Q & A – AWS Model Deployement
Table Of Contents:
- General ML Deployment Questions.
- Docker & Containerization.
- Cloud Deployment (AWS, GCP, Azure).
- API & Flask Integration.
- Scaling & Optimization.
- CI/CD & Automation.
- Security & Monitoring.
(1) General ML Deployment Questions.
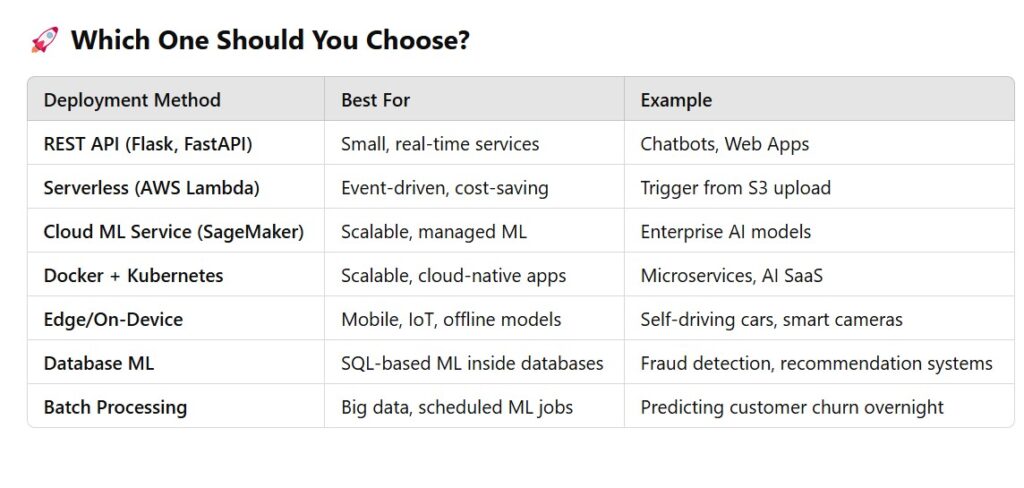
What are the different ways to deploy a machine learning model?
What is the difference between batch inference and real-time inference?
What are the advantages and disadvantages of deploying models using Docker?
What are edge AI deployments, and when should you use them?
How do you handle model versioning in deployment?
(2) General ML Deployment Questions.
What is a Docker container, and why is it used in ML model deployment?
What are the key components of a Dockerfile for ML model deployment?
How do you expose a port in Docker, and why is it needed?
What’s the difference between
COPYandADDin a Dockerfile?How do you share a model file between your local machine and a Docker container?
(3) Cloud Deployment (AWS, GCP, Azure)
How do you deploy a machine learning model on AWS SageMaker?
What’s the difference between EC2, Lambda, and SageMaker for ML deployment?
How do you scale an ML model deployment in AWS ECS or Kubernetes?
What is an Elastic IP, and why is it useful when deploying ML models?
What is an IAM role, and why is it important in cloud-based ML deployment?
(4) API & Flask Integration
How do you create a Flask API for an ML model?
What is the difference between GET and POST requests in an ML API?
How do you pass input data in a URL when making API requests?
What’s the purpose of
request.get_json()in a Flask API?How do you return predictions in JSON format from a Flask API?
(5) Scaling & Optimization
How can you optimize an ML model for faster inference?
What is model quantization, and how does it help in deployment?
How do you handle high traffic when serving ML models?
What’s the difference between horizontal scaling and vertical scaling?
How can you use Redis or a cache to improve inference speed?
(6) CI/CD & Automation
What is CI/CD in ML model deployment, and why is it important?
How do you automate model deployment using GitHub Actions or Jenkins?
What are the challenges of continuous model deployment?
How do you ensure that a newly deployed model does not degrade performance?
How do you perform A/B testing for ML models in production?
(7) Security & Monitoring
How do you secure an ML model API?
What are rate limiting and API authentication, and why are they important?
How do you monitor the performance of a deployed ML model?
What is model drift, and how do you detect it?
How can you log errors and API requests in an ML model deployment?
(8) Bonus: Hands-on Scenario Questions
- You deployed an ML model on AWS EC2, but you can’t access it via the public IP. How do you debug this issue?
- Your Flask API works locally, but after deploying with Docker, you get “ModuleNotFoundError” for NumPy. How do you fix this?
Your model is deployed, but predictions are very slow. What optimizations would you consider?
******************************************************
(1) What Are The Different Ways To Deploy A Machine Learning Model?