from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments, DataCollatorForLanguageModeling
from datasets import load_dataset, Dataset
from peft import get_peft_model, LoraConfig, TaskType, prepare_model_for_kbit_training
import torch
# Step 1: Load tokenizer and base model
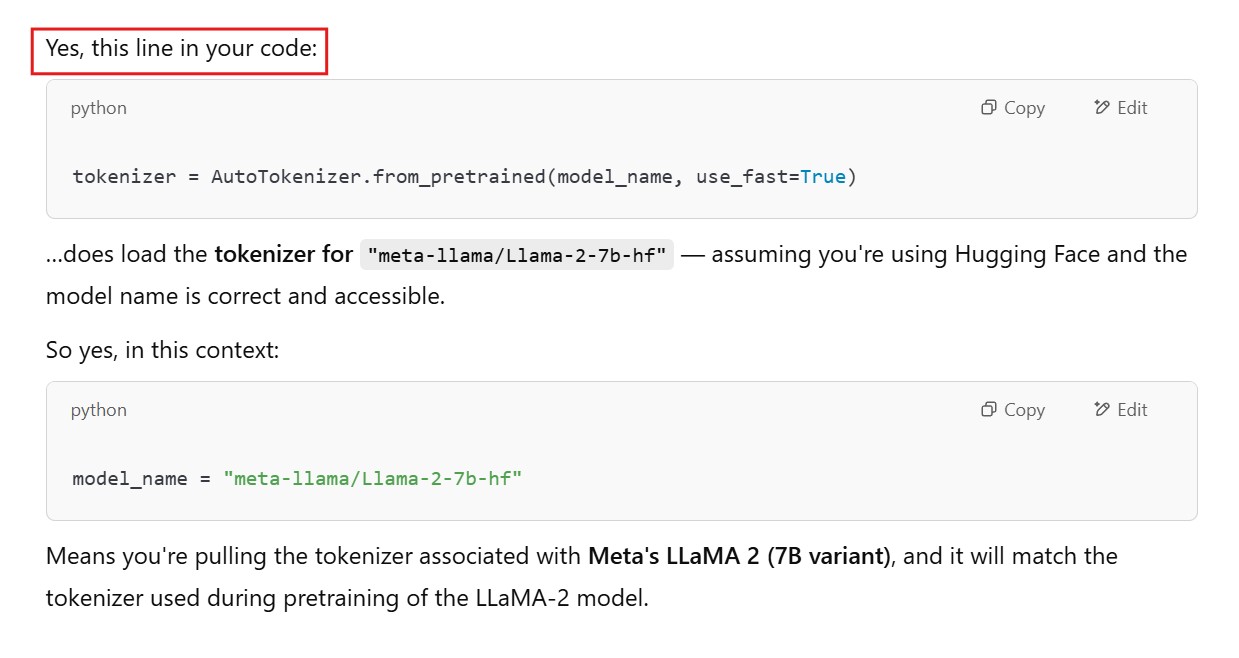
model_name = "meta-llama/Llama-2-7b-hf" # Or another open model
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True, device_map="auto") # Quantized loading
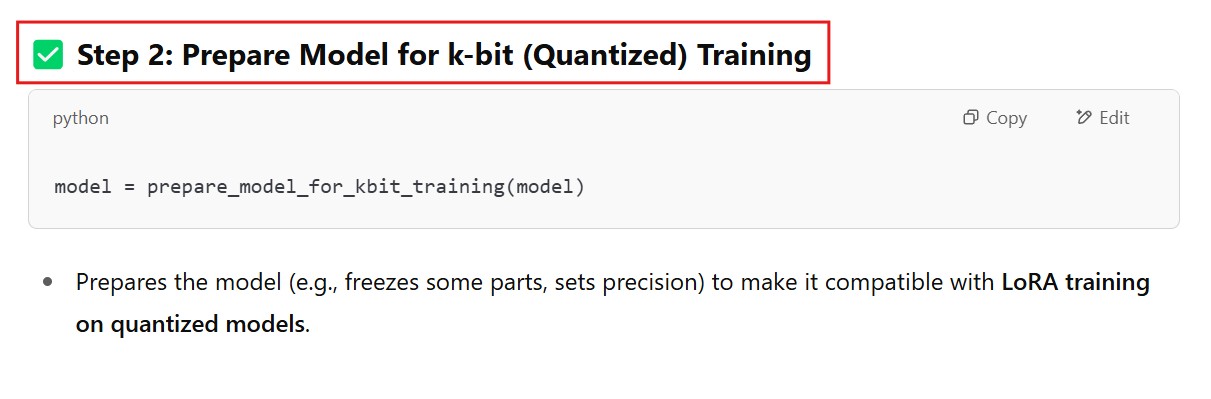
# Step 2: Prepare model for LoRA training
model = prepare_model_for_kbit_training(model)
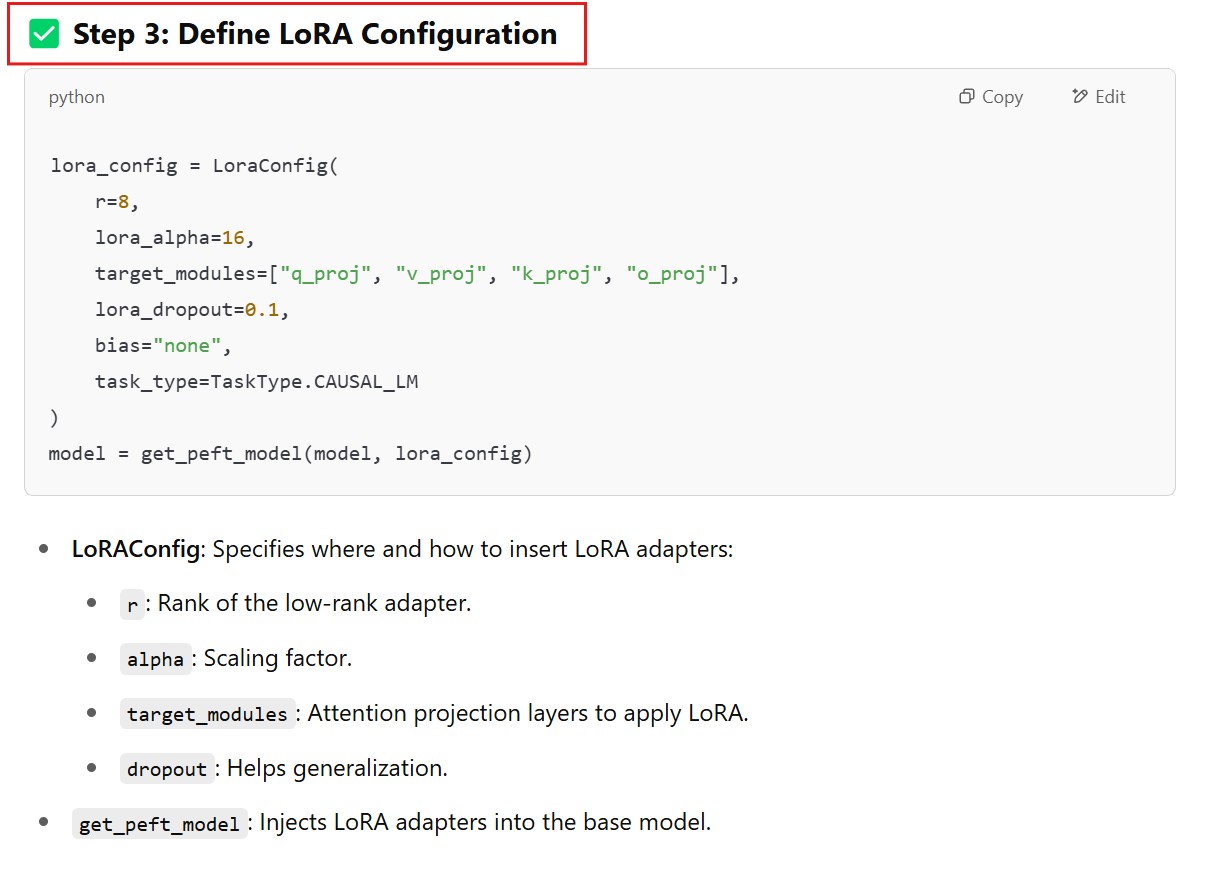
# Step 3: Set up LoRA configuration
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"], # Update based on architecture
lora_dropout=0.1,
bias="none",
task_type=TaskType.CAUSAL_LM
)
# Apply LoRA to the model
model = get_peft_model(model, lora_config)
# Step 4: Prepare your domain-specific dataset (example with sample data)
data = {
"text": [
"What is a contract? A contract is a legally binding agreement between two or more parties.",
"Define tort law. Tort law involves civil wrongs and damages to a person’s property or reputation.",
"Explain consideration in contract law. Consideration is the value exchanged between parties in a contract.",
]
}
dataset = Dataset.from_dict(data)
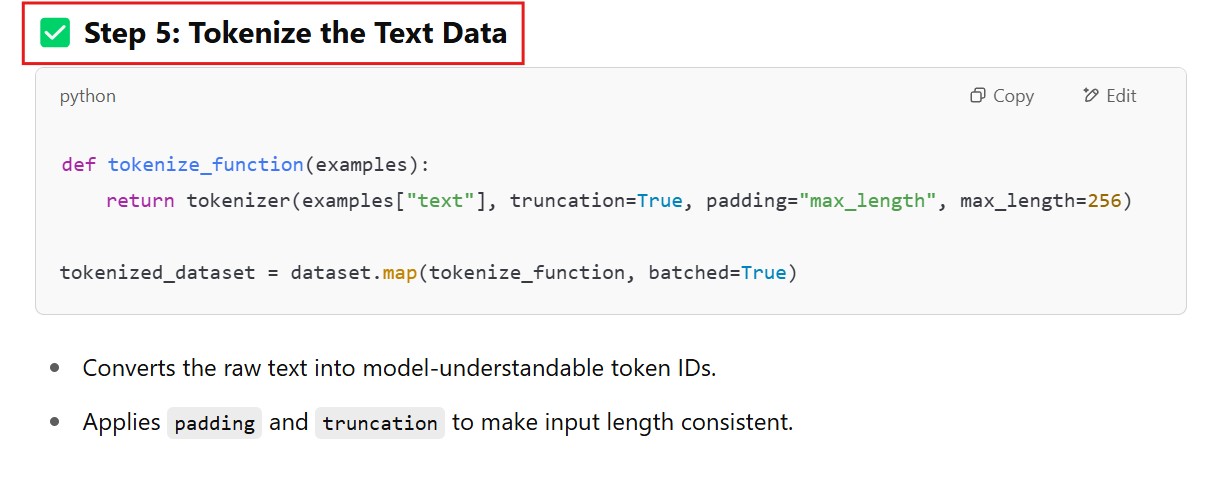
# Step 5: Tokenize the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=256)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
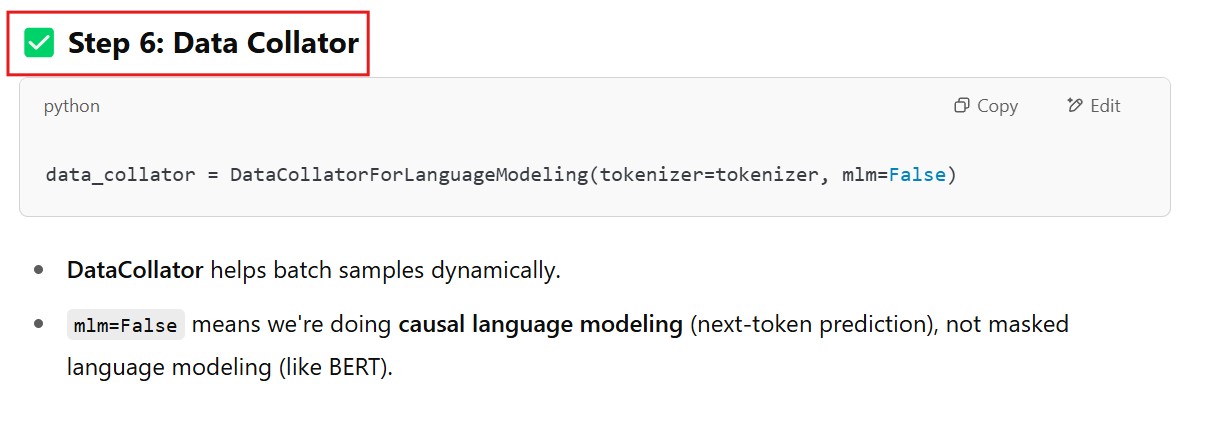
# Step 6: Data collator
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# Step 7: Define training arguments
training_args = TrainingArguments(
output_dir="./lora-llama-legal",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs=3,
learning_rate=2e-4,
logging_steps=10,
save_steps=50,
save_total_limit=2,
fp16=True,
evaluation_strategy="no",
report_to="none"
)
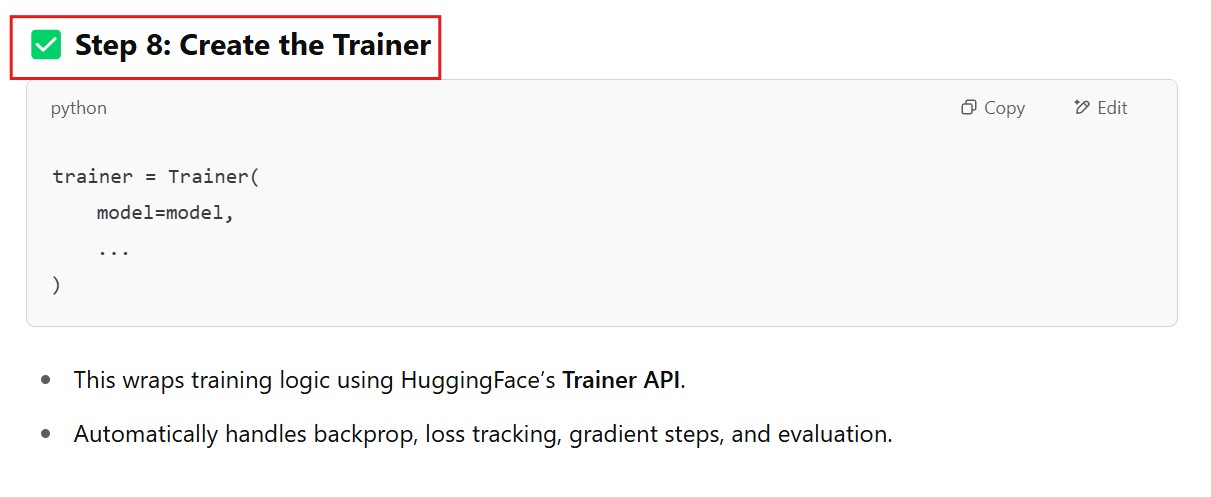
# Step 8: Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer,
data_collator=data_collator
)
# Step 9: Train!
trainer.train()
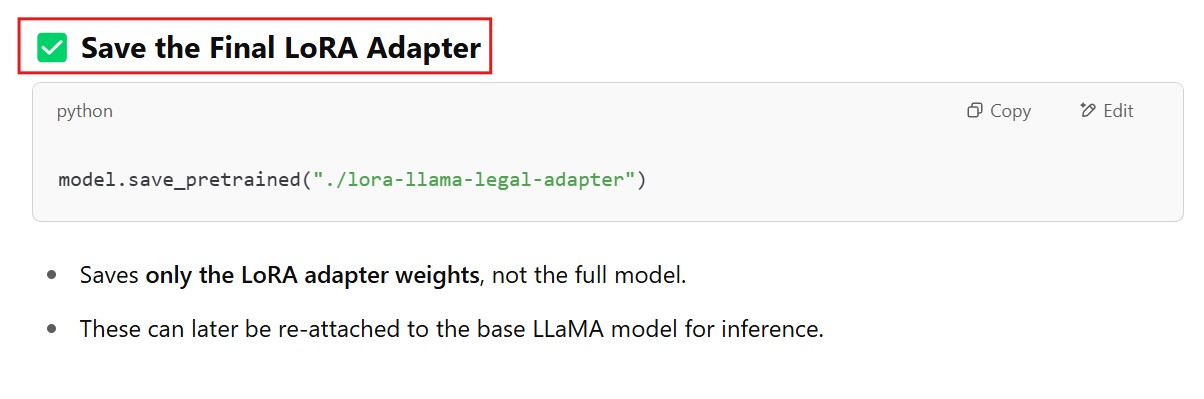
# Save final LoRA adapters
model.save_pretrained("./lora-llama-legal-adapter")