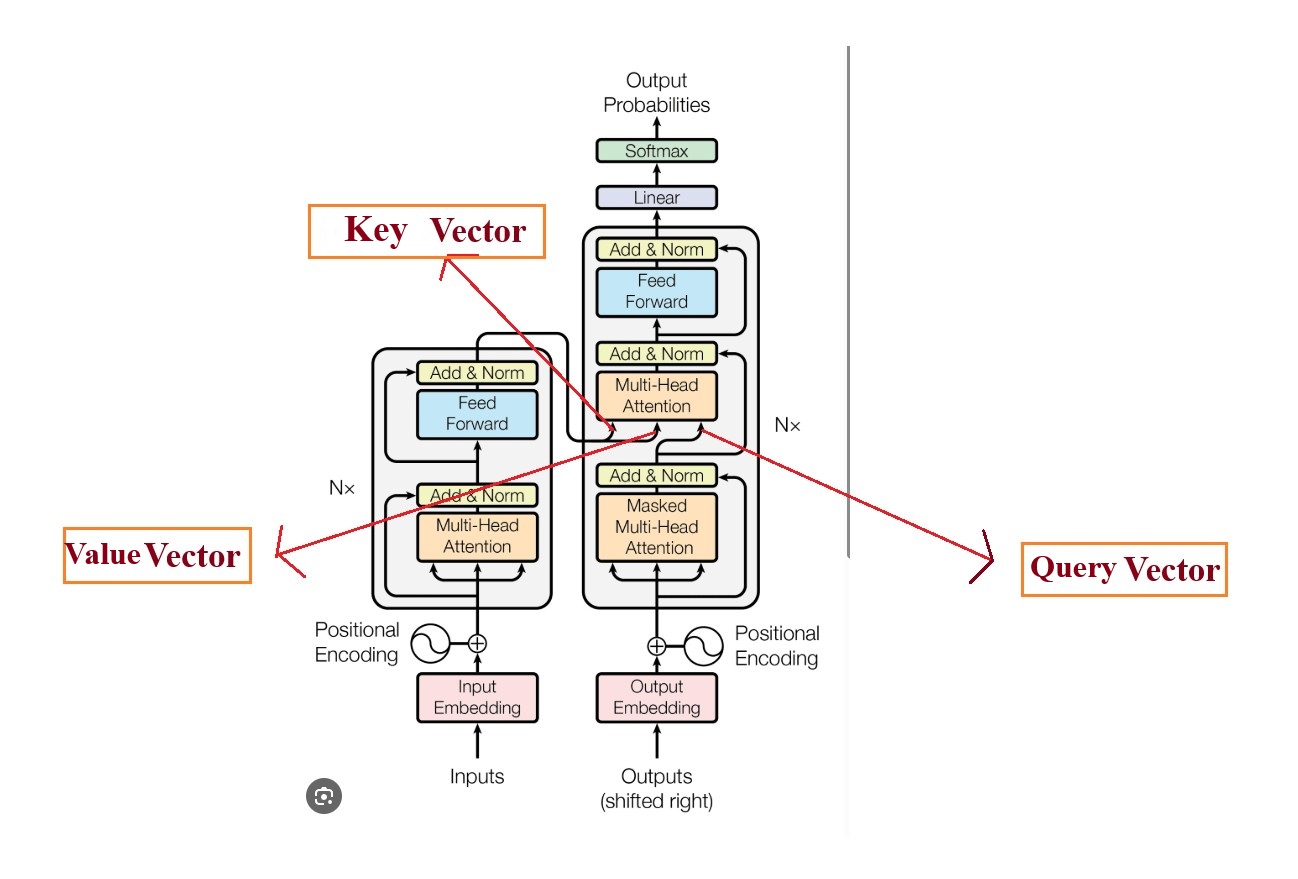
- In the diagram above you can see that, the Multi-Head Attention is known as “Cross Attention”.
- The difference to the other “Multi Head Attention” block is that for other the 3 inputs Query, Key and Value vectors are generated from a single source but in this Cross Attention block the Query vector is coming from the Decoder block and the Key and Value vectors are coming from the Encoder block.
(2) What Is Cross Attention ?


- Step-1: We will take an example of English to Hindi translation.
- Step-2: We will use encoder and decoder architecture to solve the machine translation problem.
- Step-3: Sentence = “I Like Eating Ice-cream”, WE WILL PASS THIS SENTENCE AS AN INPUT TO THE DECODER, Decoder will do parallel processing and will generate a Contextual Vector.
- Step-4: At Decoder side at timestep-1 we will receive the contextual vector from encoder and will generate “मुझे” as an output. At timestep-2 we will generate “आइसक्रीम” as an output.
- Step-5: Now the question here is what will be the output at time step -3?
- Step-6: The output at time step 3 depends on the previously generated words which are “मुझे” and “आइसक्रीम” and also with the original input sentence.
- Step-7: The first dependency can be derived using the Self Attention mechanism because it is finding relationship between the same sentence.
- Step-8: To determine the 2nd relationship which is the relationship between the output words and the input words we have to use “Cross Attention” mechanism.
(3) How Cross Attention Works?

- Cross Attention is conceptually very much similar to Self Attention mechanism.
- The difference is in The Input, The Processing and The Output.
- Let us understand first how the input is going to the Self Attention block and the Cross Attention block.
(1) Input Aspect:
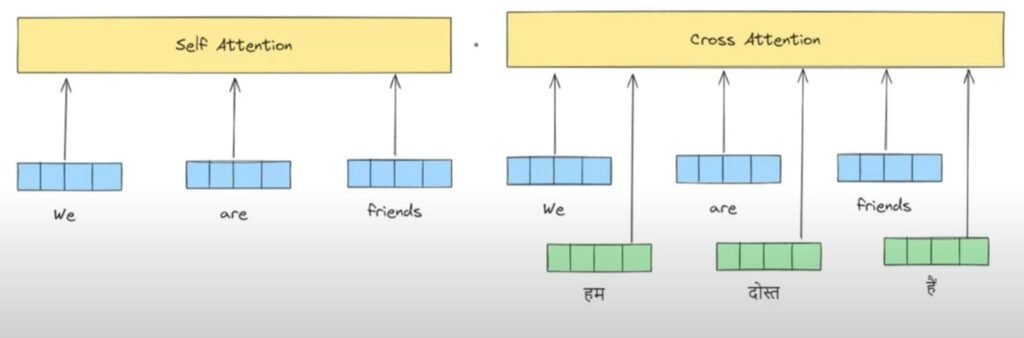
- Self Attention Input: Input to the self attention model will be the individual word embedding vectors. In our example we have to give embeddings of “We”, “Are” , “Friends”. It accepts only one set of input sequence and tries to find out the relationship between them.
- Cross Attention Input: The input to the Cross Attention will be the two sequence one is from the input which is here “We”, “Are” , “Friends” and another one is “हम”, “दोस्त”, “हैं”.Cross Attention tries to find out the relationship between the input and the output sequence. Hence the name is Cross Attention.
(2) Processing Inside Self Attention & Cross Attention.
Self Attention Working Principle.
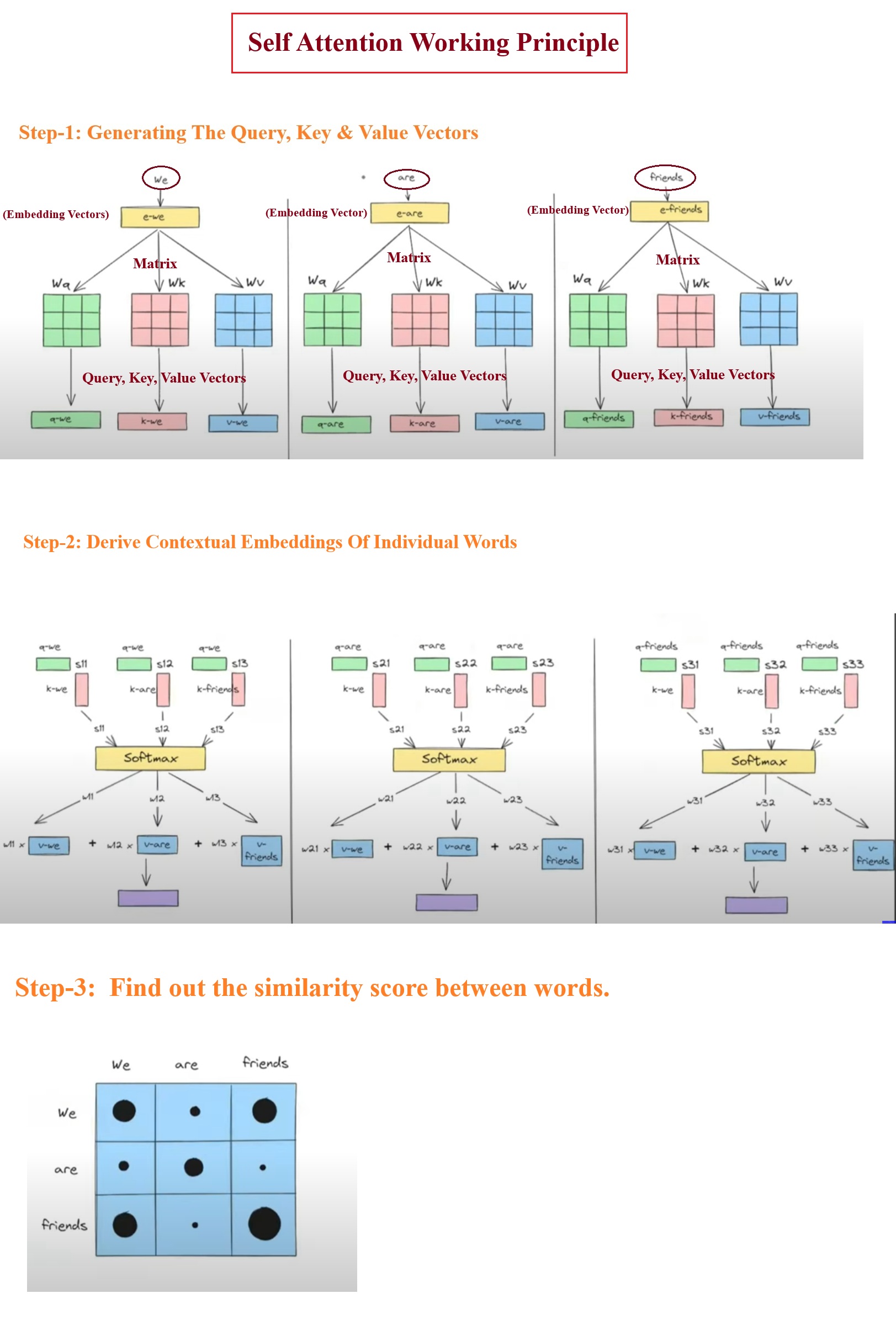
- Let us understand the working principle of the Self Attention Mechanism.
- Step-1: We will generate the Query, Key and Value vectors from the individual word embedding vectors.
- Step-2: We will derive the Contextual Embedding of the Individual words.
- Step-3: We will find out the similarity score between words.
Cross Attention Working Principle.
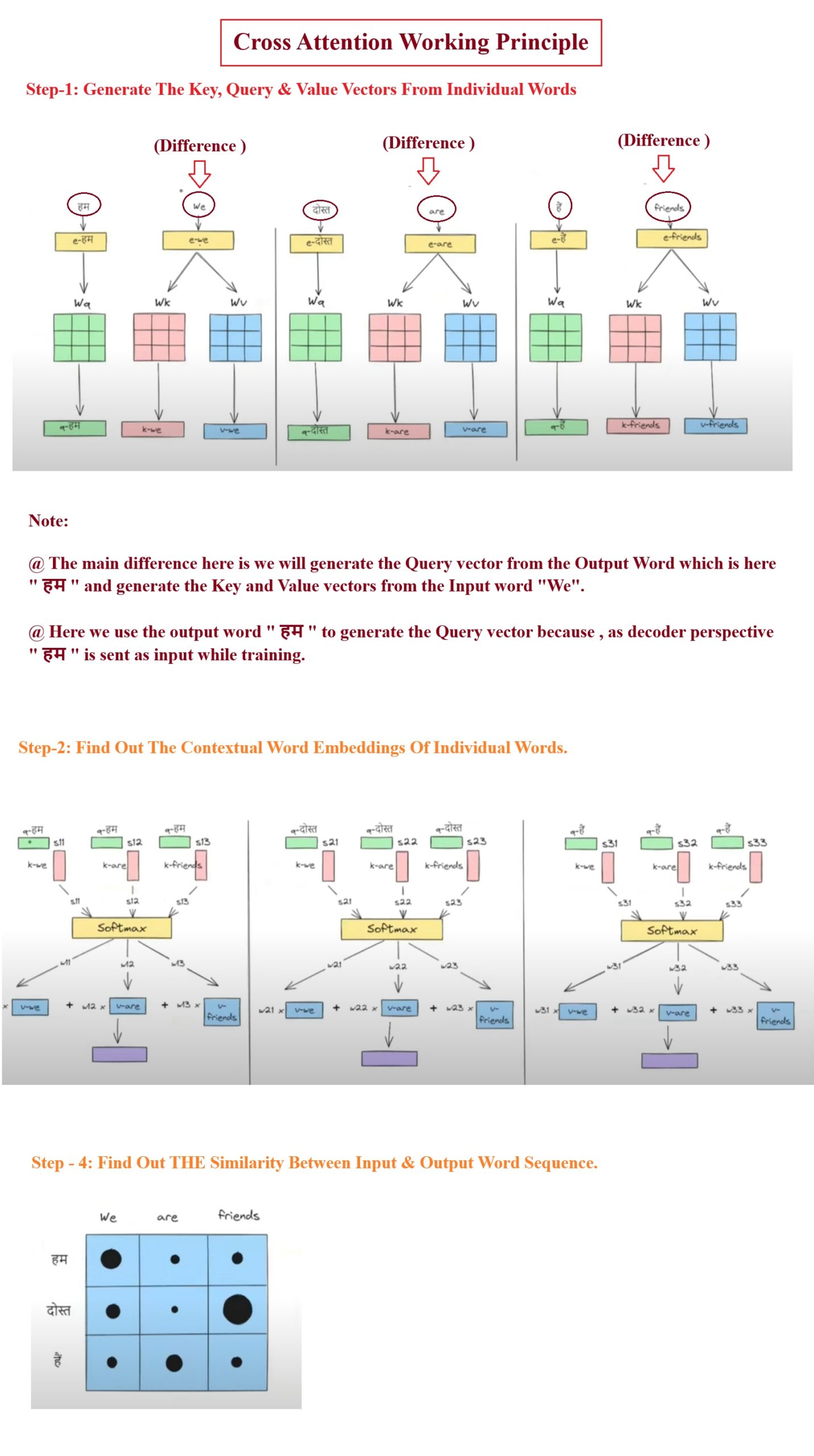
Input Query, Key & Value Vector To Cross Attention Model.
Difference Between Self Attention And Cross Attention.
- The main difference between the Self Attention and the Cross Attention module is that in Cross Attention to generate the Query, Key and Value vector we use different words.
- To generate Query vector we use the output word “हम“.
- To generate the Key and Value vector we use the input word “We”.
- Like this way we can able to find out the relationship between the input and output word sequence.
- After that all the processing will be same as we are doing it in self attention
- From the above Transformer diagram you can see that the Key and Value vectors are coming from the encoder part and the Query vector is coming from the decoder part.
(3) Output Aspect Of Self & Cross Attention
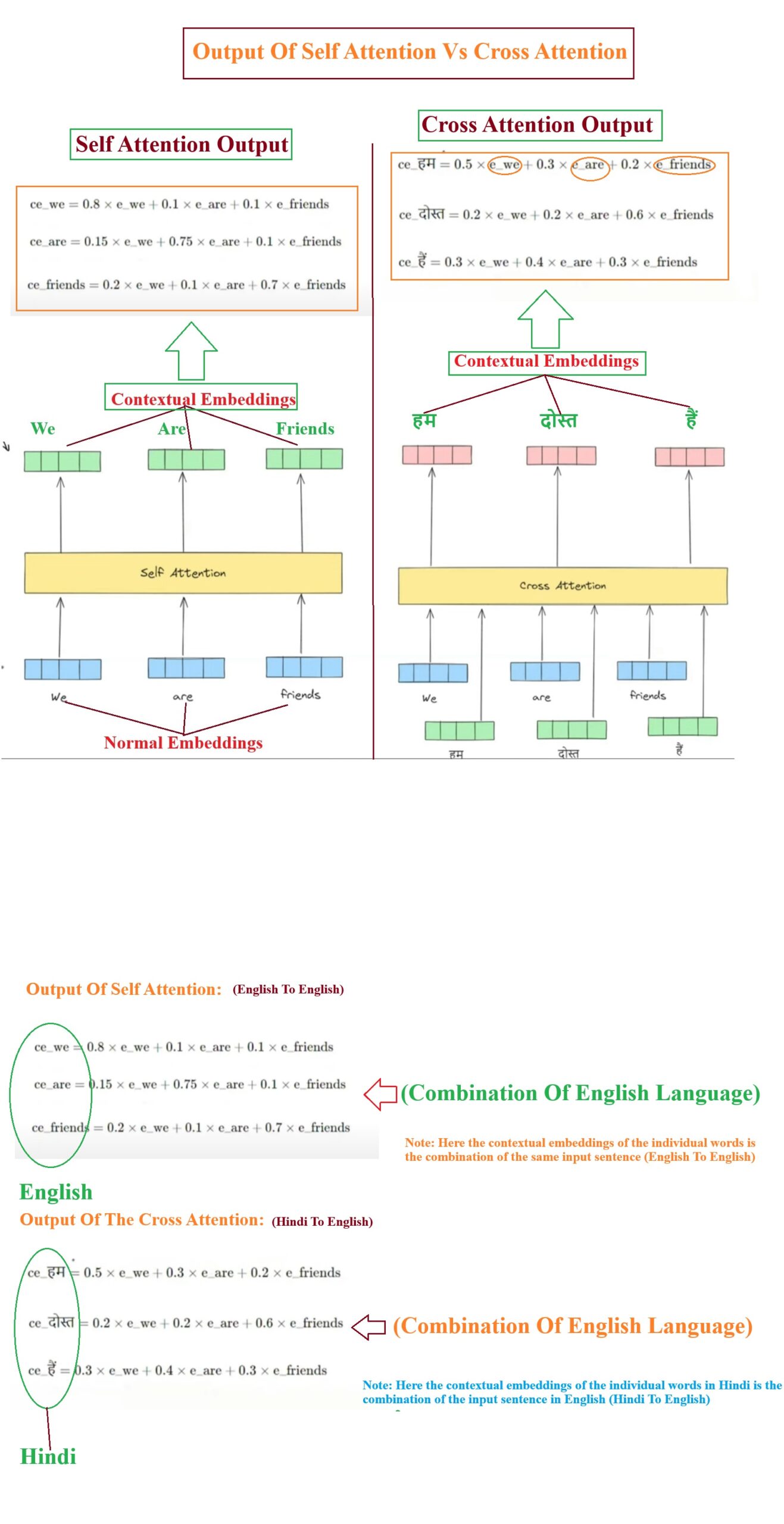
- In case of Self Attention we are passing input as English sentence “We Are Friends” and we will get the contextual word embedding vectors of individual words.
- In case of Cross Attention we are passing both the input and output sentences to the model as an input and we will get the contextual word embeddings of the output sentence which is “हम दोस्त हैं“.
- In Cross Attention model the output contextual word embeddings for Hindi language will be the sum of embeddings of the English language.
(4) Where We Use Cross Attention Mechanism.
- Cross Attention is used to find out the Similarity score between two different inputs.
- For example Image to text, text to image text to speech etc.