-

Transformers – Why Self Attention Is Called Self ?
Why Self Attention Is Called Self ? Table Of Contents: Why Self Attention Is Called Self ? (1) Why Self Attention Is Called Self ? We have learnt the Attention concepts from the Luong Attention. In Luong attention mechanism, we calculate which word of the Encoder is more important in predicting the current time step output of the Decoder. To Do this we assign an attention score to each word of the Encoder and pass it as input to the Decoder. We put a SoftMax layer to normalize the attention score. The same operation mathematical we are performing in case
-

Transformers – Self Attention Geometric Intuition!!
Self Attention Geometric Intuition!! Table Of Contents: What Is Self Attention? Why Do We Need Self Attention? How Self Attention Works? Example Of Self Attention. Where is Self-Attention Used? Geometric Intuition Of Self-Attention. (1) What Is Self Attention? Self-attention is a mechanism in deep learning that allows a model to focus on different parts of an input sequence when computing word representations. It helps the model understand relationships between words, even if they are far apart, by assigning different attention weights to each word based on its importance in the context. (2) Why Do We Need Self Attention? (3) How
-
How The Dense LSTM Layers Handles Input ?
How The Dense LSTM Layers Handles Input ? Table Of Contents: How Are Words Passed to Neurons in an LSTM(128) Layer? Step 1: Input from the Embedding Layer Step 2: Passing Each Word to the LSTM Layer Step 3: What Happens Inside Each LSTM Neuron? Step 4: Understanding the Output of LSTM(128) Final Conclusion Key Takeaway (1) How Are Words Passed to Neurons in an LSTM(128) Layer? (2) How Individual LSTM Neurons Connected To Each Other. (3) What Is The Output Of LSTM(128) Number Of Neurons. (4) Step 1: Input from the Embedding Layer (5) Step 2: Passing Each Word
-

Text Preprocessing Steps In NLP
Text preprocessing Steps In NLP Table Of Contents: Text Cleaning Text Tokenization Text Normalization Text Vectorization (1) Text Cleaning (2) Text Tokenization Methods Of Text Tokenization: (3) Text Normalization (4) Text Vectorization Common Techniques for Text Vectorization:
-
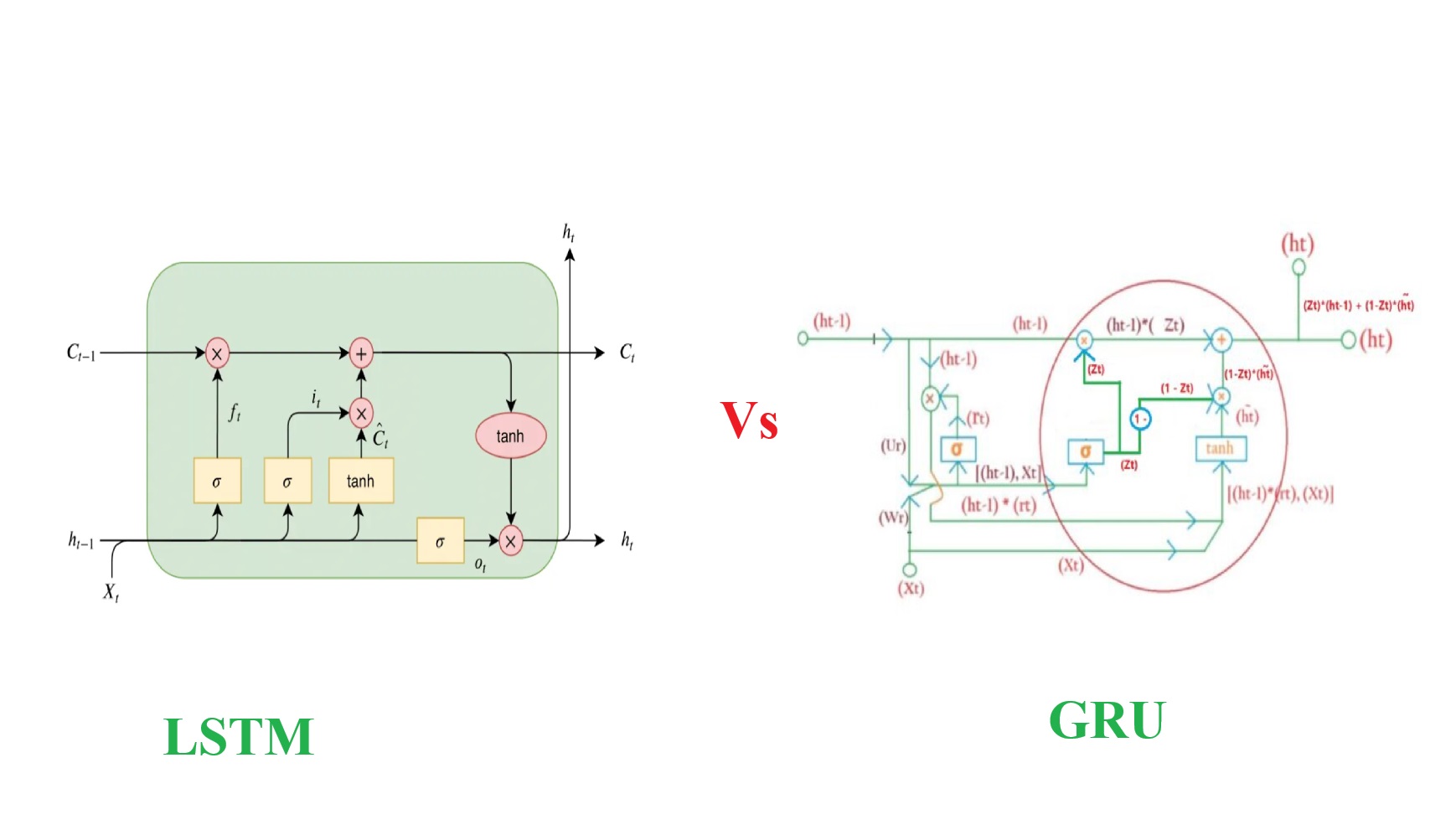
Difference Between LSTM & GRU.
Difference Between LSTM & GRU Table Of Contents: Structure and Complexity. Cell State vs. Hidden State Gating Mechanism Parameter Efficiency Performance Interpretability Use Cases Summary Table Conclusion
-

Forward Pass Of LSTM Network.
Forward Pass Of LSTM Network Syllabus: Forward Pass In LSTM Neural Network. Answer: Forward Pass Work: Input Layer: 1st Hidden Layer: Each cell in the LSTM layer will output two values one is Cell state (Ct) and another one is hidden state (ht). This two value will be passed to the next layer as a tuple. Example:
-

What Is Backpropagation?
What Is Back Propagation Syllabus: What Is Backpropagation? Steps Of Backpropagation. Math’s In Backpropagation. (1) What Is Backpropagation? Backpropagation, short for backward propagation of errors, is a supervised learning algorithm used to train artificial neural networks. It adjusts the weights of the network to minimize the error between the predicted outputs and the actual target values. Here’s how it works: (2) Steps Of Backpropagation (3) Math’s Behind Backpropagation Forward Propagation: Loss Calculation: Back Propagation:
-

RNN – All Doubts Answers!
RNN – All Doubts Answers! Syllabus: Explain Me The Embedding LAYER. RNN One To One Architecture RNN One To Many Architecture RNN Many To One Architecture RNN Many To Many Architecture how in case of One-to-One Architecture input_length can be 5 but not in one to many processes the sequence as a whole. and entire input sequence step by step (or token by token). what is the difference Architecture of Recurrent Neural Network (RNN) Why RNN Uses Same Weights For Every Words? Super Note: The RNN architecture depends on how it takes input and produces output. In One-To-One architecture
-

CNN – Full CNN Architecture
CNN – Full CNN Architecture Syllabus: Architecture Diagram Of CNN. Input Layer Of CNN. Convolutional Layers Of CNN. Activation Function Of CNN. Pooling Layers Of CNN. Fully Connected (Dense) Layers. Output Layer Of CNN. Example CNN Architecture. (1) Architecture Diagram Of CNN (2) Input Layer Of CNN (3) Convolutional Layers Of CNN. (4) Activation Function (5) Pooling Layers Of CNN. (6) Fully Connected (Dense) Layers (7) Output Layer
-
CNN – If We Are Flattening The Feature Map Aren’t We Loose The Spatial Information?
CNN – If We Are Flattening The Feature Map Aren’t We Loose The Spatial Information? Syllabus: What Happens During Flattening? Loss of Spatial Information Why Flattening is Used Despite This Limitation? Alternatives to Flattening Example Conclusion Answer: Yes, flattening a feature map in a Convolutional Neural Network (CNN) leads to the loss of spatial information because the structured 2D or 3D representation of the features is converted into a 1D vector. While this is acceptable for certain tasks (like classification), it does come with trade-offs. What Happens During Flattering? Loss Of Spatial Information: Why Flattening is Used Despite This Limitation:
