-

TF-IDF Word Vectorization
TF-IDF Word Vectorization Table Of Contents: What Is TF-IDF Word Vectorization? What Is Term Frequency? What Is Inverse Document Frequency? How To Calculate TF-IDF? Steps For TF-IDF Calculation. Example Of TF-IDF Calculation. Pros & Cons Of TF-IDF Technique. Python Example. (1) What Is TF-IDF Word Vectorization? TF-IDF (Term Frequency-Inverse Document Frequency) is a widely used word vectorization technique in natural language processing (NLP). It represents text data as numerical vectors, which can be used as input for various machine learning algorithms. (2) Term Frequency The term frequency is a simple count of how many times a word appears in a
-
N-Grams/Bi-Grams/Tri-Grams
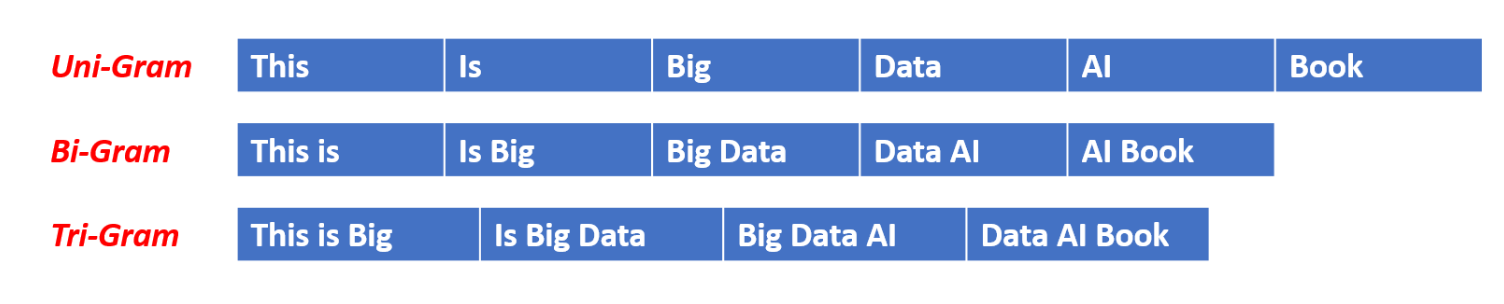
N-Grams/Bi-Grams/Tri-Grams Table Of Contents: What Is N-Gram? Example Of N-Gram Unigram. Bigram. Trigram. Python Example. Pros & Cons Of N-Gram Technique. (1) What Is N-Gram? The n-gram technique is a fundamental concept in natural language processing (NLP) that involves analyzing the relationship between sequences of n consecutive words or characters within a given text. It is widely used in various NLP tasks, such as language modeling, text classification, and information retrieval. (2) Example Of N-Gram “I reside in Bengaluru”. SL.No. Type of n-gram Generated n-grams 1 Unigram [“I”,”reside”,”in”,”Bengaluru”] 2 Bigram [“I reside”,”reside in”,”in Bengaluru”] 3 Trigram [“I reside
-
Bag Of Words!
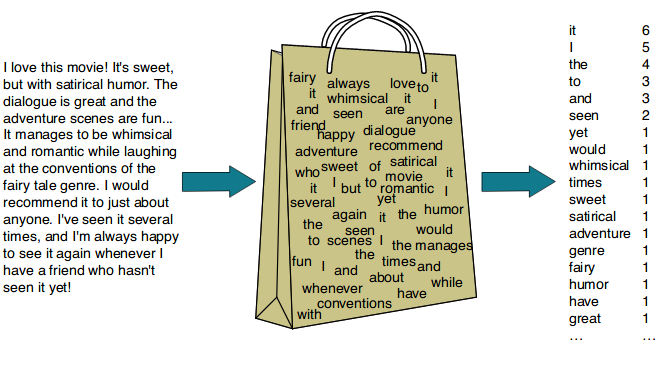
Bag Of Words Table Of Contents: What Is Bag Of Words? Example Of Bag Of Words. Core Intuition Behind Bag Of Words? How Bag Of Words Capture the Semantic Meaning? Python Program. (1) What Is Bag Of Words? Bag of Words (BoW) is a simple but widely used feature extraction technique in natural language processing (NLP). It is a way of representing text data as a numeric feature vector, where each feature corresponds to a unique word in the text corpus. Steps: Vocabulary Creation: The first step is to create a vocabulary of all the unique words or tokens present
-
One Hot Encoding In NLP
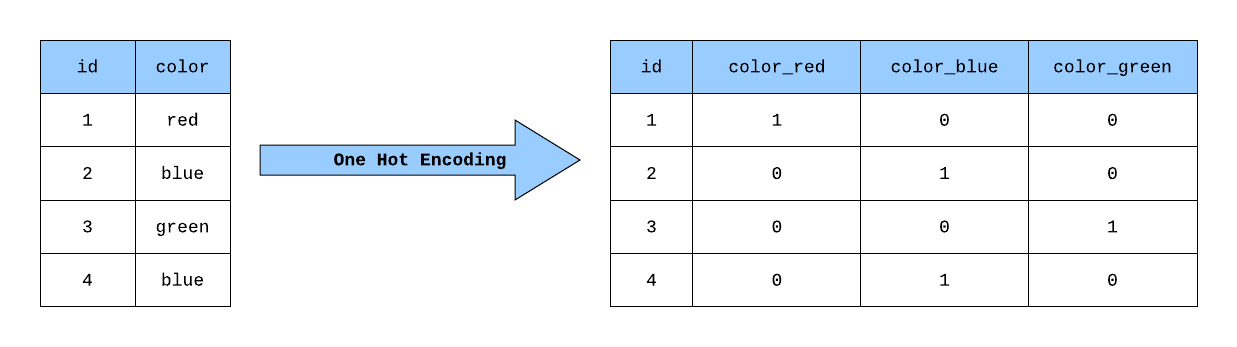
One Hot Encoding Table Of Contents: What Is One Hot Encoding? What Is Categorical Text Data? Example Of One Hot Encoding. Pros & Cons Of One Hot Encoding. (1) What Is One Hot Encoding? One-hot encoding is a feature extraction technique commonly used in Natural Language Processing (NLP) to represent categorical text data in a numerical format. It is a simple yet effective method for encoding categorical variables, including words, into a format that machine learning algorithms can use. Categorical text data refers to text data that can be divided into distinct categories or classes, where each piece of text
-
Feature Extraction In NLP
Feature Extraction In NLP Table Of Contents: What Is Feature Extraction From Text? Why We Need Feature Extraction? Why Feature Extraction Is Difficult? What Is The Core Idea Behind Feature Extraction? What Are The Feature Extraction Techniques? (1) What Is Feature Extraction From Text? Feature Extraction from text is the process of transforming raw text data into a format that can be effectively used by machine learning algorithms. In the context of natural language processing (NLP), feature extraction involves identifying and extracting relevant characteristics or features from the text data that can be used as inputs to predictive models. A
-

Jupyter Notebook Module Not Found Error.
Jupyter Notebook Module Not Found Error. Table Of Contents: How To Solve Module Not Found Error In Jupyter Notebook? Solution: Step-1: Install Missing Dependencies. Use the below command to install missing dependencies. !pip install numpy Step-3: Check Under Which Folder Your Library Has Installed. First, you need to know under which folder your installed library is present. Run the below command to check for the library location. !pip install textblob Step-3: Check The Module Path You need to check what the paths Jupyter Notebook is looking for to find the packages and libraries. import sys print(sys.path) If your installed library
-

NLP Text Preprocessing.
NLP Text Preprocessing Table Of Contents: Introduction. Lowercasing. Remove HTML Tags. Remove URLs. Remove Punctuation. Chat Word Treatment. Spelling Correction. Removing Stop Words. Handling Emojis. Tokenization. Stemming. Lemmatization. (1) What Is NLP Text Preprocessing? NLP (Natural Language Processing) text preprocessing is the initial step in the NLP pipeline, where the raw text data is transformed and prepared for further analysis and processing. The goal of text preprocessing is to clean, normalize, and transform the text data into a format that can be effectively utilized by NLP models and algorithms. (2) Lower Casing. Lowercasing is an important step in NLP text
-
NLP Pipeline !
NLP Pipeline Table Of Contents: What Is NLP Pipeline? Steps Under NLP Pipeline. Data Acquisition. Text Preprocessing. Feature Engineering. Model Building. Model Evaluation. Model Deployment. (1) What Is NLP Pipeline? An NLP (Natural Language Processing) pipeline is a series of interconnected steps or modules used to process and analyze natural language data. The pipeline typically consists of several stages, each performing a specific task in the overall process of understanding and extracting useful information from unstructured text. The NLP pipeline is a set of steps to build an end-to-end NLP software. (2) Steps Under NLP Pipeline. Data Acquisition. Data Acquisition
-
Introduction To NLP!
Introduction To NLP Table Of Contents: What Is Natural Language? Features OF Natural Language. Natural Language Vs. Programming Language. What Is Natural Language Processing? Fundamental Task NLP Perform: Common NLP Tasks: Techniques and Approaches: Applications Of NLP. Models Used In NLP. Specific Models In NLP. (1) What Is Natural Language? Natural Language refers to the language that humans use to communicate with each other, including spoken and written forms. It encompasses the complex and nuanced ways in which humans express themselves, including grammar, syntax, semantics, pragmatics, and phonology. Natural Language is characterized by its variability, ambiguity, and context dependency, making
-

Gated Recurrent Unit (GRUs).
Gated Recurrent Units(GRUs) Table Of Contents: Disadvantages Of LSTM Networks. What Is GRU? Why We Need GRU Neural Network? (1) Disadvantages Of LSTM Networks. Computational Complexity: LSTM networks are more computationally complex compared to simpler architectures like feedforward neural networks or basic RNNs. This complexity arises due to the presence of multiple gates, memory cells, and additional parameters. As a result, training and inference can be more computationally expensive and time-consuming, especially for large-scale models and datasets. Memory Requirement: LSTM networks require more memory to store the additional parameters and memory cells. This can pose challenges when working with limited
