-

Sequential Data
Gradient Descent Optimizer Table Of Contents: What Is Sequential Data? Key Characteristics Of Sequential Data. Examples Of Sequential Data. Why Is Sequential Data Is An Issue For The Traditional Neural Network? (1) What Is Sequential Data? Sequential data is data arranged in sequences where order matters. Data points are dependent on other data points in this sequence. Examples of sequential data include customer grocery purchases, patient medical records, or simply a sequence of numbers with a pattern. In sequence data, each element in the sequence is related to the ones that come before and after it, and the way these
-
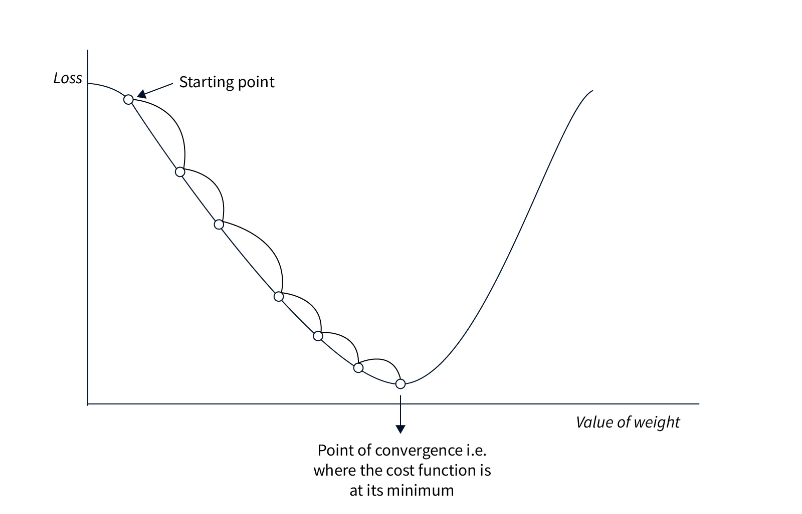
Gradient Descent Optimizer
Gradient Descent Optimizer Table Of Contents: What Is Gradient Descent Algorithm? Basic Gradient Descent Algorithms. Batch Gradient Descent. Stochastic Gradient Descent (SGD). Mini-Batch Gradient Descent. Learning Rate. What Is The Learning Rate? Learning Rate Scheduling. Variants of Gradient Descent. Momentum. Nesterov Accelerated Gradient (NAG). Adagrad. RMSprop. Adam. Optimization Challenges Local Optima Plateaus and Vanishing Gradients. Overfitting. (1) What Is Gradient Descent Algorithm? The Gradient Descent algorithm is an iterative optimization algorithm used to minimize a given function, typically a loss function, by adjusting the parameters of a model. It is widely used in machine learning and deep learning to update
-

Cost Functions In Deep Learning.
Cost Functions Table Of Contents: What Is A Cost Function? Mean Squared Error (MSE) Loss. Binary Cross-Entropy Loss. Categorical Cross-Entropy Loss. Custom Loss Functions. Loss Functions for Specific Tasks. Loss Functions for Imbalanced Data. Loss Function Selection. (1) What Is A Cost Function? A cost function, also known as a loss function or objective function, is a mathematical function used to measure the discrepancy between the predicted output of a machine learning model and the actual or target output. The purpose of a cost function is to quantify how well the model is performing and to guide the optimization process
-

Optimization Algorithms In Deep Learning.
Optimization Algorithms For Neural Networks Table Of Contents: What Is An Optimization Algorithm? Gradient Descent Variants: Batch Gradient Descent (BGD) Stochastic Gradient Descent (SGD) Mini-Batch Gradient Descent Convergence analysis and trade-offs Learning rate selection and scheduling Adaptive Learning Rate Methods: AdaGrad RMSProp Adam (Adaptive Moment Estimation) Comparisons and performance analysis Hyperparameter tuning for adaptive learning rate methods Momentum-Based Methods: Momentum Nesterov Accelerated Gradient (NAG) Advantages and limitations of momentum methods Momentum variants and improvements Second-Order Methods: Newton’s Method Quasi-Newton Methods (e.g., BFGS, L-BFGS) Hessian matrix and its computation Pros and cons of second-order methods in deep learning Optimization Challenges and
-
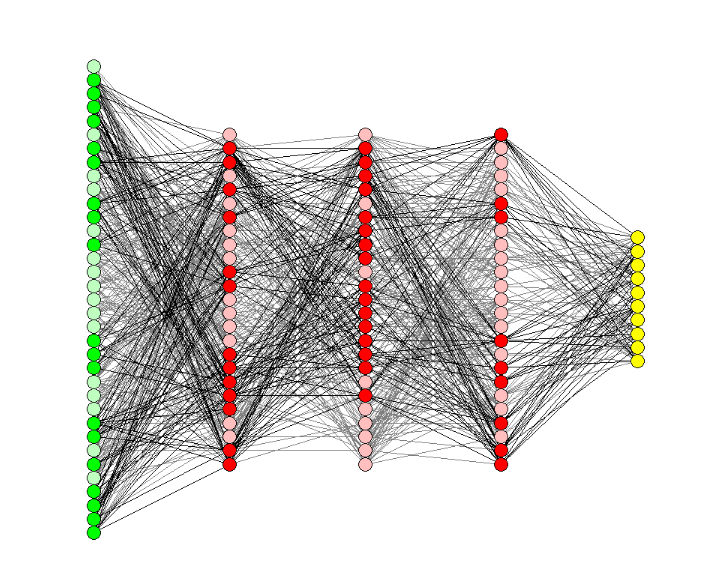
Feedforward Neural Networks
Feedforward Neural Network Table Of Contents: What Is Feedforward Neural Network? Why Are Neural Networks Used? Neural Network Architecture And Operation. Components Of Feedforward Neural Network. How Feedforward Neural Network Works? Why Does This Strategy Works? Importance Of Non-Linearity. Applications Of Feed Forward Neural Network. (1) What Is Feedforward Neural Network? The feed-forward model is the simplest type of neural network because the input is only processed in one direction. The data always flows in one direction and never backwards, regardless of how many buried nodes it passes through. A feedforward neural network, also known as a multilayer perceptron (MLP), is a
-

Softmax Activation Function
Softmax Activation Function Table Of Contents: What Is SoftMax Activation Function? Formula & Diagram For SoftMax Activation Function. Why Is SoftMax Function Important. When To Use SoftMax Function? Advantages & Disadvantages Of SoftMax Activation Function. (1) What Is SoftMax Activation Function? The Softmax Function is an activation function used in machine learning and deep learning, particularly in multi-class classification problems. Its primary role is to transform a vector of arbitrary values into a vector of probabilities. The sum of these probabilities is one, which makes it handy when the output needs to be a probability distribution. (2) Formula & Diagram
-

ReLU vs. Leaky ReLU vs. Parametric ReLU.
ReLU vs. Leaky ReLU vs. Parametric ReLU Table Of Contents: Comparison Between ReLU vs. Leaky ReLU vs. Parametric ReLU. Which One To Use At What Situation? (1) Comparison Between ReLU vs. Leaky ReLU vs. Parametric ReLU ReLU, Leaky ReLU, and Parametric ReLU (PReLU) are all popular activation functions used in deep neural networks. Let’s compare them based on their characteristics: Rectified Linear Unit (ReLU): Activation Function: f(x) = max(0, x) Advantages: Simplicity: ReLU is a simple and computationally efficient activation function. Sparsity: ReLU promotes sparsity by setting negative values to zero, which can be beneficial in reducing model complexity. Disadvantages:
-

Exponential Linear Units (ELU) Activation Function.
Exponential Linear Unit Activation Function Table Of Contents: What IsExponential Linear Unit Activation Function? Formula & Diagram For Exponential Linear Unit Activation Function. Where To Use Exponential Linear Unit Activation Function? Advantages & Disadvantages Of Exponential Linear Unit Activation Function. (1) What Is Exponential Linear Unit Activation Function? The Exponential Linear Unit (ELU) activation function is a type of activation function commonly used in deep neural networks. It was introduced as an alternative to the Rectified Linear Unit (ReLU) and addresses some of its limitations. The ELU function introduces non-linearity, allowing the network to learn complex relationships in the data.
-
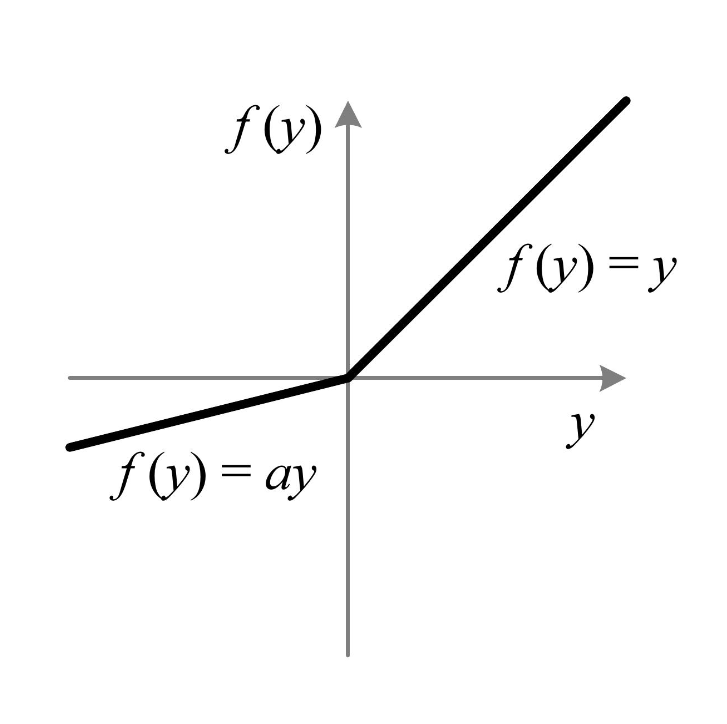
Parametric ReLU (PReLU) Activation Function
Parametric ReLU (PReLU) Activation Function Table Of Contents: What Is Parametric ReLU (PReLU) Activation Function? Formula & Diagram For Parametric ReLU (PReLU) Activation Function. Where To Use Parametric ReLU (PReLU) Activation Function? Advantages & Disadvantages Of Parametric ReLU (PReLU) Activation Function. (1) What Is Parametric ReLU (PReLU) Activation Function? The Parametric ReLU (PReLU) activation function is an extension of the standard ReLU (Rectified Linear Unit) function that introduces learnable parameters to control the slope of the function for both positive and negative inputs. Unlike the ReLU and Leaky ReLU, which have fixed slopes, the PReLU allows the slope to be
-

Leaky ReLU Activation Function.
Leaky ReLU Activation Function. Table Of Contents: What Is Leaky ReLU Activation Function? Formula & Diagram For Leaky ReLU Activation Function. Where To Use Leaky ReLU Activation Function? Advantages & Disadvantages Of Leaky ReLU Activation Function? (1) What Is Leaky ReLU Activation Function? The Leaky ReLU (Rectified Linear Unit) activation function is a modified version of the standard ReLU function that addresses the “dying ReLU” problem, where ReLU neurons can become permanently inactive. The Leaky ReLU introduces a small slope for negative inputs, allowing the neuron to respond to negative values and preventing complete inactivation. (2) Formula & Diagram For
