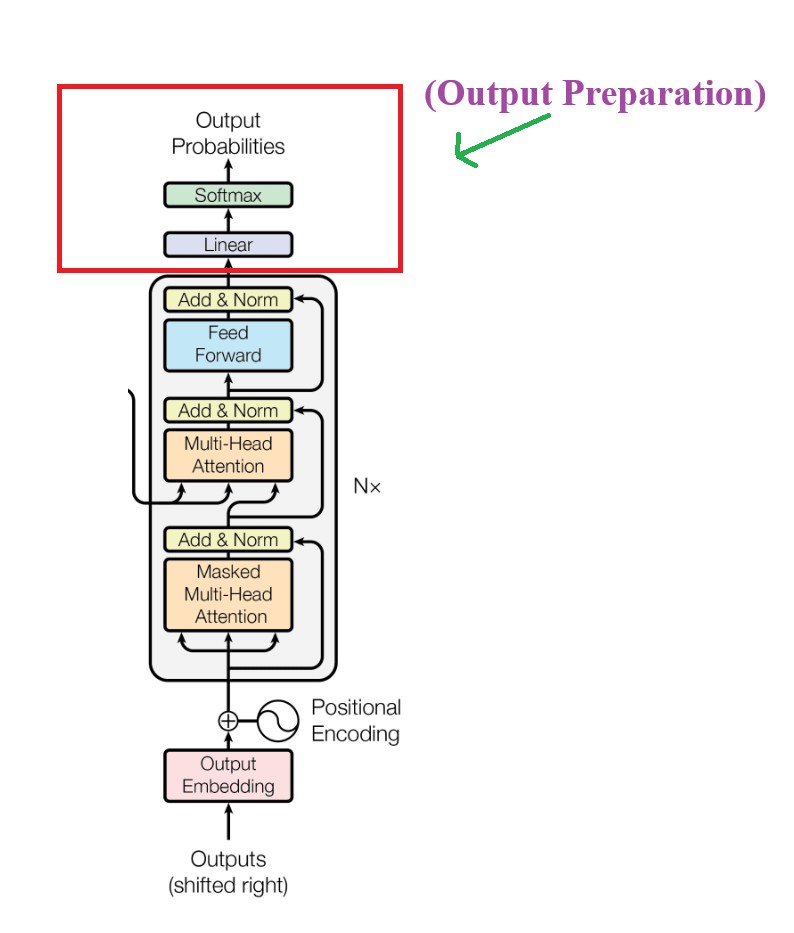
In a Transformer model, the Decoder plays a crucial role in generating output sequences from the encoded input.
It is mainly used in sequence-to-sequence (Seq2Seq) tasks such as machine translation, text generation, and summarization.
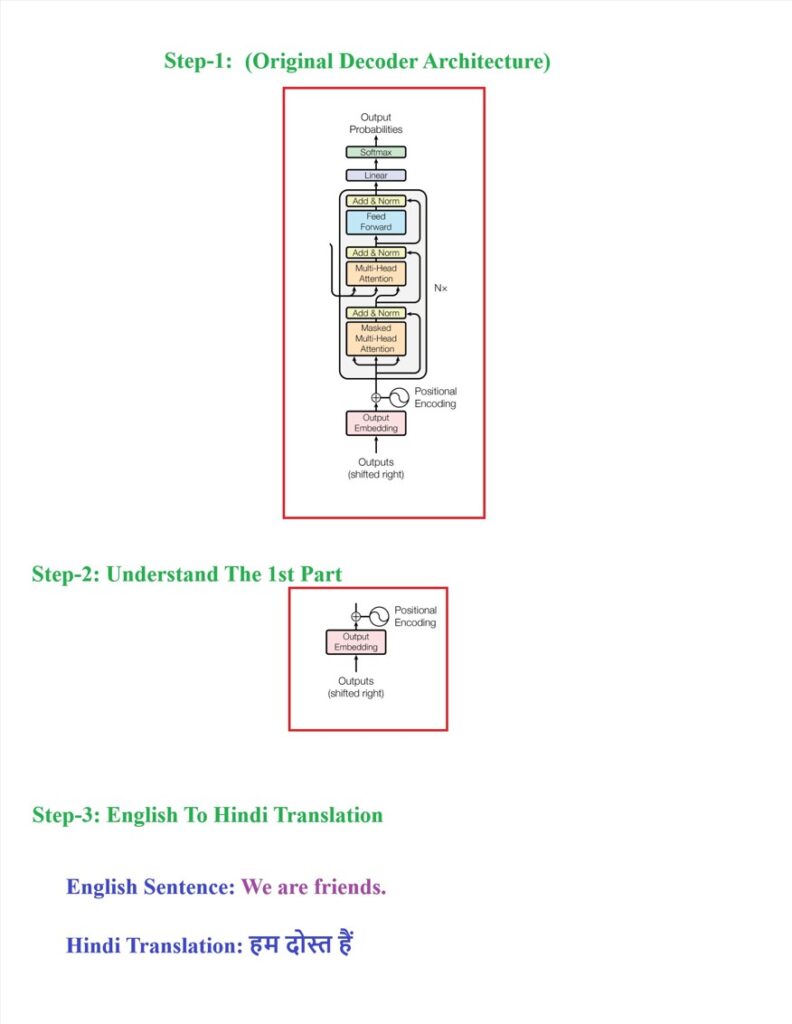
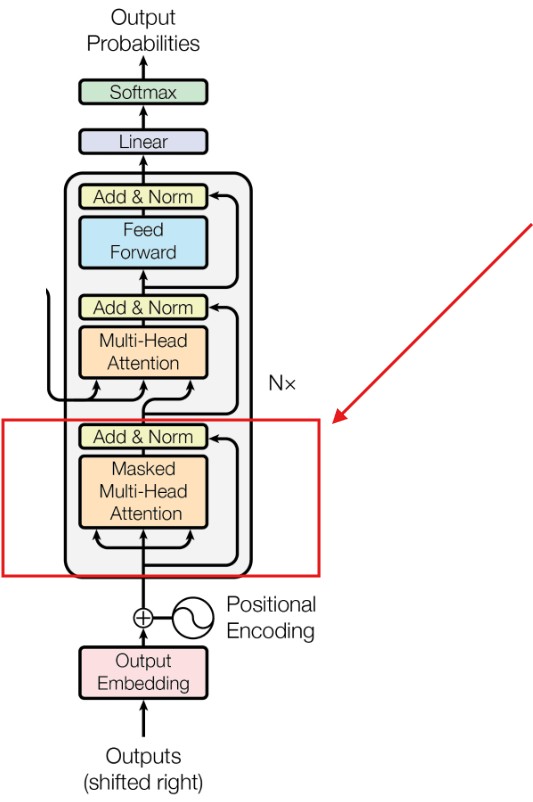
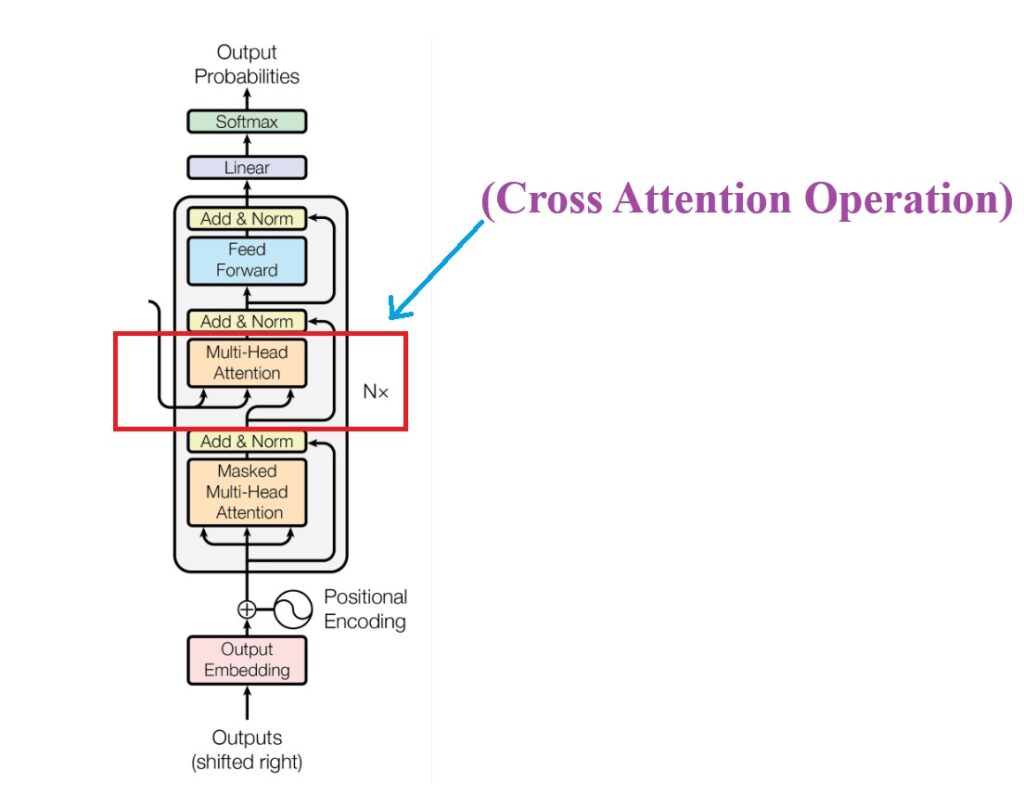
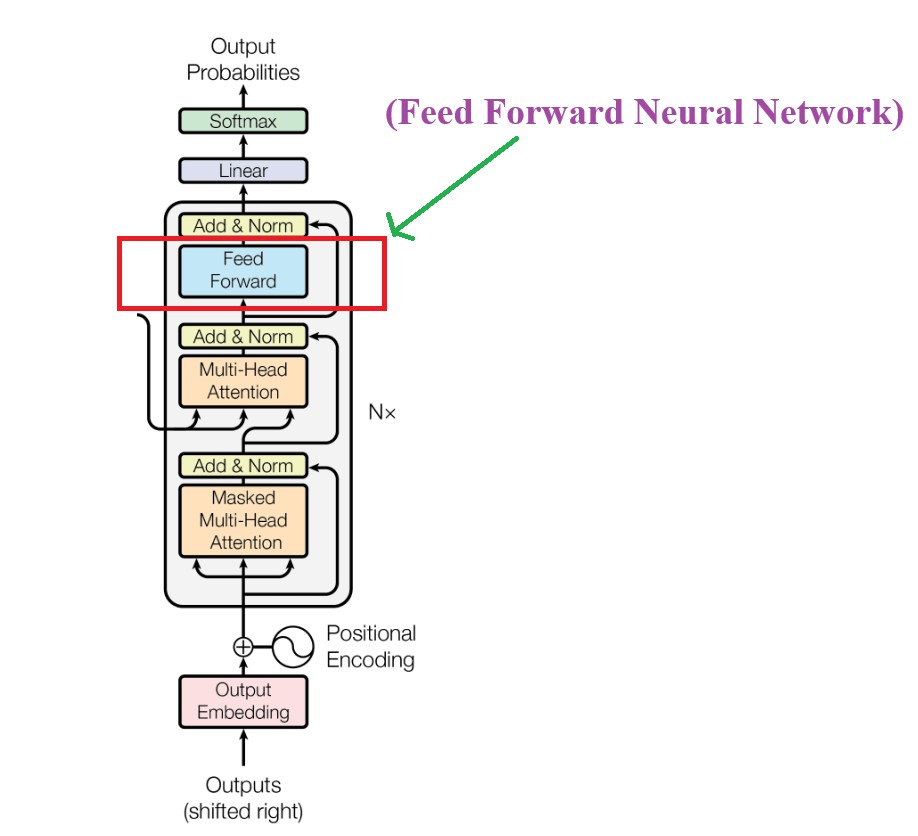
(2) Overall Decoder Architecture.
In the original paper of Transformer we have 6 decoder module connected in series.
The output from one decoder module will be passed to the input the another decoder module.
Three main components of decoder module are:
Masked Self Attention
Cross Attention
Feed Forward Neural Network.
(3) Understanding Decoder Work Flow With An Example.
Encoder Input & Output:
Now we will see how the decoder module works ?
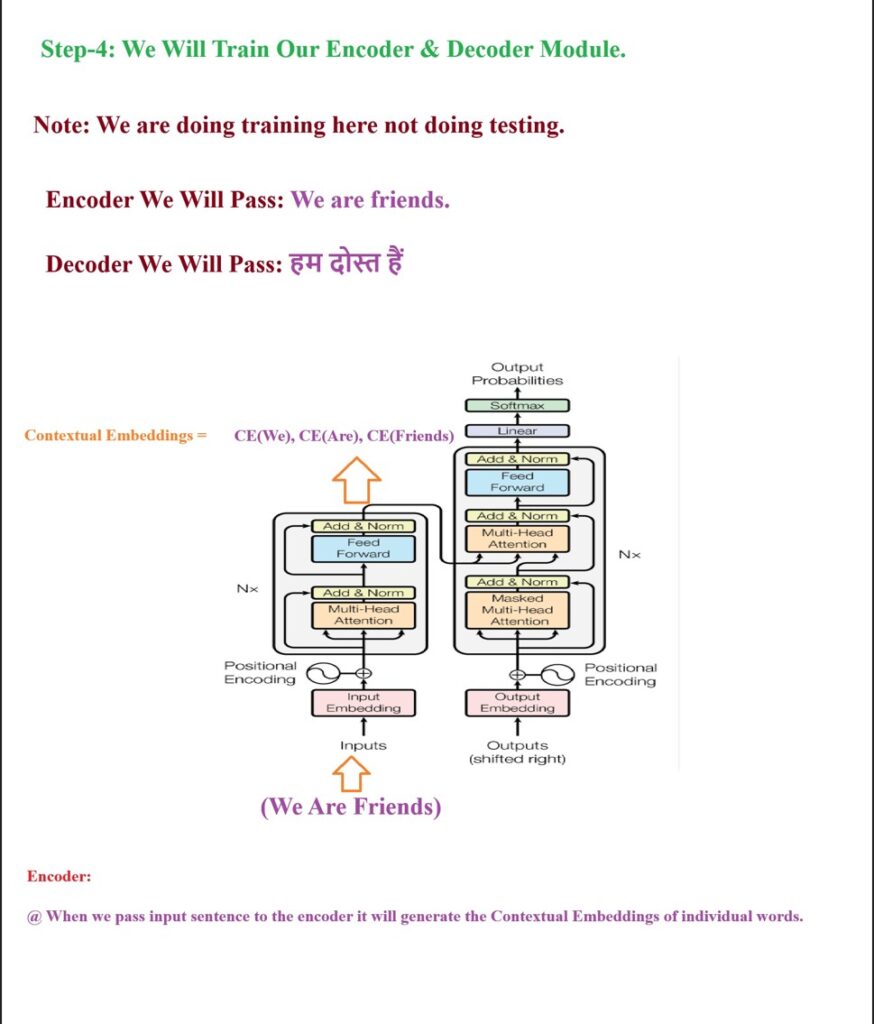
Before entering into the Decoder first we will pass the English sentence to the encoder module and it will produce the contextual word embedding values for each word.
We have passed “We are friends” to the encoder module and it will produce the contextual positional word embeddings for each word.
We will combine all these contextual positional word embedding vectors and form a 3 * 512 shape matrix.
Decoder Input:
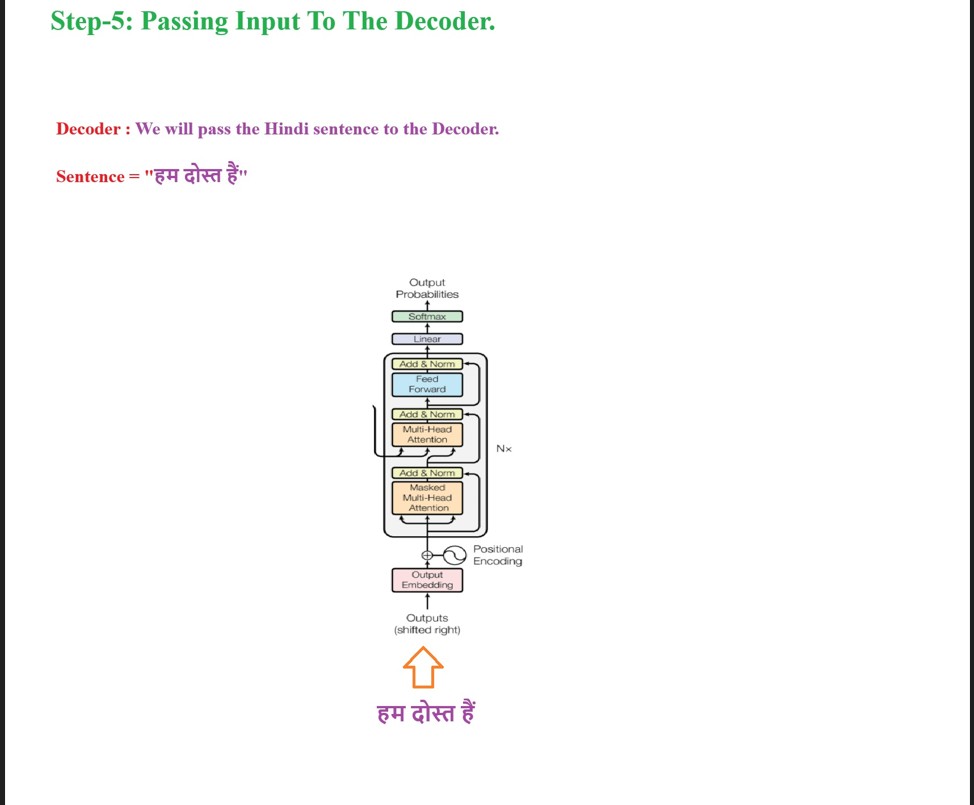
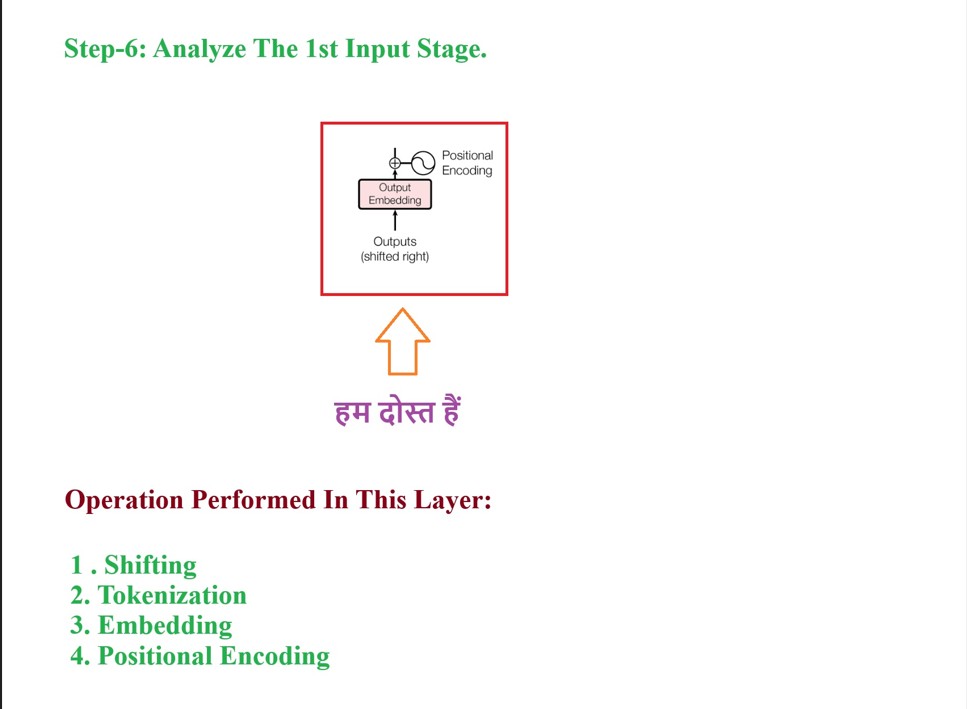
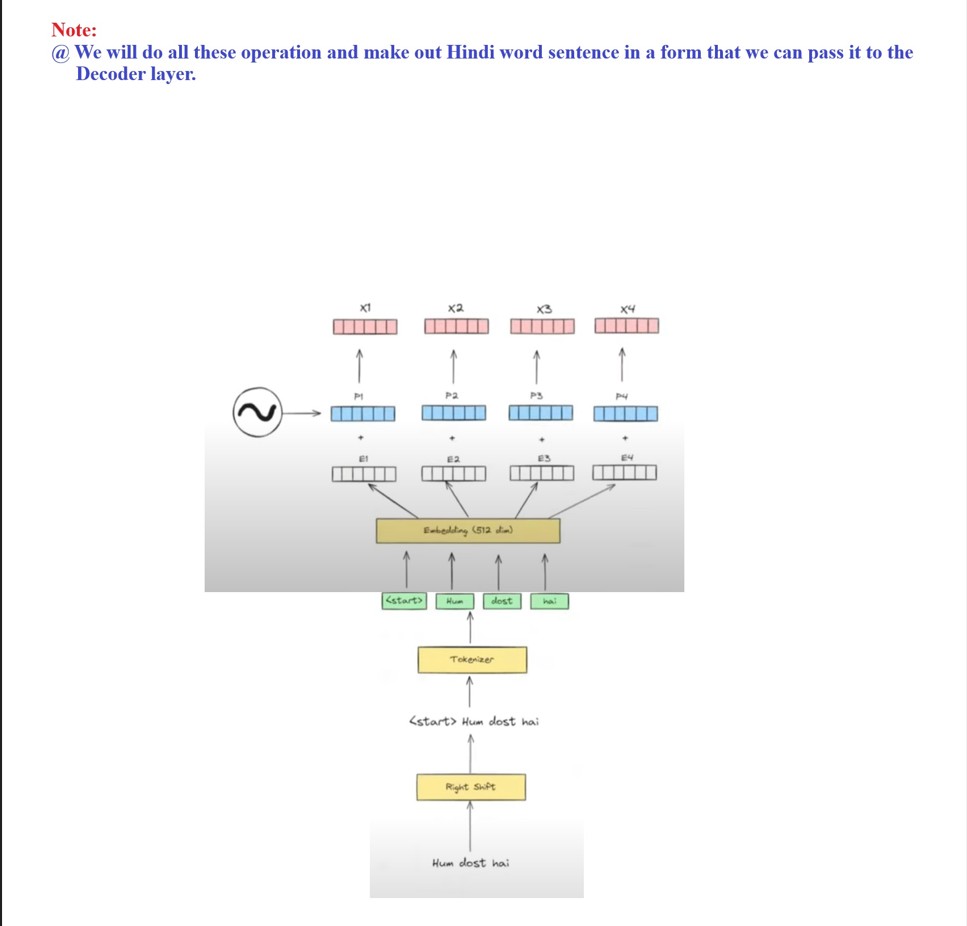
Before giving the input to the decoder we have to process the raw input in our case it is “Hindi” sentence.
Step-1: We will pass our prepared input embedding vectors to the Masked Multi Head Attention block.
Step-2: The Masked Multi Head Attention block will generate the contextual word embeddings of the individual word vectors.
Step-3: While generating the contextual word embedding for the word <Start> the Masked Multi Head Attention block will only consider the <Start> word and it will not consider the “hum”, “dost”, “hai”, because these are the future words.
Step-4: While generating the contextual word embedding for the word “Hum” the Masked Multi Head Attention block will only consider the <Start> and “Hum” words and it will not consider the “dost”, “hai” because these are the future words.
Step-5: Finally it will generate (Z1, Z2, Z3, Z4) as an output vectors.
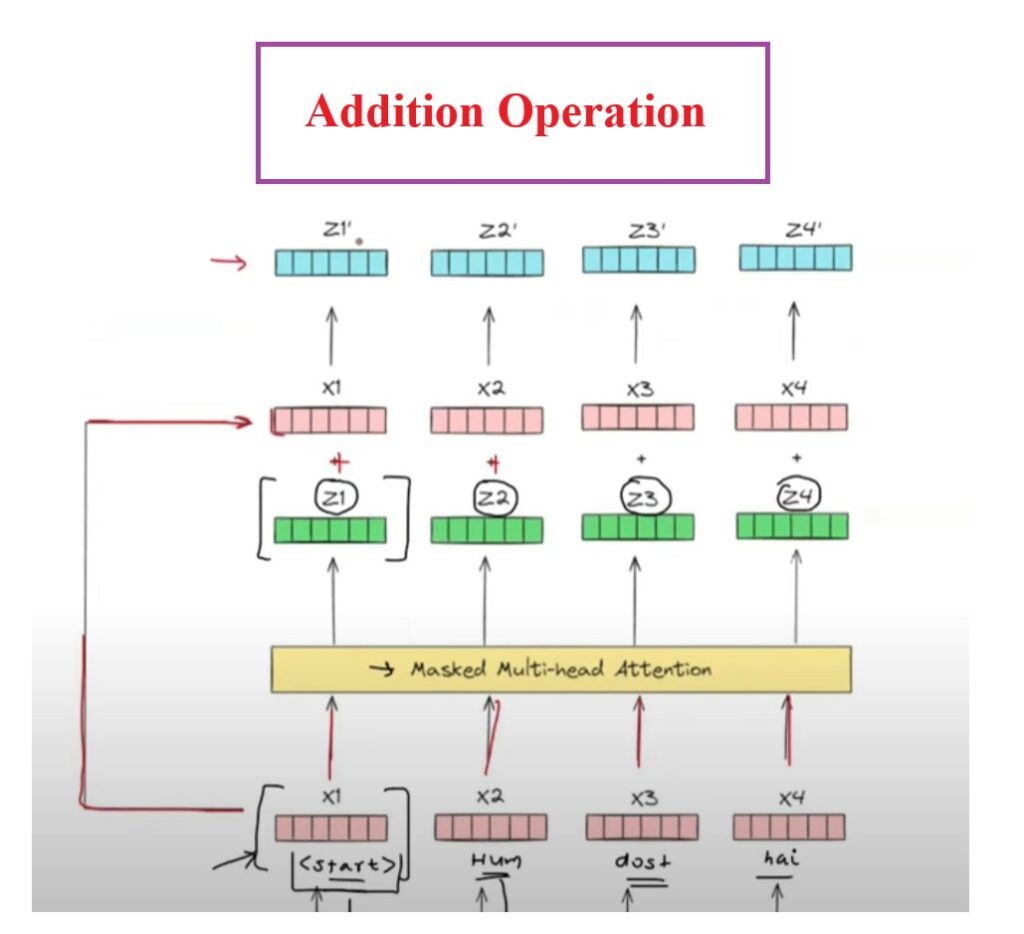
Step-2: Addition Operation
The second step is the Addition operation.
This will add the original input vectors (X1, X2, X3, X4) with the Masked Multi Headed Attention vector (Z1, Z2, Z3, Z4).
Finally we will get another set of vectors which are (Z1′, Z2′, Z3′) which will have the flavor of original input and the contextual embedding input.
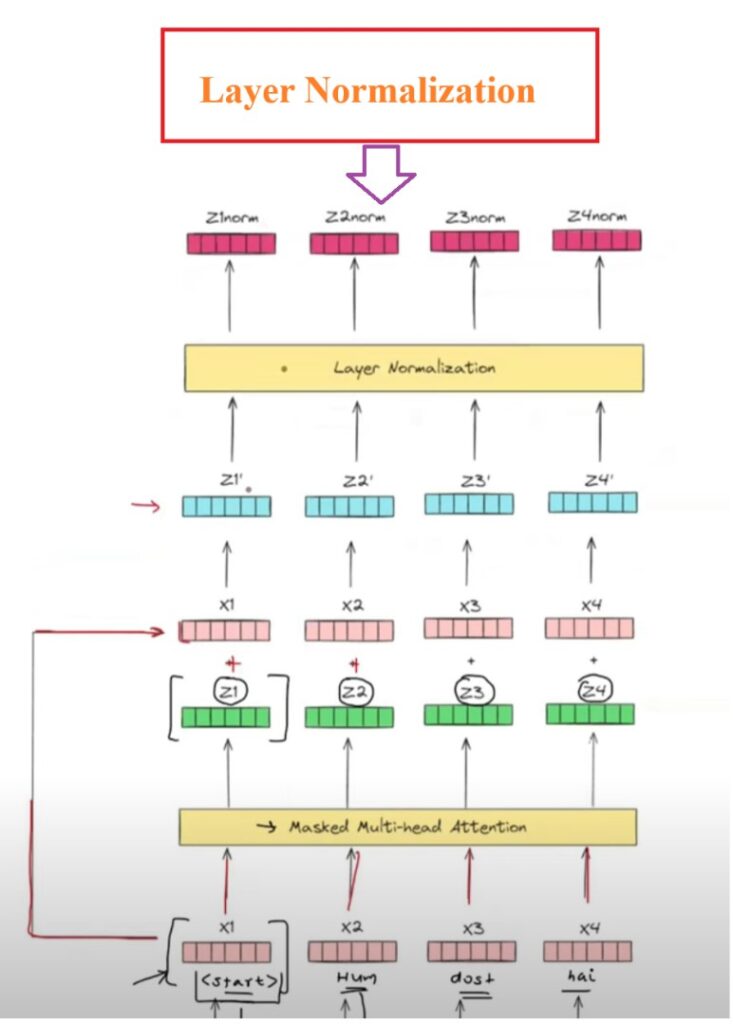
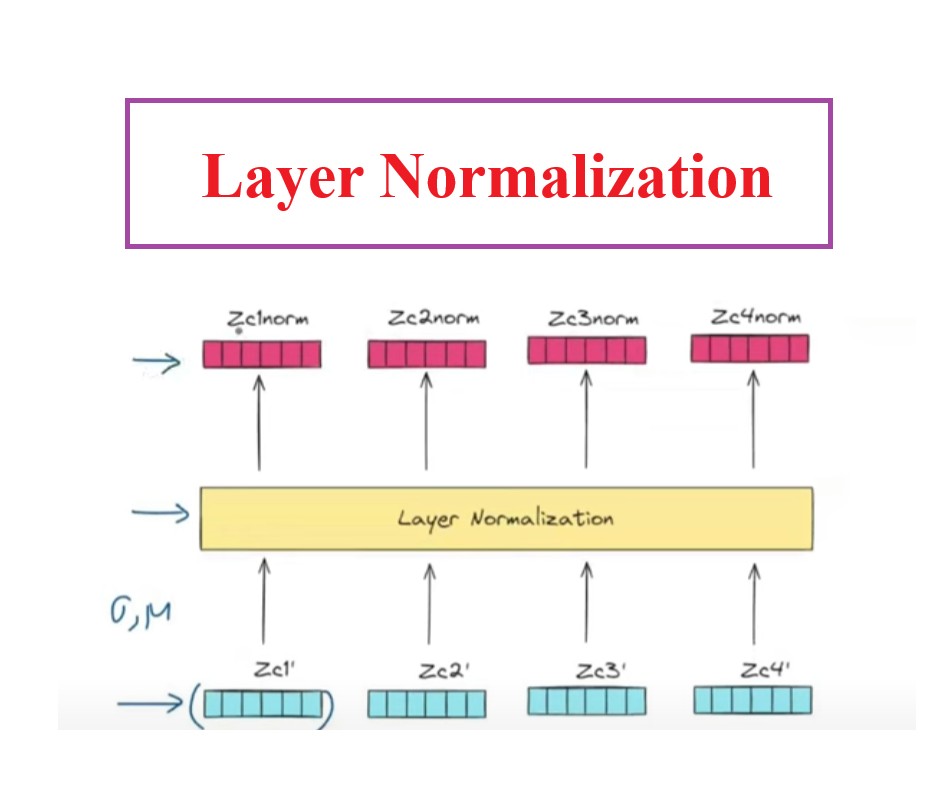
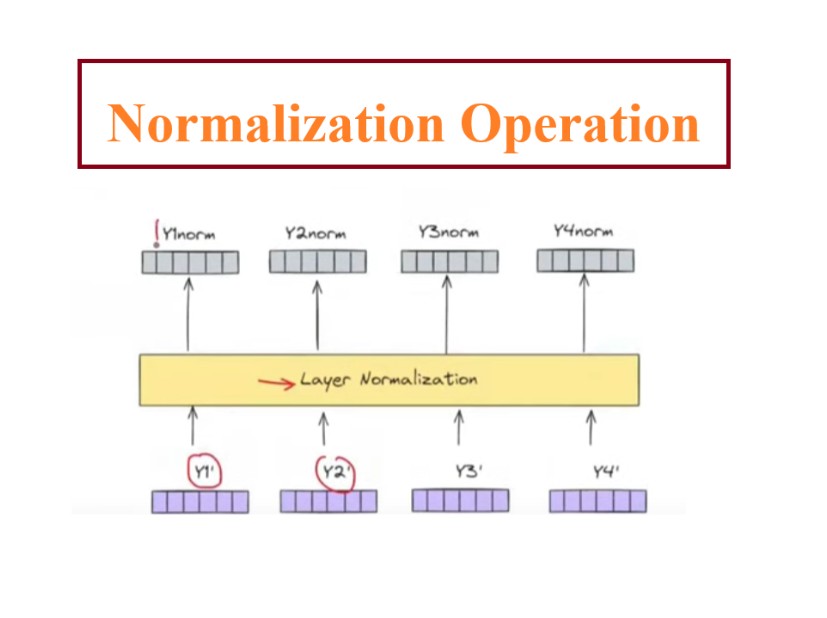
Step-3: Layer Normalization
The 3rd step will be our layered normalization process.
This module will calculate the μ and σ for each vector and apply normalization to individual digits of that vector.
We are normalizing our output vectors to stabilize the training process, if we don’t normalize we will face exploding gradient problem in training process.
We will get output as Z1norm, Z2norm, Z3norm, Z4norm.
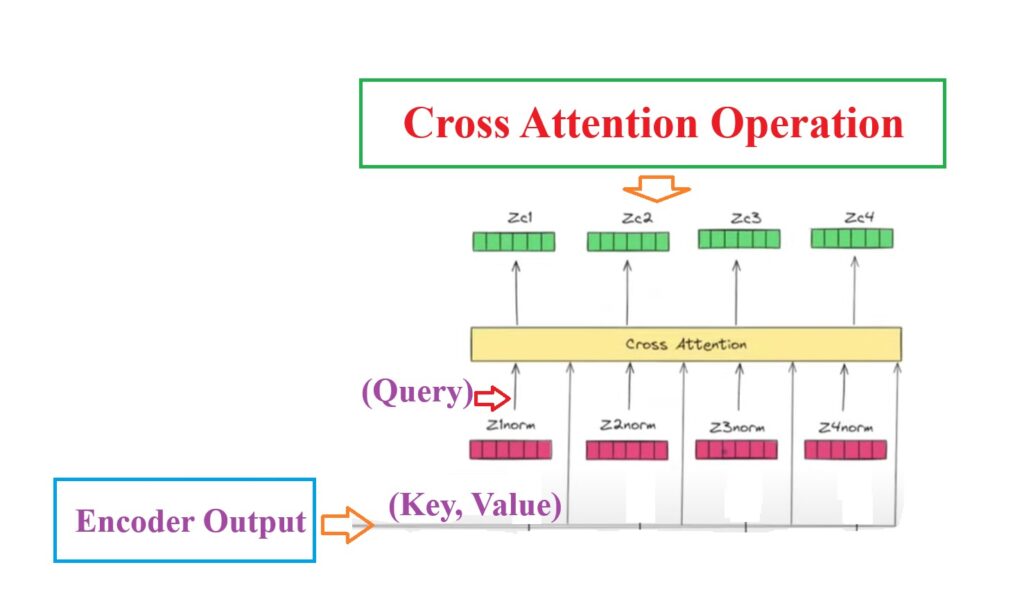
Step-4:Cross Attention Operation
The 4th operation will be our Cross Attention operation.
Cross attention operation will find out the similarity between input and the output sequence.
Cross attention technique is needed because to predict the next word we need to establish the relationship between the input word sequence in out case it is “We are friends” and output word sequence “hum dost he”.
Hence we are giving two different connection to the Cross Attention module , one is from encoder module and another is from decoder module.
Output of the decoder block will be the Contextual Word Embedding values for individual words.
from each word from the encoder output we will generate the Key and Value pair and pass it to the decoder block.
To get the Query vector we will use the output sentence words in our case Hindi words and pass it to the decoder block.
We are able to capture the relationship between the input sentence and the output sentence by taking the Key and Value vectors from the input sentence word and the Query vector from the output sentence word.
Finally we will get the contextual word embedding vectors as Z1′, Z2′ Z3′ as an output.
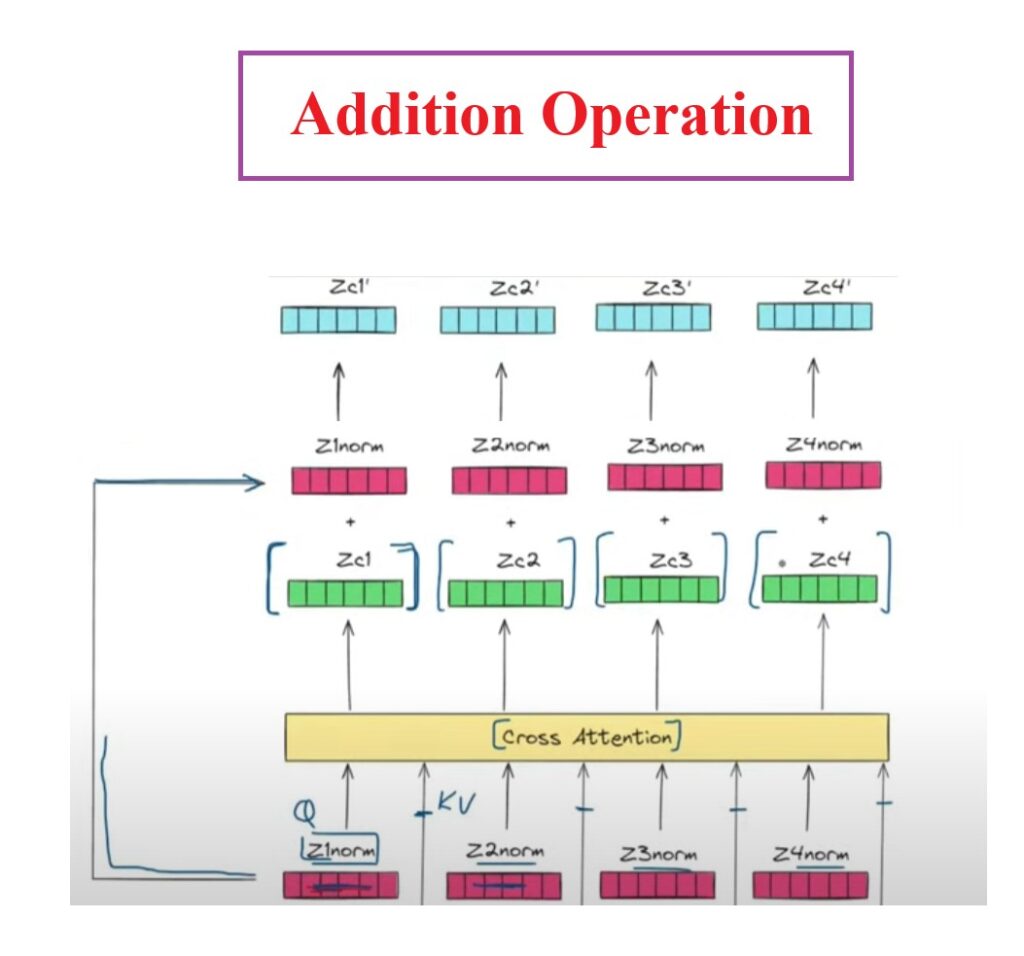
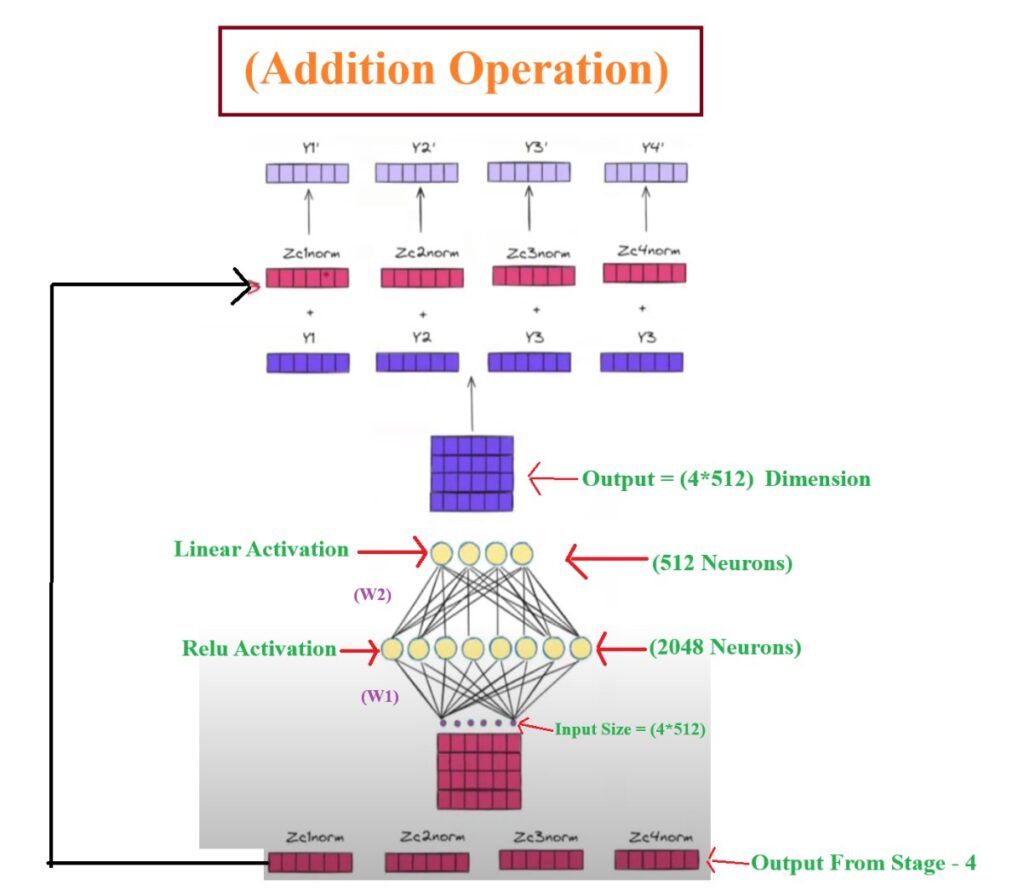
Step-5: Addition & Normalization Operation
Once we do any changes or operation to our input sequence we again need to add the original input back to the transformed input to retain the original input sequence.
Here we are adding (Zc1, Zc2, Zc3) to the (Z1norm, Z2norm, Z3norm).
Finally we will get Zc1′, Zc2′, Zc3′ as an output.
We will do the Layer Normalization of the output vectors to bring them into a particular range.
We will calculate μ and σ for each vector and apply normalization to individual digits of that vector.
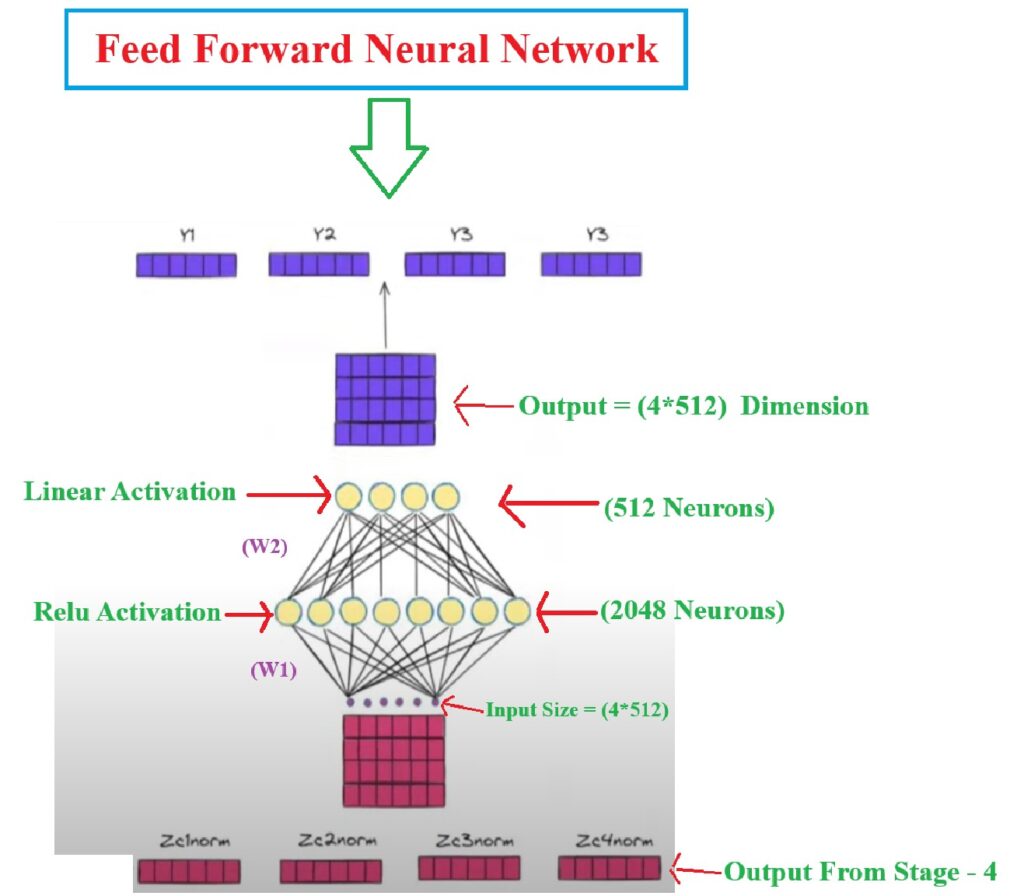
Step-6: Feed Forward Block
Now we will pass our output to the Feed Forward Neural network module.
This will add some non linearity to out model.
Step-7: Add & Normalization
Y1norm, Y2norm, Y3norm, Y4norm will be the final output from the Decoder-1.
Step-8: Pass Output From Decoder 1 To The Rest Of 5 Decoder Module.
The output from the Decoder-1 will be passed to the Decoder-2 and like this we have to go till Decoder – 6.
All these Decoder architecture will be same but the parameters inside each decoder will be different.
Step-9: Final Output Preparation
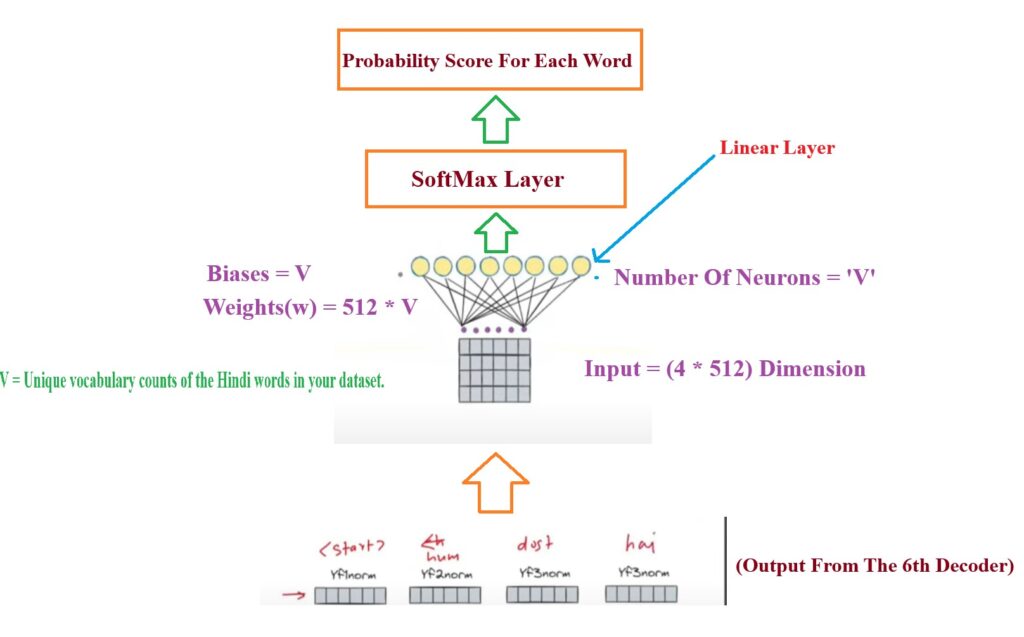
For each token from the Decoder module output I have to generate a Hindi word output.
The output layer consist of 2 parts.
Linear Layer.
Softmax Layer
Linear Layer:
Linear Layer : The linear layer is the output layer of the Feed Forward Neural network.
The number of neurons in the linear layer represents the total number of unique words in the Hindi sentence.
Each unit in the Linear Layer represents individual unique words in the Hindi vocabulary.
If in our dataset we have 1000 unique Hindi words then V = 1000.
Suppose we pass the first input <Start> as input to the Linear Layer, its size will be <Start> = (1*512).
Suppose we have 1000 unique Hindi words in our dataset, V = 1000.
The dimension of the Weights = (512 * 1000)
Now we will multiply our input of (1*512) with the weight of (512 * 1000).
Output From Linear Layer = (1*512).(512*1000) = (1*1000)
Softmax Layer:
This (1*1000) matrix can be of any number, we need to convert it into probability score between 0 to 1.
Hence we will pass this (1 * 1000) matrix to the Softmax layer.
The Softmax layer will produce the probability score of 1000 units in the Linear Layer.
The unit or node having maximum probability will be considered as the output word.
In our example if we pass <Start>, suppose we got probability values for every words like this, hum = 0.35, doost = 0.12, he = 0.05, then we will choose “Hum” as an output because it has highest probability score.
Similarly we will send “Hum” as input to the Linear Layer and got probability of ‘doost’ = 0.56 which is highest, then we will choose ‘doost’ as an output.
Until we got <End> as in output we will continue this step.