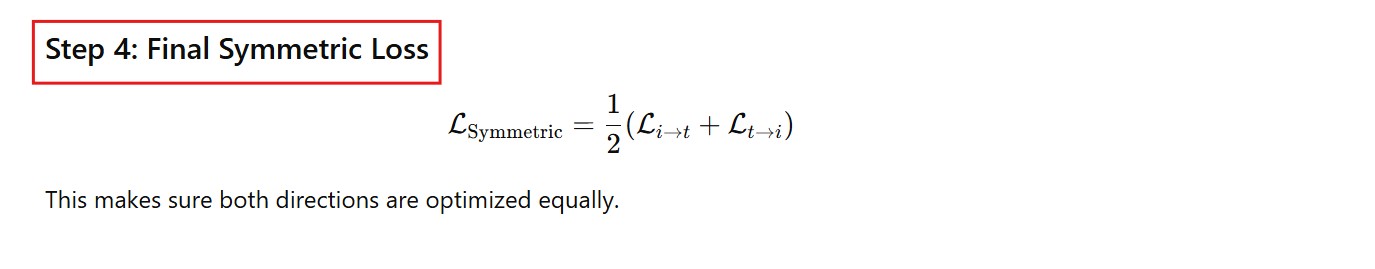admin
What is CLIP?
Why CLIP was developed (motivation)
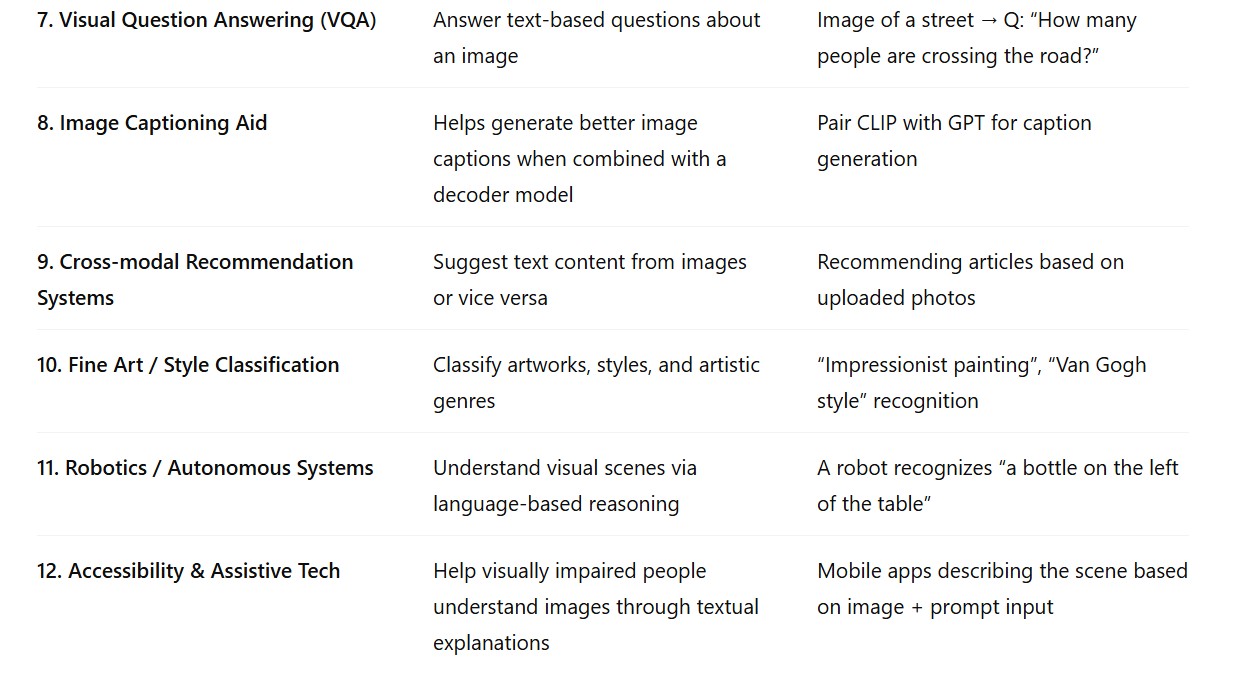
Use cases and real-world applications
Comparison with previous approaches (e.g., ImageNet classification)
Dual-encoder design: Image encoder and Text encoder
ViT (Vision Transformer) or ResNet for images
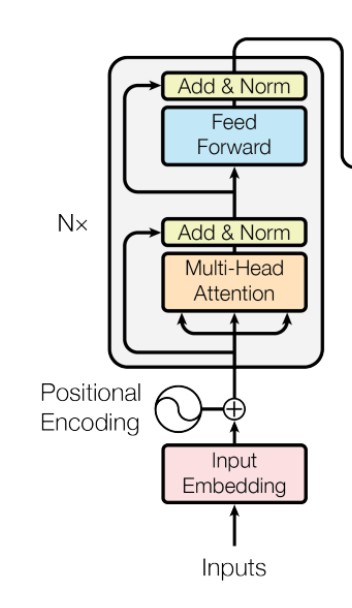
Transformer for text encoding
Embedding spaces and joint alignment
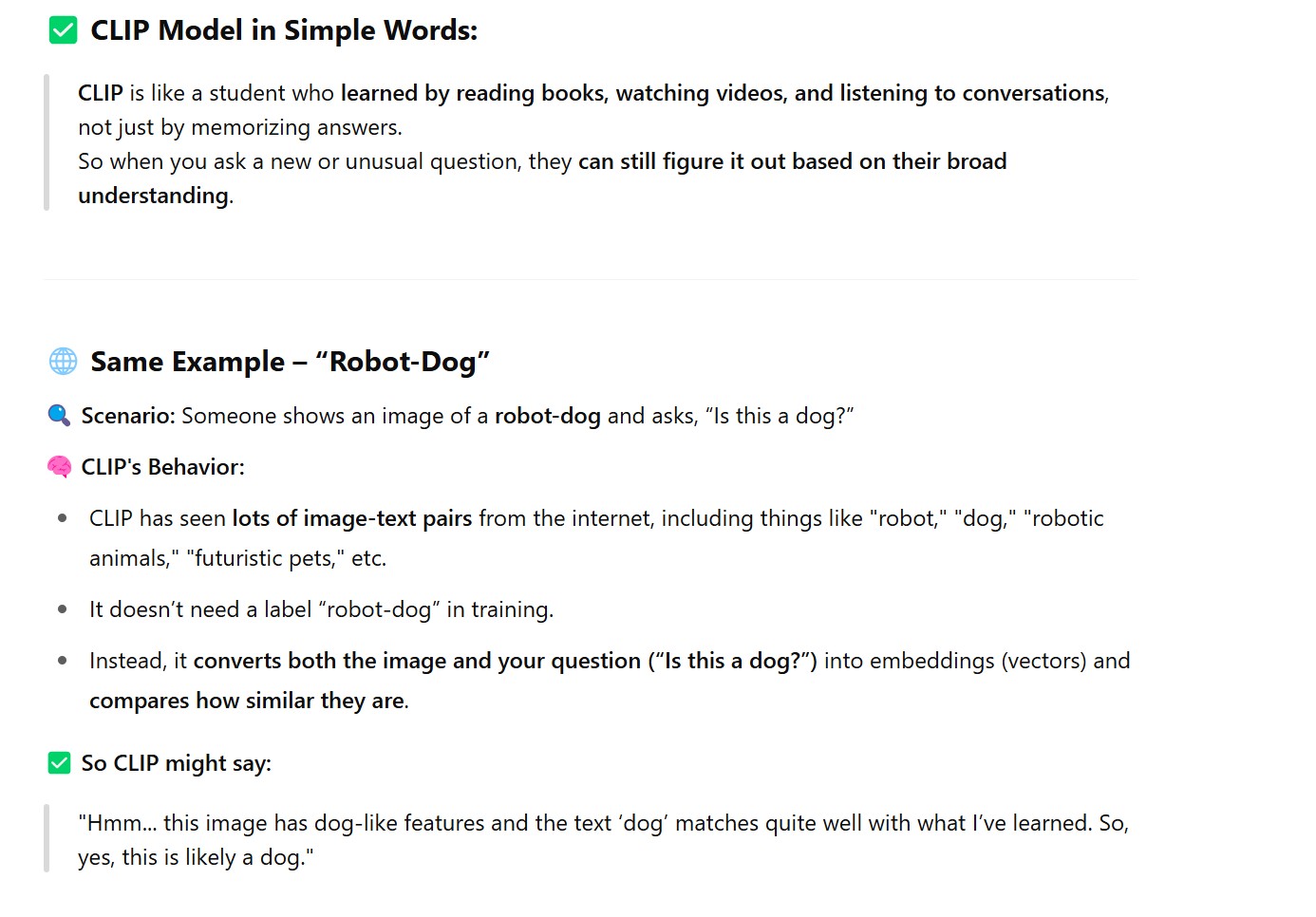
How CLIP learns from (image, text) pairs
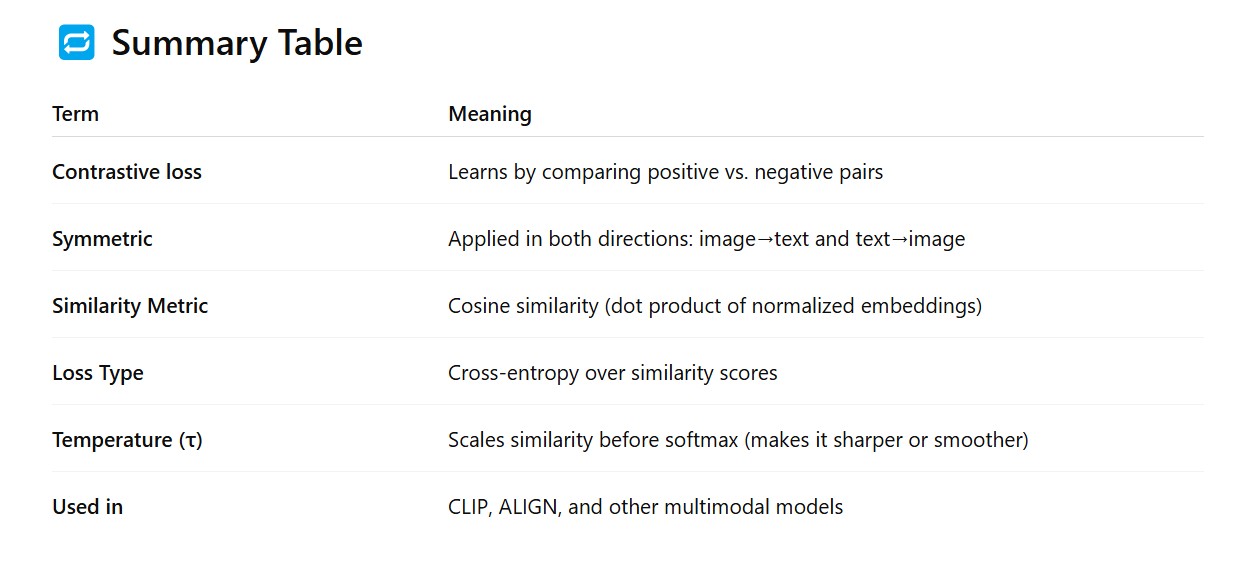
Contrastive loss function (InfoNCE)
Positive vs negative sampling
Similarity computation using cosine similarity
Dataset used: 400M (image, text) pairs
Uncurated, noisy internet data
Zero-shot learning setup
Zero-shot performance on downstream tasks
Benchmarks: ImageNet, CIFAR, OCR tasks, etc.
Zero-shot classification vs fine-tuning
Using Hugging Face Transformers or OpenAI CLIP repository
Encoding images and text
Zero-shot classification with CLIP
Image-text retrieval
Dimensionality reduction techniques (e.g., t-SNE, PCA)
Embedding space alignment
Interpreting similarities
Adapter tuning (LoRA, prompt tuning)
Fine-tuning CLIP for downstream tasks
Multimodal Prompt Engineering with CLIP
OpenCLIP (open-source reimplementation)
BLIP, FLAVA, ALIGN, CoCa, DALL·E, CLIPCap
Multilingual CLIP
Dataset bias & ethical considerations
Sensitivity to adversarial prompts
Hallucination risks
Zero-shot image classification
Image-text retrieval search engine
Visual question answering with CLIP
Combine with generative models (e.g., CLIP + VQGAN)
Multimodal fusion strategies
Cross-modal retrieval systems
Contrastive vs generative approaches
Future of multimodal models
Your email address will not be published. Required fields are marked *
Comment *
Name *
Email *
Website
Save my name, email, and website in this browser for the next time I comment.