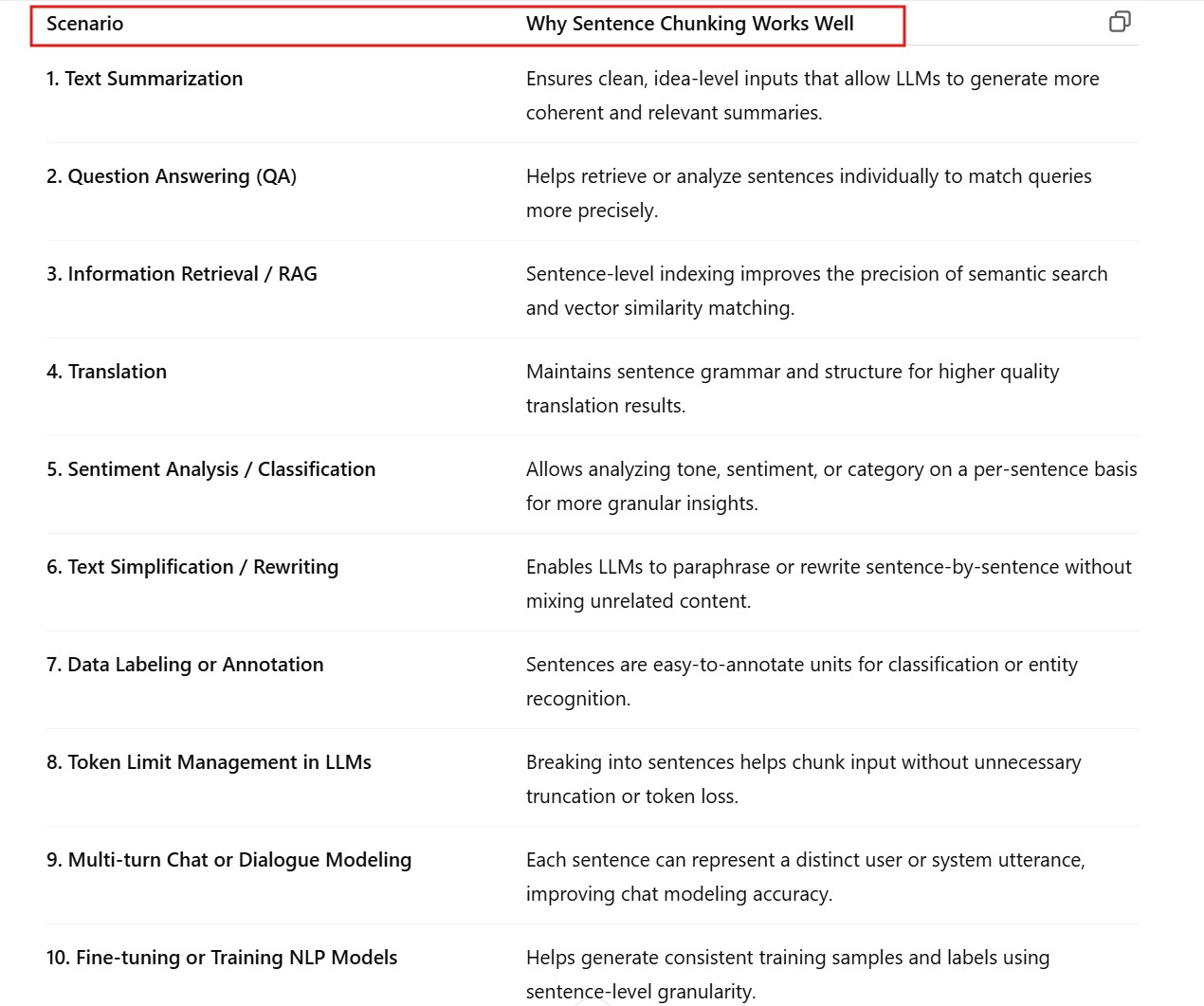
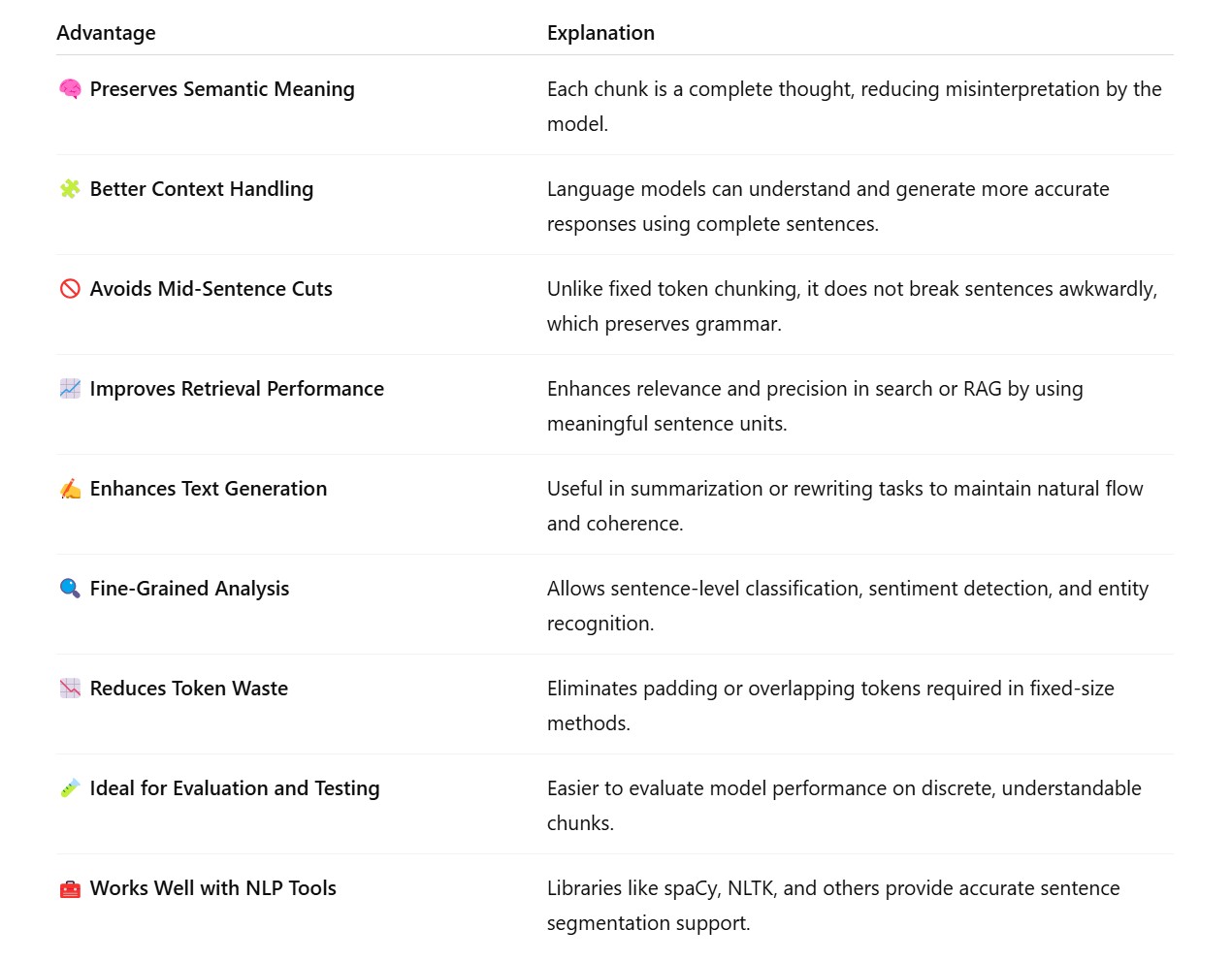
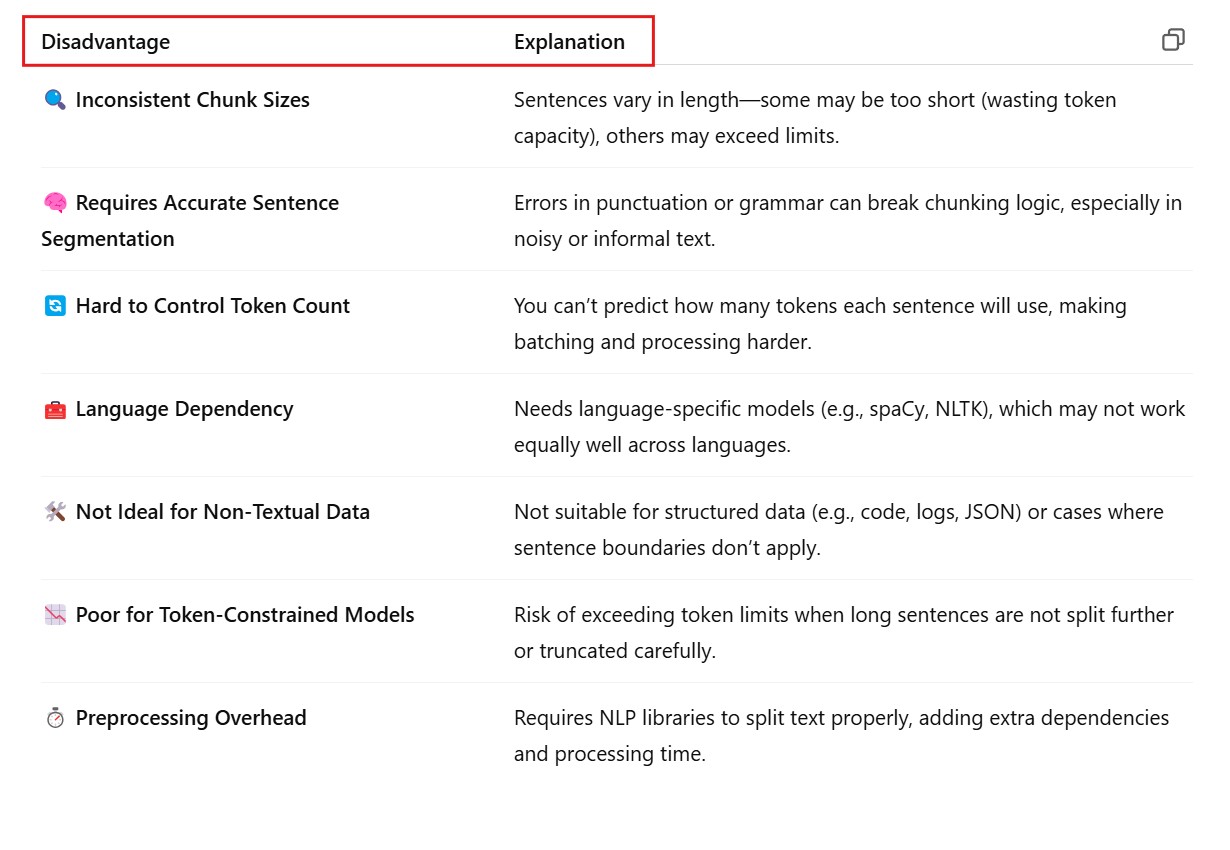
Example 1: Using Sentence Chunks with Transformers
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
sentences = [
"This is the first sentence.",
"Here is another sentence.",
"Language chunking helps manage token limits."
]
# Encode each sentence
token_chunks = [tokenizer.encode(sentence, return_tensors="pt") for sentence in sentences]
Example 2: Sentence Chunking using NLTK
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
text = "Language models require well-structured input. Sentence chunking helps maintain semantic boundaries. It's important for tasks like summarization."
sentence_chunks = sent_tokenize(text)
print(sentence_chunks)
Example 3: Sentence Chunking using spaCy
import spacy
# Load the English model
nlp = spacy.load("en_core_web_sm")
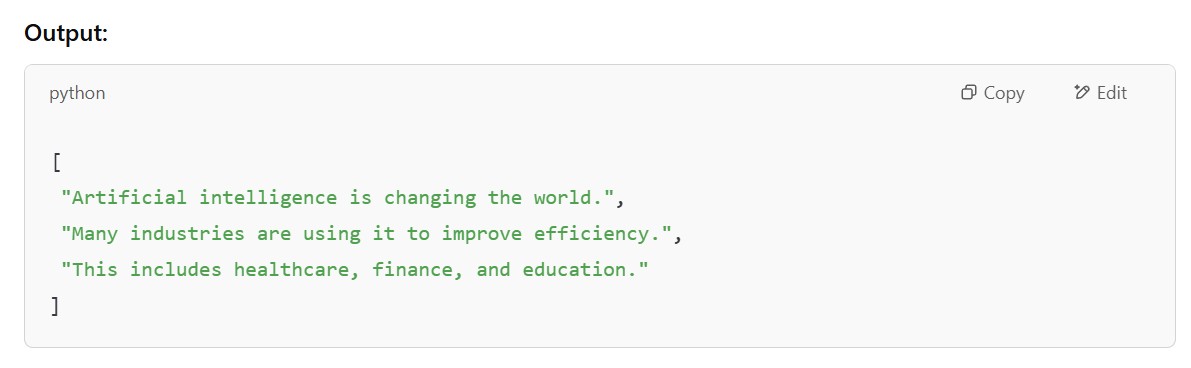
text = "Artificial intelligence is changing the world. Many industries are using it to improve efficiency. This includes healthcare, finance, and education."
# Process text and split into sentences
doc = nlp(text)
sentence_chunks = [sent.text for sent in doc.sents]
print(sentence_chunks)