How Controlling The Magnitude Of The Model’s Coefficients, Overcome Overfitting ?
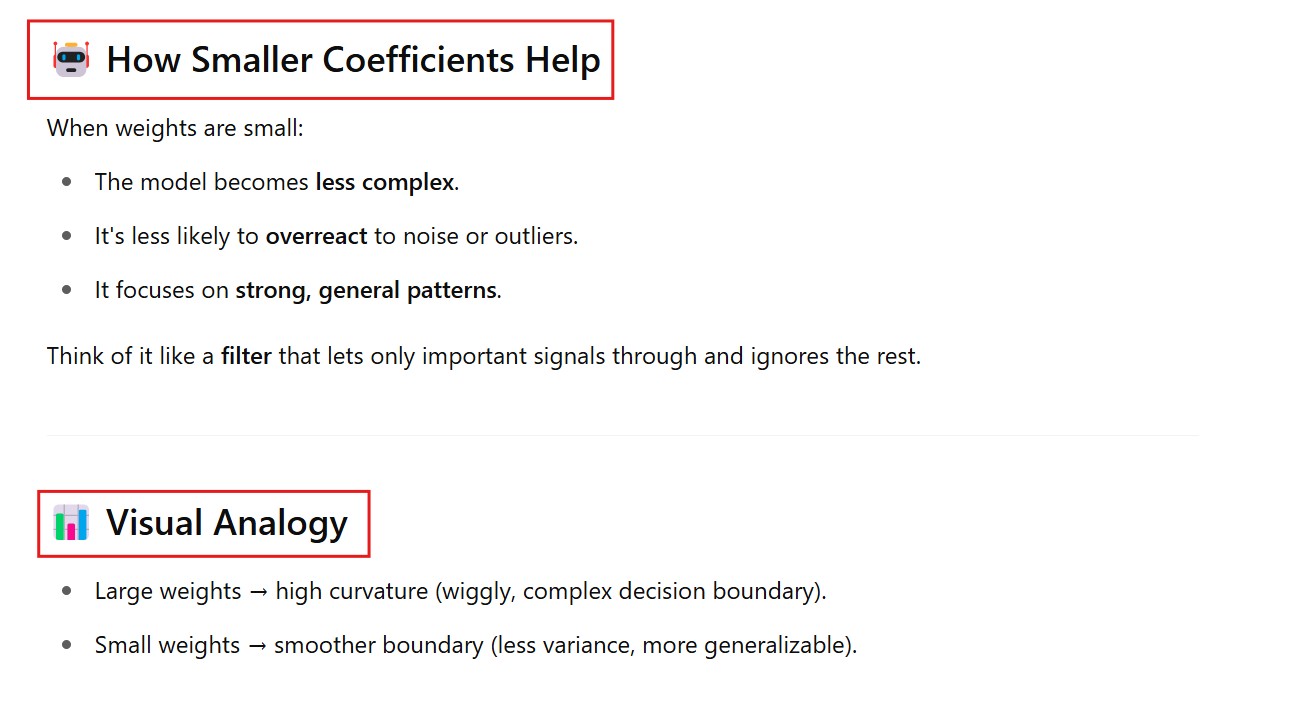
How Too Large Coefficients More Likely To Fit Random Noise In The Training Set ?
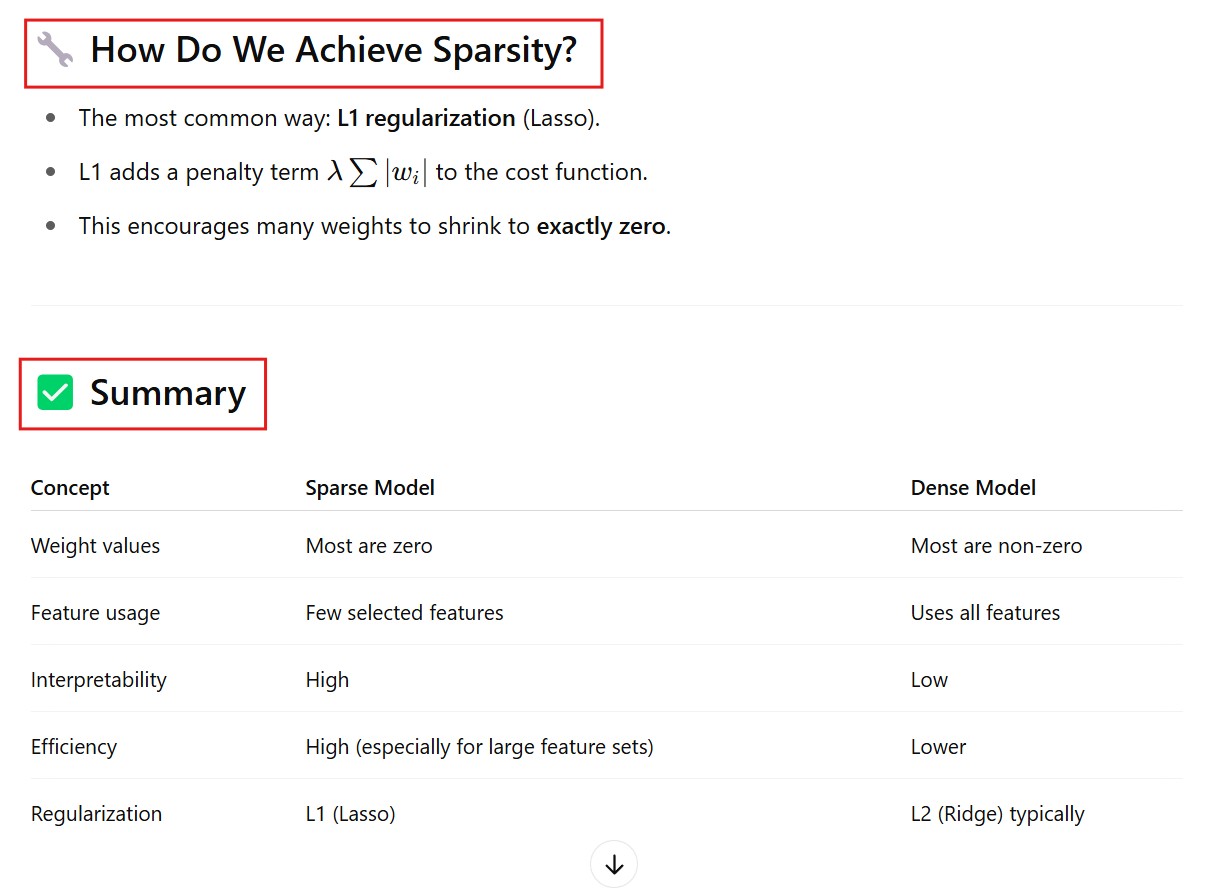
What Is Sparsity In The Model ?
How The L2 Regularization Handle The Larger Weights ?
Explain With Mathematical Example How The Weights Are Getting Zero In L1 Normalization ?
Why For L2 Regularization Weight Can’t Be Zero Explain With One Example ?
(1) What Is L1 & L2 Regularization ?
(2) How Controlling The Magnitude Of The Model’s Coefficients, Overcome Overfitting ?
(3) How Too Large Coefficients More Likely To Fit Random Noise In The Training Set?
(4) What Is Sparsity In The Model ?
(5) How The L2 Regularization Handle The Larger Weights ?
How L2 Shrunk The Weights?
As you can see in the above equation is that, as the weights reduction is directly depends on the weight itself, if it is a bigger weight it will be reduced in bigger way, if it is a smaller weight it will be reduced in a smaller way.
(6) Explain With Mathematical Example How The Weights Are Getting Zero In L1 Normalization ?
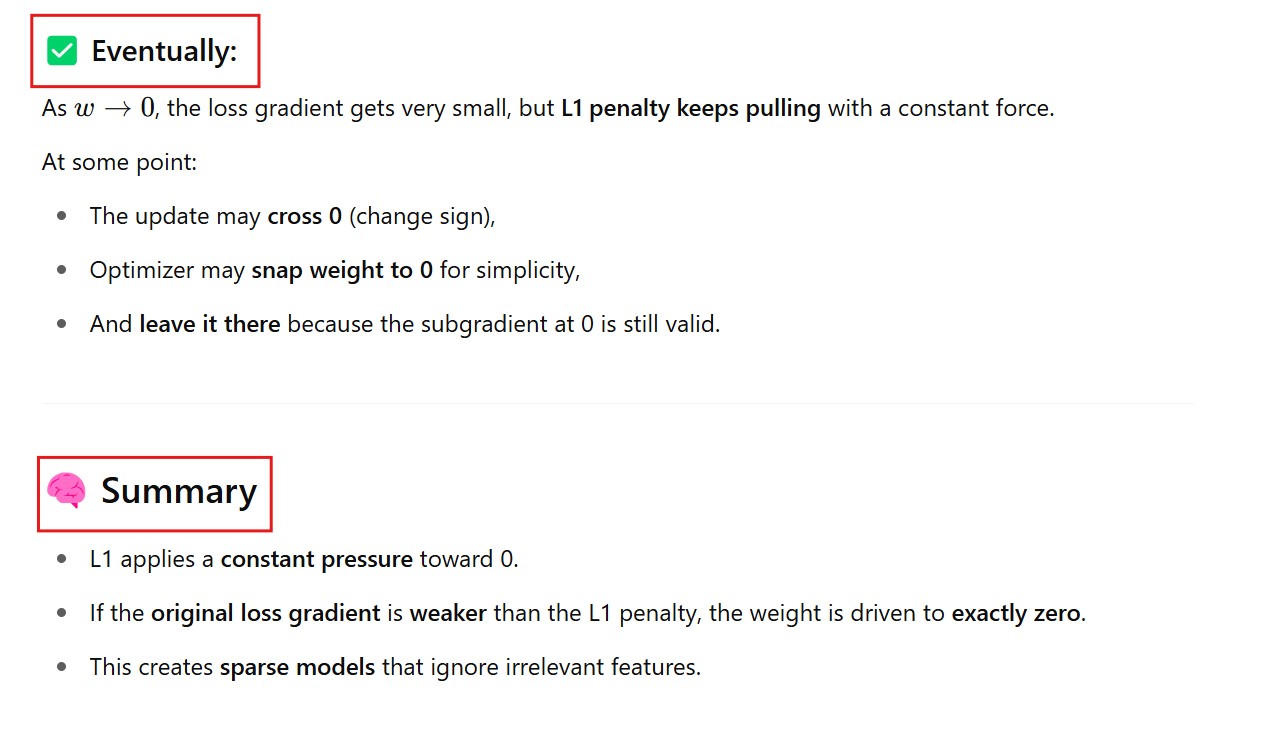
At w = 0 , the optimizer stops updating the weights, because it fluctuates between small positive and negative value around the weights.
Hence it will take the step to keep the weight at zero and stop changing it again.
(7) Why For L2 Regularization Weight Can’t Be Zero Explain With One Example ?
From the weight update equation we can see that the new weight will never become zero for w = 0.
because w(new) = w(old) – learning rate * Gradient Loss.
There will be still w(old) present when the Gradient Loss (2 * Lambda * w) can be zero.