GenAI – How Do You Solve If Your LLM Evaluation Is Subjective & Inconsistent ?
Scenario:
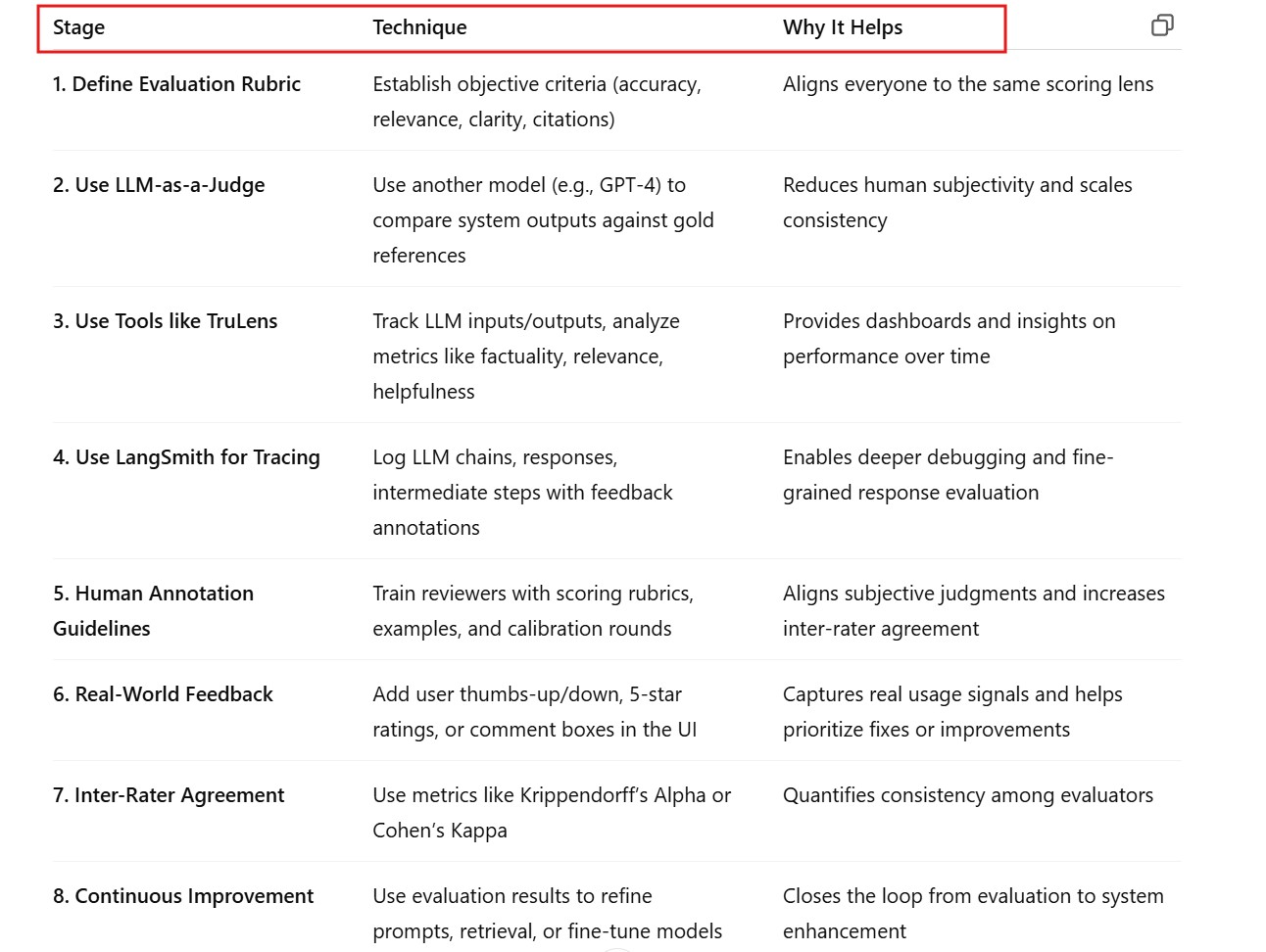
Your team struggles to evaluate LLM responses consistently. Some reviewers give different scores for the same answers. What do you do?
Answer:
Example LLM-as-a-Judge Prompt (OpenAI GPT-4):
You are an expert evaluator. Given a question, a ground truth answer, and an LLM-generated answer, score the generated answer on accuracy, relevance, and completeness from 1 to 5. Justify each score briefly.