-

Transformers – Why Self Attention Is Called Self ?
Why Self Attention Is Called Self ? Table Of Contents: Why Self Attention Is Called Self ? (1) Why Self Attention Is Called Self ? We have learnt the Attention concepts from the Luong Attention. In Luong attention mechanism, we calculate which word of the Encoder is more important in predicting the current time step output of the Decoder. To Do this we assign an attention score to each word of the Encoder and pass it as input to the Decoder. We put a SoftMax layer to normalize the attention score. The same operation mathematical we are performing in case
-

Transformers – Self Attention Geometric Intuition!!
Self Attention Geometric Intuition!! Table Of Contents: What Is Self Attention? Why Do We Need Self Attention? How Self Attention Works? Example Of Self Attention. Where is Self-Attention Used? Geometric Intuition Of Self-Attention. (1) What Is Self Attention? Self-attention is a mechanism in deep learning that allows a model to focus on different parts of an input sequence when computing word representations. It helps the model understand relationships between words, even if they are far apart, by assigning different attention weights to each word based on its importance in the context. (2) Why Do We Need Self Attention? (3) How
-

Self Attentions In Transformers.
Self Attention In Transformers Table Of Contents: Motivation To Study Self Attention. Problem With Word Embedding. What Is Contextual Word Embedding? How Does Self-Attention Work? How To Get The Contextual Word Embeddings? Advantages Of First Principle Above Approach. Introducing Learnable Parameters In The Model. (1) Motivation To Study Self Attention. In 2024 we all know that there is a technology called ‘GenAI’ has penetrated into the market. With this technology we can create different new images, videos, texts from scratch automatically. The center of ‘GenAI’ technology is the ‘Transformers’. And the center of the Transformer is the ‘Self Attention’. Hence
-

What Is Self Attention ?
What Is Self Attention ? Table Of Contents: What Is The Most Important Thing In NLP Applications? Problem With Word2Vec Model. The Problem Of Average Meaning. What Is Self Attention? (1) What Is The Most Important Thing In NLP Applications? Before understanding the self-attention mechanism, we must understand the most important thing in any NLP application. The answer is how you convert any words into numbers ? Our computers don’t understand words they only understand numbers. Hence the researchers first worked in this direction to convert any words into vectors. We got some basic techniques like, One Hot Encoding. Bag
-
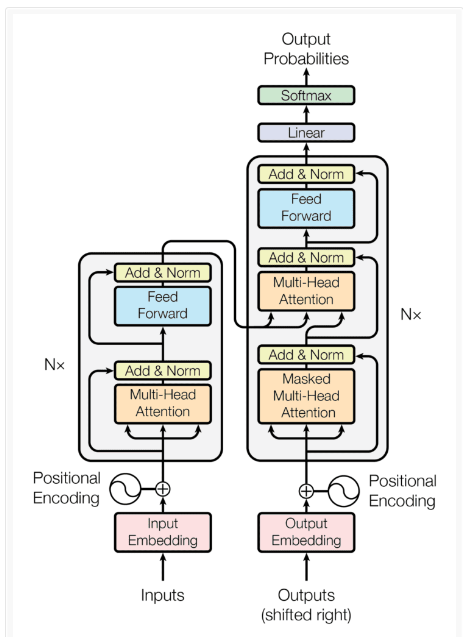
Introduction To Transformers!
Introduction To Transformers ! Table Of Contents: What Is Transformers? History Of Transformers. Impact Of Transformers In NLP. Democratizing AI. Multimodel Capability Of Transformers. Acceleration Of GenAI. Unification Of Deep Learning. Why Transformers Are Created? Neural Machine Translation Jointly Learning To Align & Translate. Attention Is All You Need. The Time Line Of Transformers. The Advantages Of Transformers. Real World Applications Of Transformers. Disadvantages Of Transformers. The Future Of Transformers. (1) What Is Transformers? Transformers is basically a Neural Network Architecture. In deep learning, we have already studied the ANN, CNN & RNN. ANN works for the cross-sectional data, CNN
-
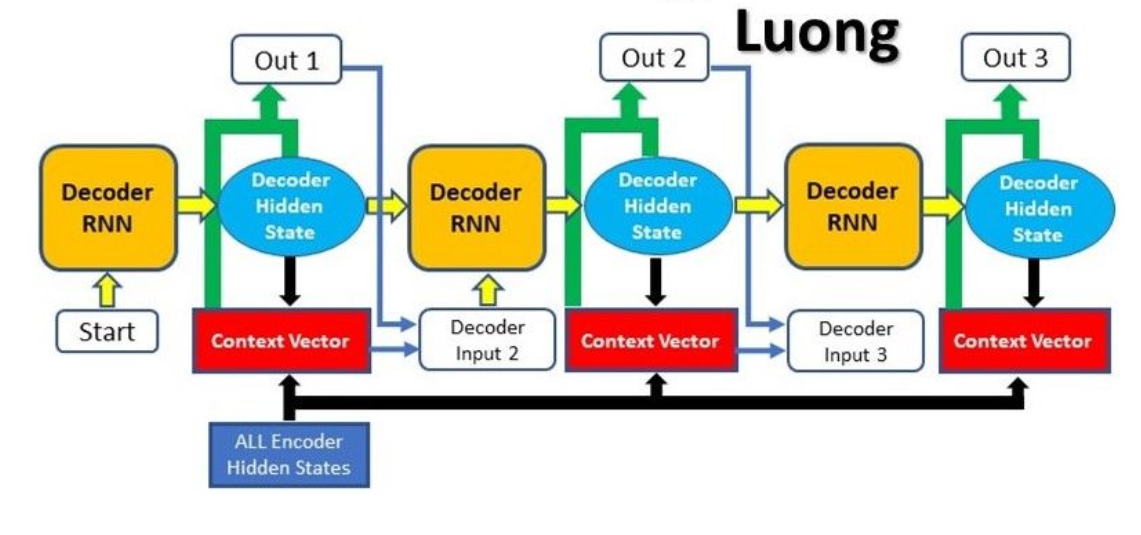
Luong Attention !
Luong’s Attention ! Table Of Contents: What Is Luong’s Attention? Key Features Of Luong’s Attention Model? Advantages Of Luong’s Attention Model? Architecture Of Luong’s Attention Model. Why do We Take the Current Hidden State Output Of The Decoder In Luong’s Attention Model? Architecture Luong’s Attention Model. Difference In Luong’s Attention & Bahdanau’s Attention (1) What Is Luong’s Attention? Luong’s attention is another type of attention mechanism, introduced in the paper “Effective Approaches to Attention-based Neural Machine Translation” by Minh-Thang Luong, Hieu Pham, and Christopher D. Manning in 2015. Luong’s attention mechanism is also designed for encoder-decoder models, similar to Bahdanau’s
-
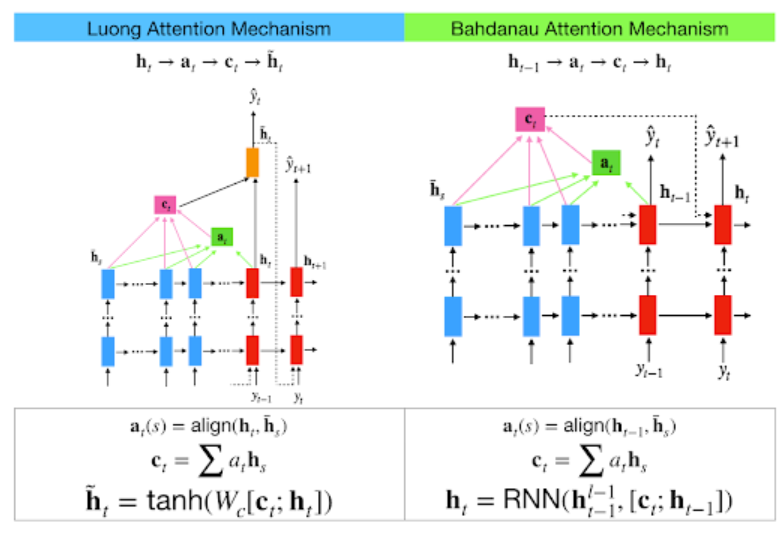
Bahdanau Attention Vs Luong Attention !
Bahdanau Attention ! Table Of Contents: What Is Attention Mechanism? What Is Bahdanau’s Attention? Architecture Of Bahdanau’s Attention? (1) What Is Attention Mechanism? An attention mechanism is a neural network component used in various deep learning models, particularly in the field of natural language processing (NLP) and sequence-to-sequence tasks. It was introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017. The attention mechanism allows a model to focus on the most relevant parts of the input when generating an output, rather than treating the entire input sequence equally. This is particularly useful when the
-

What Is Attention Mechanism?
What Is Attention Mechanism? Table Of Contents: Problem With Encoder & Decoder Architecture. Solution For Encoder & Decoder Architecture. Math’s Behind Attention Mechanism. Improvements Due To Attention Mechanism. (1) Problem With Encoder & Decoder Architecture. Problem With Encoder: The main idea behind the Encoder & Decoder architecture is that, the encoder summarize the entire text into one vector format and from that vector we need to convert into different language. Let us consider the below example, Your task is to read the entire sentence first, keep all the words in mind and translate it into Hindi without seeing the sentence
-
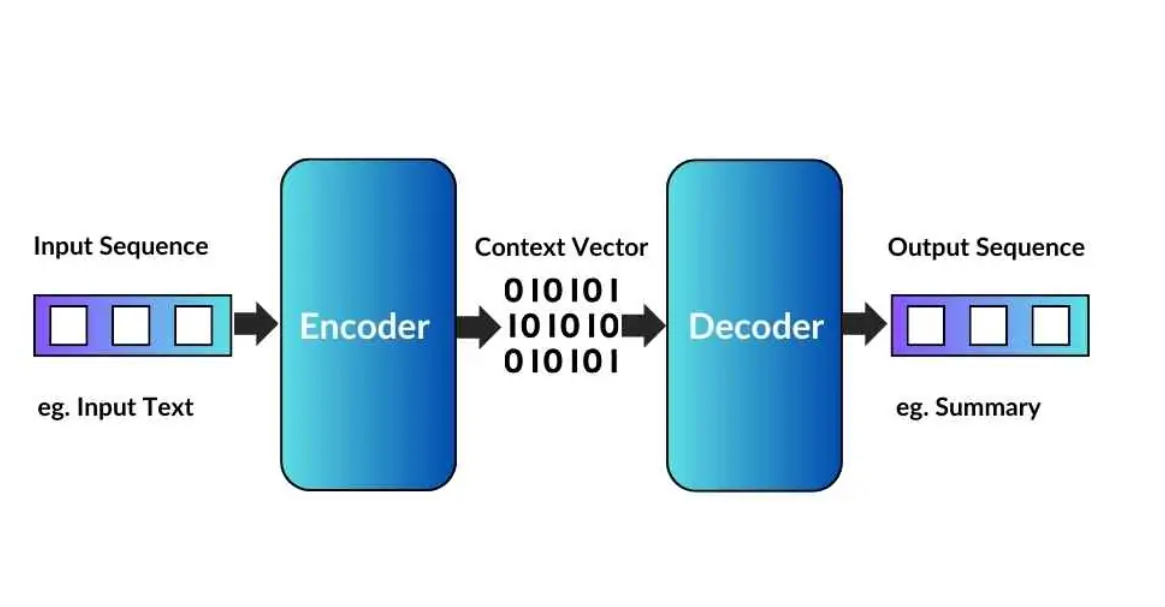
Encoder Decoder Architecture
Encoder Decoder Architecture Table Of Contents: Milestones In Deep Learning. What Is Sequence To Sequence Model? Problem With LSTM Networks. Challenges To Handle Sequence To Sequence Data. How Does LSTM Network Can Handle Variable Length Input ? How Does LSTM Network Can Handle Variable Length Output With Some Trick? Why Does The LSTM Don’t Have The Decision Making Capability ? Challenges To Handle Sequence To Sequence Data. High-level Overview Of Encoder Decoder Architecture. What Is Inside Encoder Module? What Is Inside Decoder Module? How To Train Encoder & Decoder Architecture. Model Prediction (1) Milestones In Deep Learning ? Milestone-1: In
