"""
Cloud Composer Logs to BigQuery Dataflow Pipeline
Streams logs from Pub/Sub to BigQuery with custom transformation
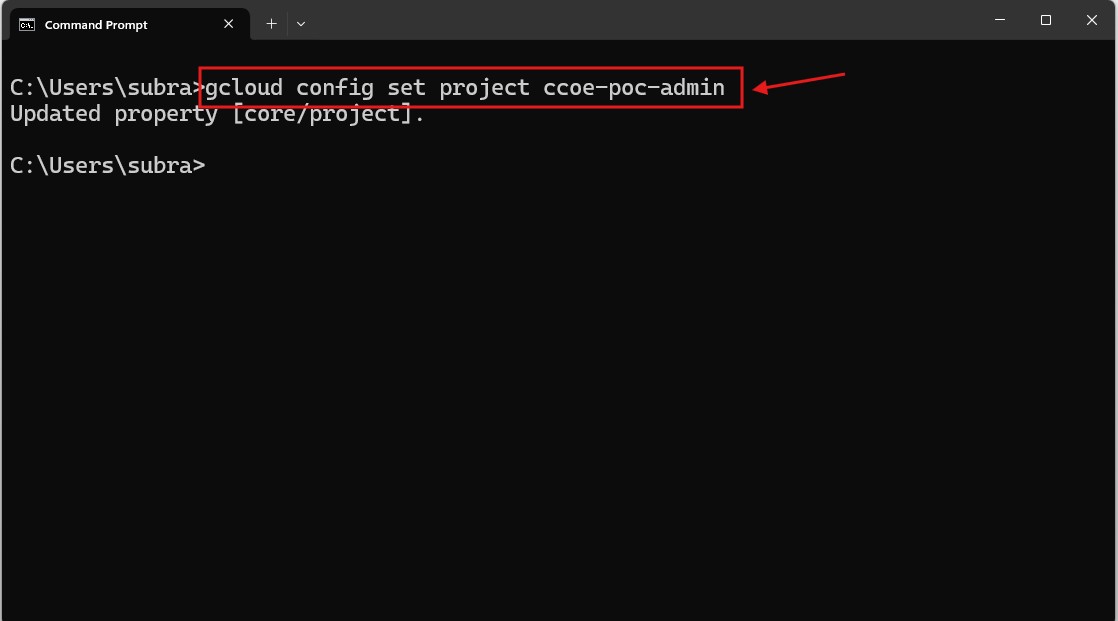
Project: ccoe-poc-admin
Input: projects/ccoe-poc-admin/subscriptions/log-processing-topic-sub
Output: ccoe-poc-admin:cloud_services_error_logs.cloud_composer_error_logs
"""
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions, StandardOptions
from apache_beam.io.gcp.bigquery import WriteToBigQuery, BigQueryDisposition
import json
import logging
from datetime import datetime
class ParseLogMessage(beam.DoFn):
"""
Parse and transform Cloud Composer log messages from Pub/Sub
Extracts all required fields matching the BigQuery schema
"""
def process(self, element):
"""
Process each Pub/Sub message and extract log fields
Args:
element: Pub/Sub message with data and attributes
Yields:
dict: Parsed log record matching BigQuery schema
"""
try:
# Extract Pub/Sub message attributes
message_id = ''
publish_time = ''
data = None
# Handle PubsubMessage object
if hasattr(element, 'data'):
data = element.data
message_id = getattr(element, 'message_id', '')
if hasattr(element, 'publish_time'):
# Convert timestamp to ISO format string
publish_time = element.publish_time
elif hasattr(element, 'timestamp') and element.timestamp:
publish_time = element.timestamp.isoformat()
else:
# Handle dict format (for testing)
data = element.get('data', element)
message_id = element.get('message_id', '')
publish_time = element.get('publish_time', '')
# Decode the data if it's bytes
if isinstance(data, bytes):
data = data.decode('utf-8')
# Parse JSON
if isinstance(data, str):
try:
log_data = json.loads(data)
except json.JSONDecodeError as e:
logging.error(f"Failed to parse JSON: {e}")
logging.error(f"Data received: {data[:500]}")
return
else:
log_data = data
# Log the parsed structure for debugging
logging.info(f"Parsed log_data keys: {list(log_data.keys())}")
# Extract required fields
insert_id = log_data.get('insertId', '')
# Validate insert_id (primary key)
if not insert_id:
logging.warning(f"Missing insertId in log entry")
insert_id = f"generated_{message_id}_{datetime.utcnow().strftime('%Y%m%d%H%M%S%f')}"
# Extract log name
log_name = log_data.get('logName', '')
# Extract text payload
text_payload = ''
if 'textPayload' in log_data:
text_payload = str(log_data.get('textPayload', ''))
elif 'jsonPayload' in log_data:
json_payload = log_data.get('jsonPayload', {})
if isinstance(json_payload, dict):
text_payload = json_payload.get('message', '')
if not text_payload:
text_payload = json.dumps(json_payload)
else:
text_payload = str(json_payload)
elif 'protoPayload' in log_data:
text_payload = str(log_data.get('protoPayload', ''))
# Store complete raw payload
raw_payload = json.dumps(log_data)
# Extract resource information
resource = log_data.get('resource', {})
resource_type = resource.get('type', '')
resource_labels = resource.get('labels', {})
resource_project_id = resource_labels.get('project_id', '')
environment_name = resource_labels.get('environment_name', '')
location = resource_labels.get('location', '')
# Extract severity level - THIS IS CRITICAL
severity = log_data.get('severity', '')
if not severity:
severity = 'INFO' # Default value if missing
logging.info(f"Extracted severity: '{severity}' from log entry")
# Extract scheduler_id from labels
scheduler_id = ''
if 'labels' in log_data and isinstance(log_data['labels'], dict):
scheduler_id = log_data['labels'].get('scheduler_id', '')
# Extract timestamps
receive_timestamp = log_data.get('receiveTimestamp', '')
timestamp = log_data.get('timestamp', '')
if not receive_timestamp:
receive_timestamp = timestamp
# Convert publish_time to string if it's not already
if publish_time and not isinstance(publish_time, str):
publish_time = str(publish_time)
# Create the output record matching BigQuery schema
output_record = {
'insert_id': str(insert_id),
'message_id': str(message_id),
'log_name': str(log_name),
'text_payload': str(text_payload),
'raw_payload': str(raw_payload),
'resource_type': str(resource_type),
'resource_project_id': str(resource_project_id),
'environment_name': str(environment_name),
'location': str(location),
'severity': str(severity), # Ensure it's a string
'scheduler_id': str(scheduler_id),
'publish_timestamp': str(publish_time) if publish_time else '',
'receive_timestamp': str(receive_timestamp)
}
# Log the complete output record for verification
logging.info(f"Output record for insert_id {insert_id}: {list(output_record.keys())}")
logging.info(f"Severity in output: '{output_record['severity']}'")
yield output_record
except Exception as e:
logging.error(f"Error parsing log message: {str(e)}", exc_info=True)
logging.error(f"Element type: {type(element)}")
if hasattr(element, 'data'):
logging.error(f"Element data (first 500 chars): {str(element.data)[:500]}")
else:
logging.error(f"Element content (first 500 chars): {str(element)[:500]}")
class ValidateRecord(beam.DoFn):
"""
Validate that required fields are present and properly formatted
"""
def process(self, element):
"""
Validate the record before writing to BigQuery
"""
# Check if insert_id is present
if not element.get('insert_id') or element.get('insert_id').strip() == '':
logging.warning(f"Record missing insert_id, skipping")
return
# Ensure ALL fields exist and are strings (not None)
required_fields = [
'insert_id', 'message_id', 'log_name', 'text_payload', 'raw_payload',
'resource_type', 'resource_project_id', 'environment_name', 'location',
'severity', 'scheduler_id', 'publish_timestamp', 'receive_timestamp'
]
for field in required_fields:
if field not in element or element[field] is None:
element[field] = ''
else:
element[field] = str(element[field]) # Force to string
# Log for debugging
logging.info(f"Validated record - severity: '{element['severity']}'")
# Truncate fields if too long
max_lengths = {
'insert_id': 1024,
'message_id': 1024,
'log_name': 2048,
'resource_type': 256,
'resource_project_id': 256,
'environment_name': 256,
'location': 256,
'severity': 50,
'scheduler_id': 256,
'publish_timestamp': 100,
'receive_timestamp': 100
}
for field, max_length in max_lengths.items():
if len(element[field]) > max_length:
element[field] = element[field][:max_length]
yield element
def run_pipeline(argv=None):
"""
Main pipeline execution function
Args:
argv: Command-line arguments
"""
# Define pipeline options
pipeline_options = PipelineOptions(
argv,
project='ccoe-poc-admin',
region='us-west1', # CHANGE THIS to your region if different
temp_location='gs://gcp_log_monitoring_bucket/temp',
staging_location='gs://gcp_log_monitoring_bucket/staging',
runner='DataflowRunner', # Use 'DirectRunner' for local testing
streaming=True,
save_main_session=True,
job_name='composer-logs-to-bigquery',
service_account_email='[email protected]',
network='https://www.googleapis.com/compute/v1/projects/nonprod-shared-l2/global/networks/eqx-nonprod',
subnetwork='https://www.googleapis.com/compute/v1/projects/nonprod-shared-l2/regions/us-west1/subnetworks/helix-usw1-poc',
# 🔧 ADD THESE CRITICAL PARAMETERS
use_public_ips=False, # Disable external IPs
no_use_public_ips=True, # Alternative flag (use one or both)
# Additional Dataflow options
autoscaling_algorithm='THROUGHPUT_BASED',
max_num_workers=5,
num_workers=1,
# Machine type - adjust based on your needs
machine_type='n1-standard-2',
# Enable Dataflow Shuffle service for better performance
experiments=['use_runner_v2'],
)
# Set streaming mode explicitly
pipeline_options.view_as(StandardOptions).streaming = True
# BigQuery table schema matching your requirements
table_schema = {
'fields': [
{'name': 'insert_id', 'type': 'STRING', 'mode': 'REQUIRED',
'description': 'Unique identifier for this log entry within the logging system.'},
{'name': 'message_id', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Unique identifier assigned by Pub/Sub to each published message.'},
{'name': 'log_name', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Full path of the log that produced the entry.'},
{'name': 'text_payload', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'The actual log message text (errors, stack traces, etc.).'},
{'name': 'raw_payload', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Entire original JSON message for debugging or re-processing.'},
{'name': 'resource_type', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Type of GCP resource that generated the log.'},
{'name': 'resource_project_id', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'GCP project ID where the resource exists.'},
{'name': 'environment_name', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Name of the environment that produced the log.'},
{'name': 'location', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'GCP region/location of the resource.'},
{'name': 'severity', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Log level indicating the seriousness (e.g., ERROR, INFO).'},
{'name': 'scheduler_id', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Identifier for the Airflow scheduler pod that emitted this log.'},
{'name': 'publish_timestamp', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Time when Pub/Sub published the message.'},
{'name': 'receive_timestamp', 'type': 'STRING', 'mode': 'NULLABLE',
'description': 'Time when Cloud Logging received the log entry.'}
]
}
# Build and run the pipeline
with beam.Pipeline(options=pipeline_options) as p:
(p
# Read from Pub/Sub subscription
| 'Read from Pub/Sub' >> beam.io.ReadFromPubSub(
subscription='projects/ccoe-poc-admin/subscriptions/log-processing-topic-sub',
with_attributes=True
)
# Parse log messages
| 'Parse Log Messages' >> beam.ParDo(ParseLogMessage())
# Validate records
| 'Validate Records' >> beam.ParDo(ValidateRecord())
# Write to BigQuery
| 'Write to BigQuery' >> WriteToBigQuery(
table='ccoe-poc-admin:cloud_services_error_logs.cloud_composer_error_logs',
schema=table_schema,
write_disposition=BigQueryDisposition.WRITE_APPEND,
create_disposition=BigQueryDisposition.CREATE_IF_NEEDED,
method='STREAMING_INSERTS', # Use streaming for real-time
insert_retry_strategy='RETRY_ON_TRANSIENT_ERROR',
additional_bq_parameters={
'timePartitioning': {
'type': 'DAY',
'field': 'receive_timestamp'
}
})
)
if __name__ == '__main__':
# Set up logging
logging.getLogger().setLevel(logging.INFO)
# Print startup message
print("=" * 80)
print("Starting Cloud Composer Logs to BigQuery Dataflow Pipeline")
print("=" * 80)
print(f"Project: ccoe-poc-admin")
print(f"Input: projects/ccoe-poc-admin/subscriptions/log-processing-topic-sub")
print(f"Output: ccoe-poc-admin:cloud_services_error_logs.cloud_composer_error_logs")
print("=" * 80)
# Run the pipeline
run_pipeline()