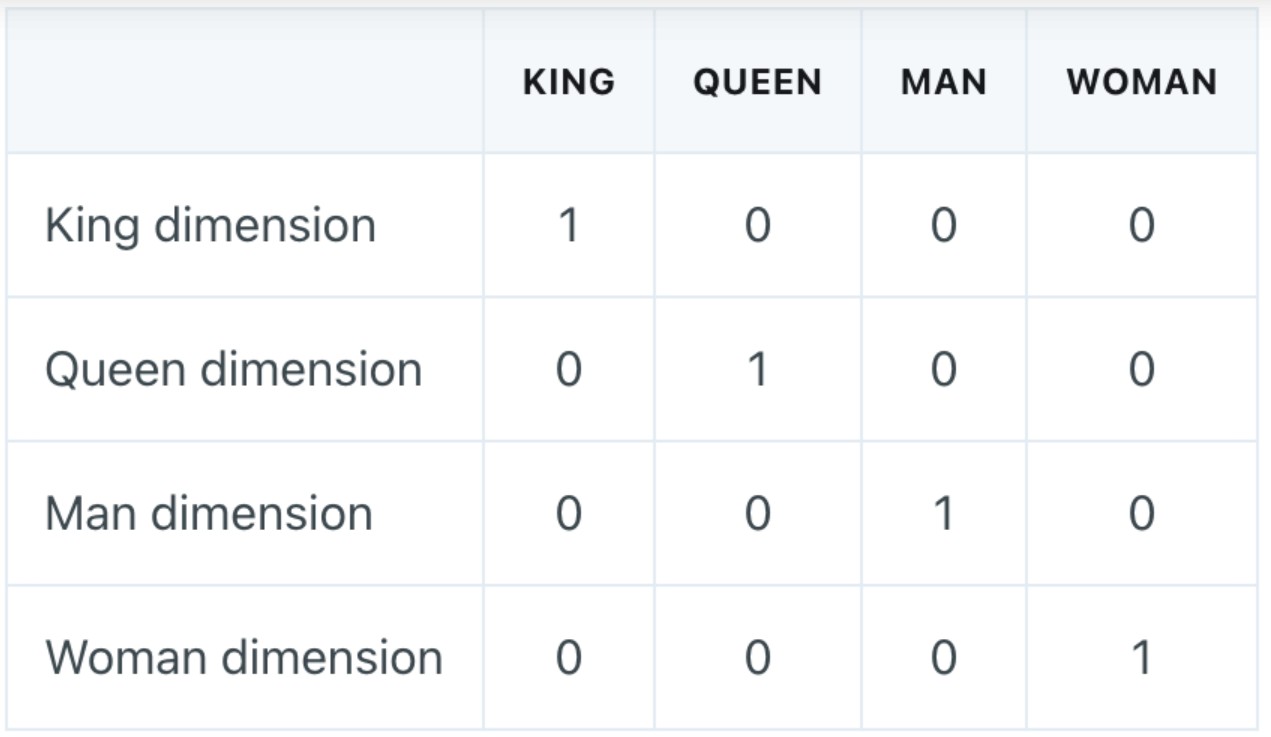
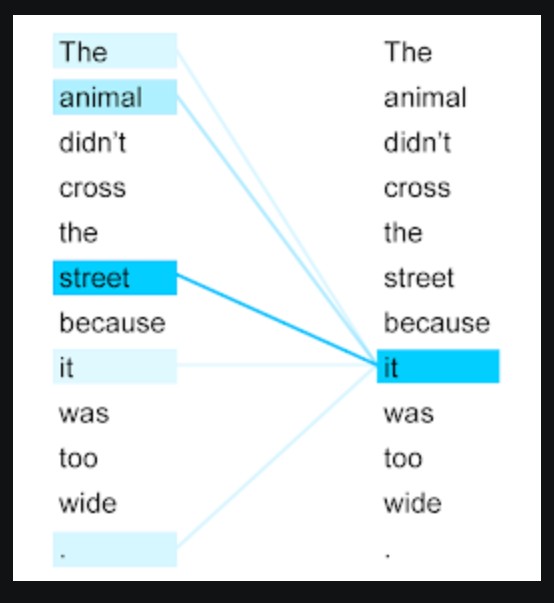
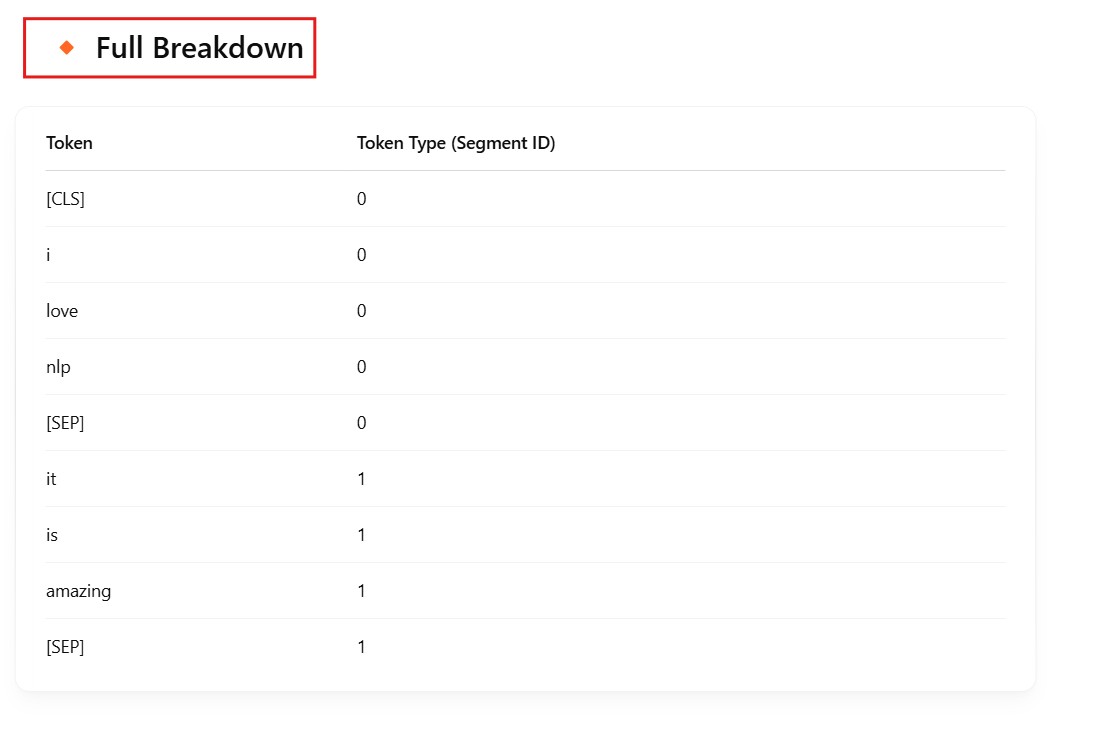
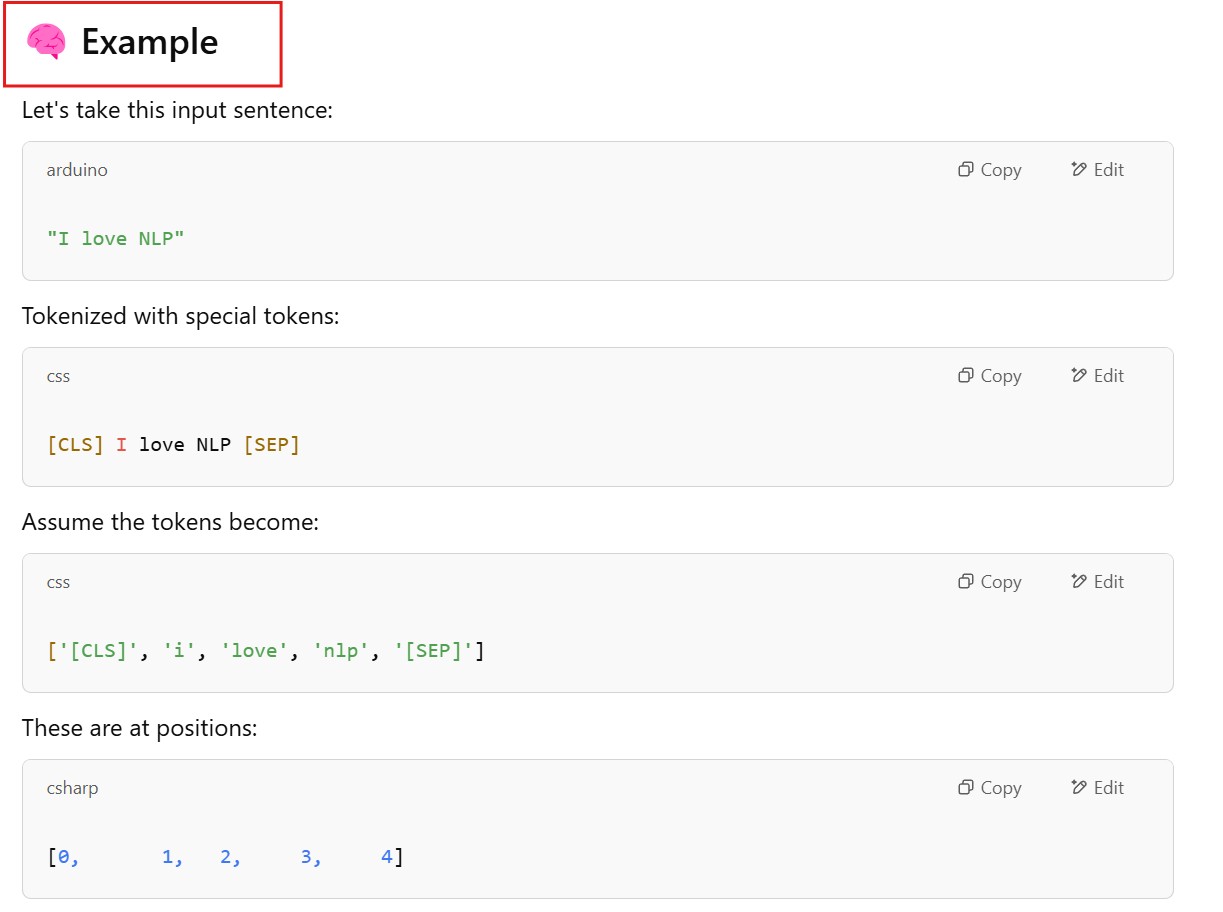
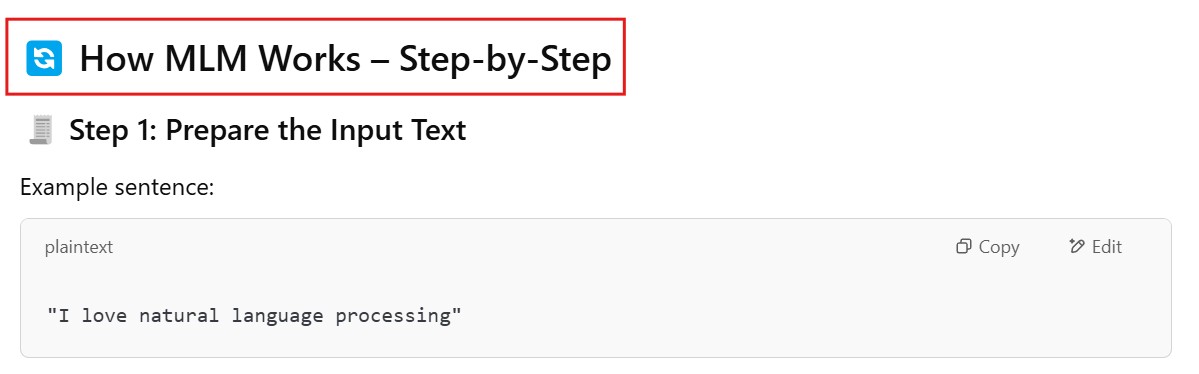
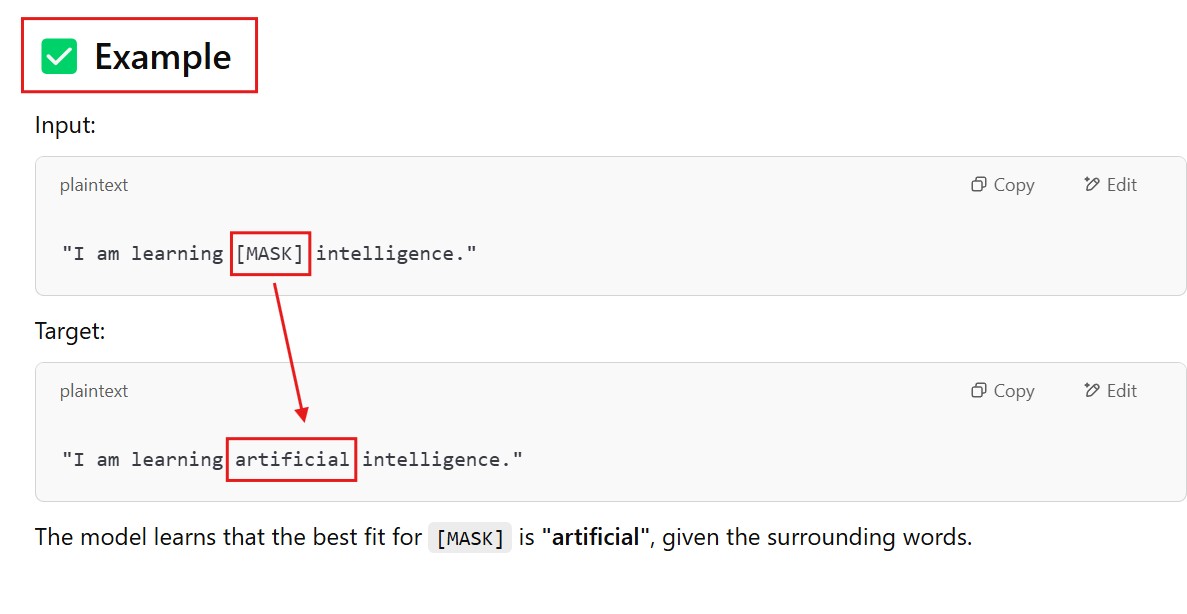
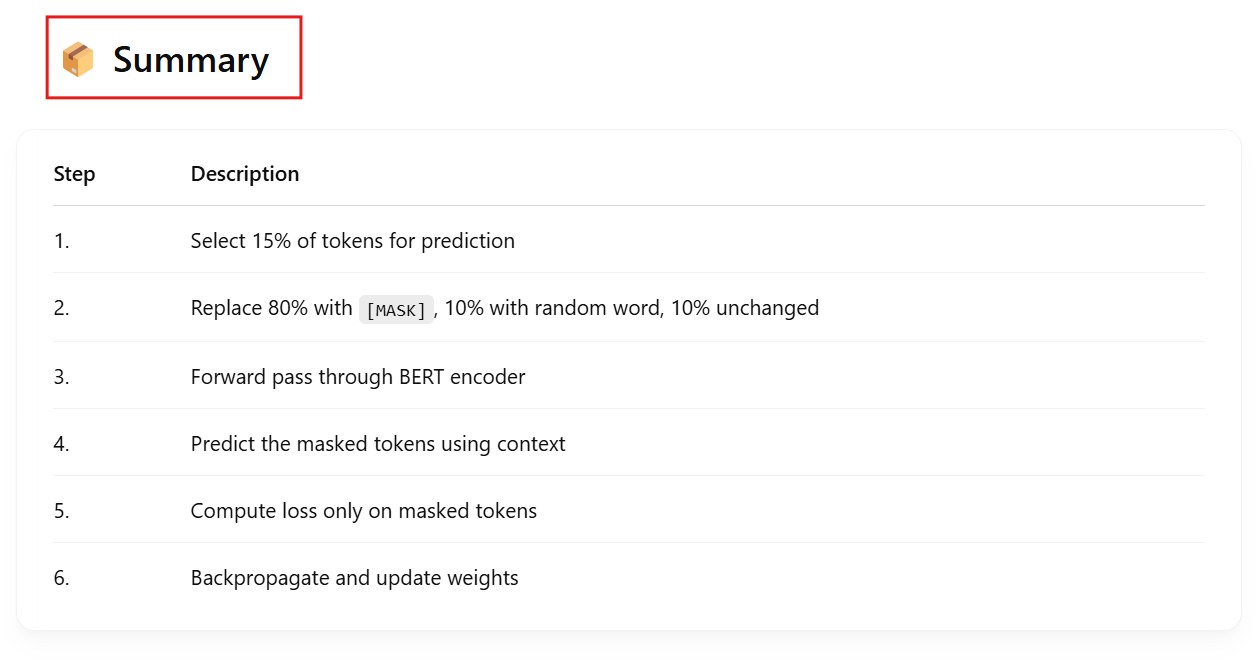
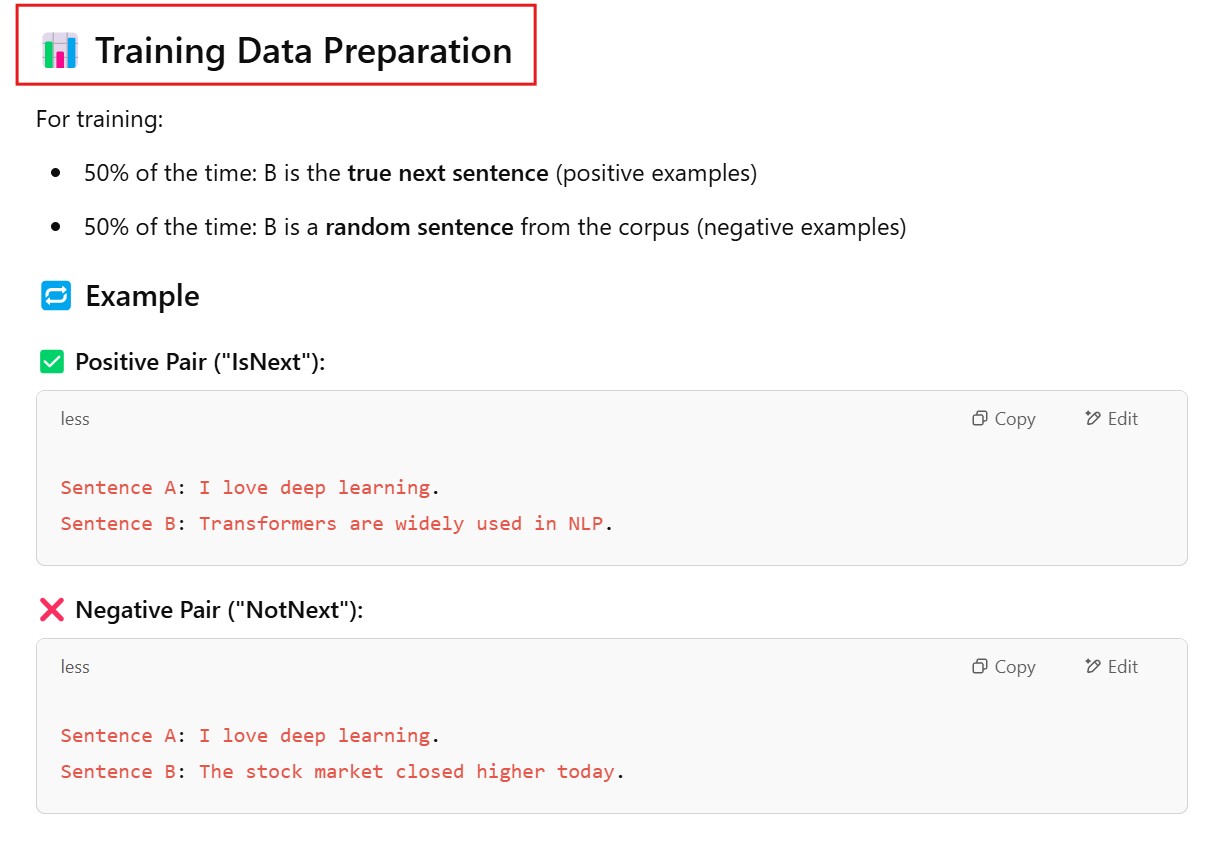
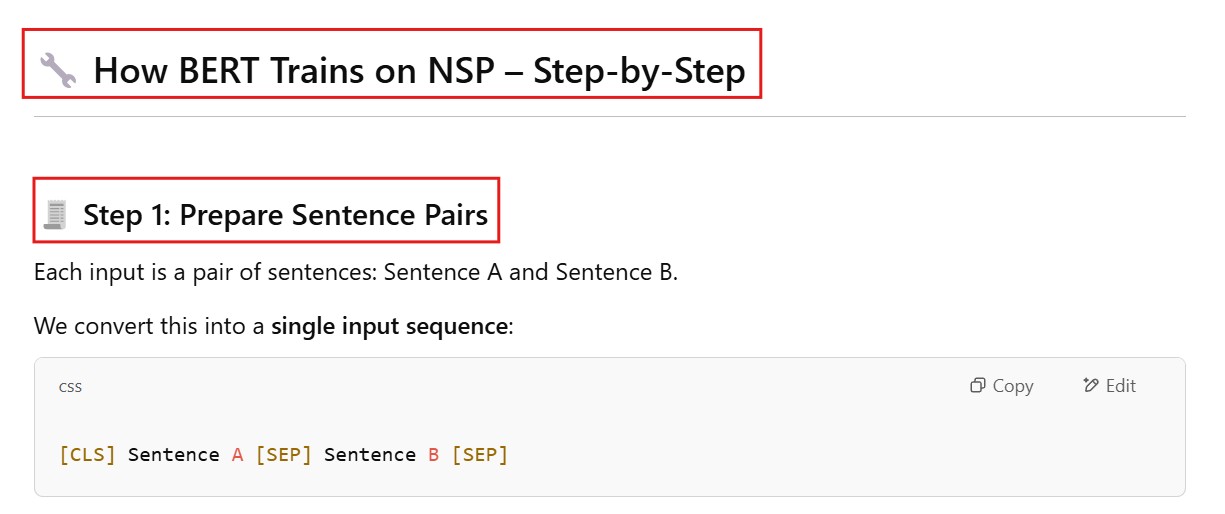
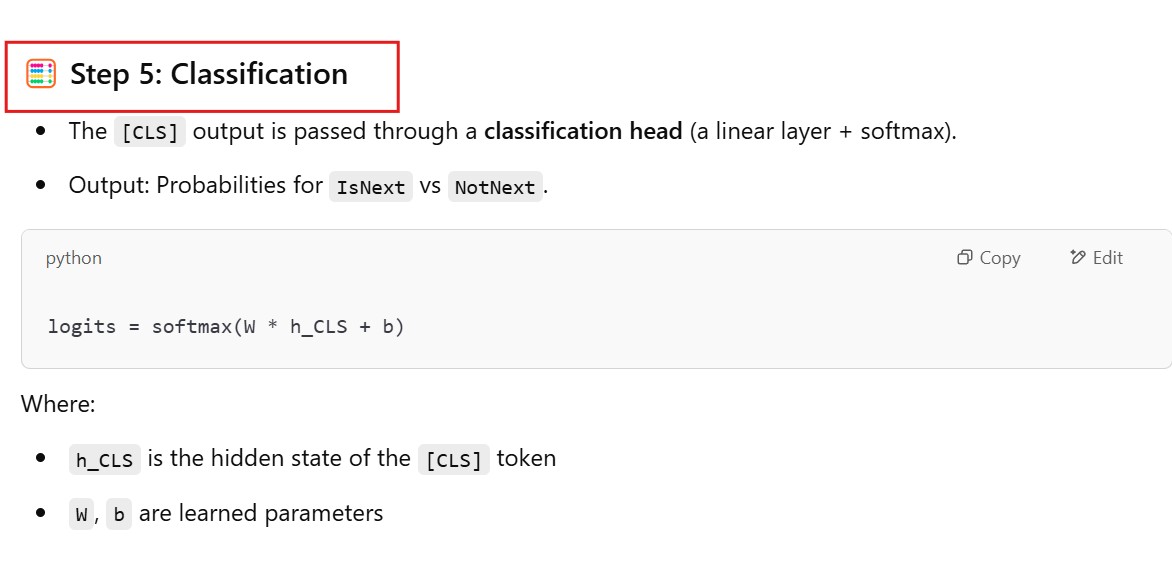
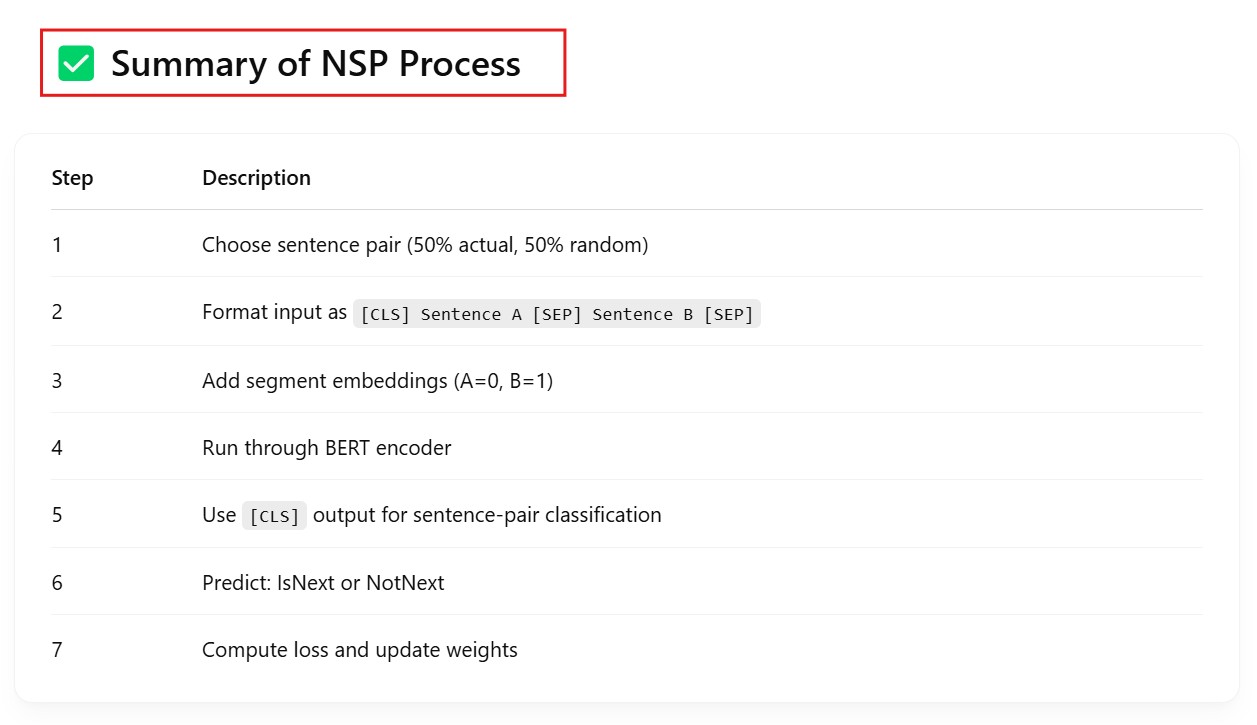
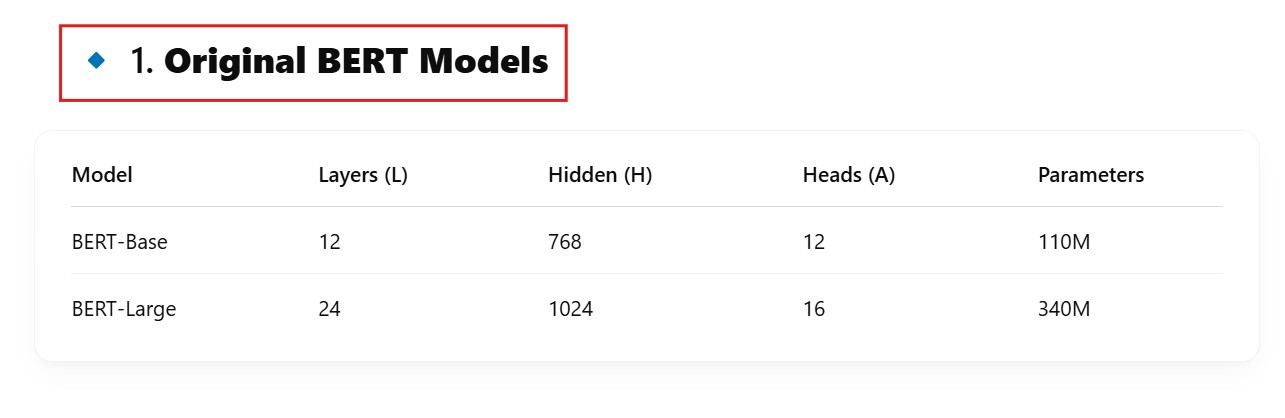
Being able to read text bidirectionally is one of the key reasons that Transformer models like BERT can achieve such impressive results in traditional NLP tasks. As we see from the above example, being able to know what “it” refers to is difficult when you read text in only one direction, and have to store all the state sequentially.
I guess it’s no surprise that this is a key feature of BERT, since the B in BERT stands for “Bidirectional”. The attention mechanism of the Transformer architecture allows models like BERT to process text bidirectionally by:
- Allowing parallel processing: Transformer-based models can process text in parallel, so they’re not limited by the bottleneck of having to process text sequentially like RNN-based models. This means that at any time the model is able to look at any word in the sentence it’s processing. But this introduces other problems. If you’re processing all the text in parallel, how do you know the order of the words in the original text? This is vital. If we don’t know the order, we’ll just have a bag of words-type model, unable to fully extract the meaning and context from the sentence.
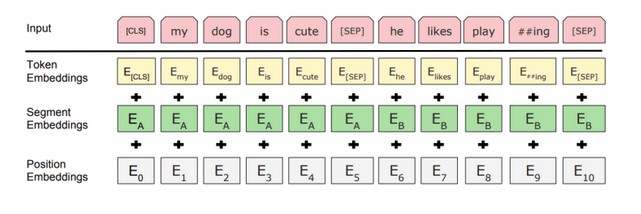
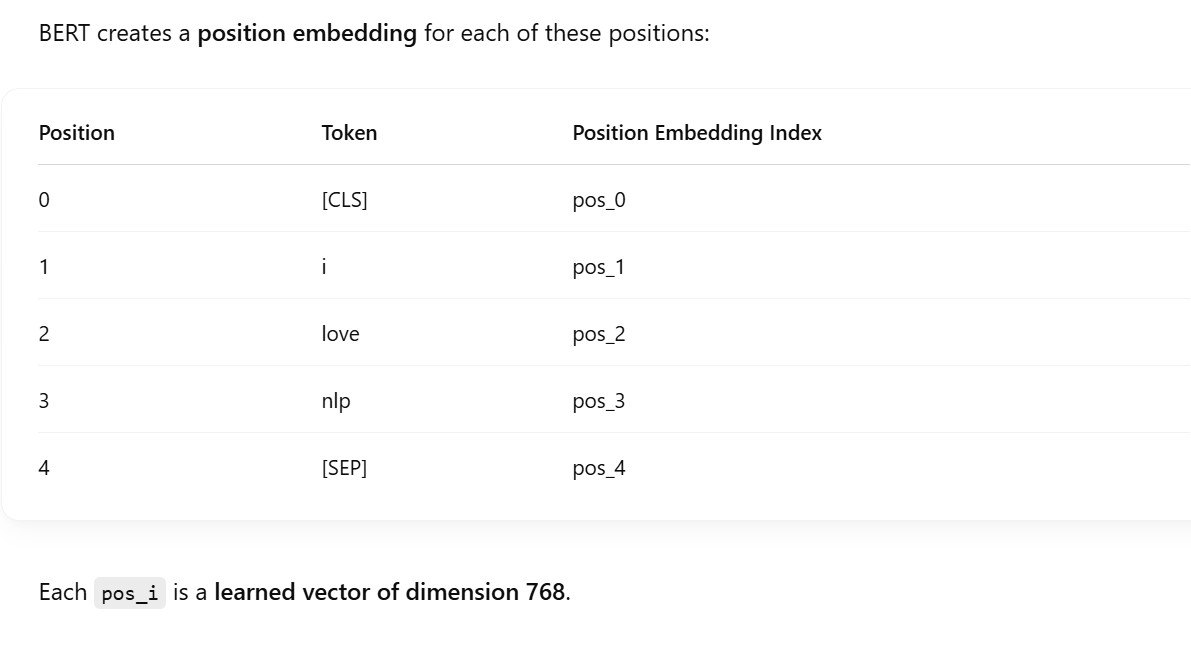
- Storing the position of the input: To address ordering issues, the Transformer architecture encodes the position of the word directly into the embedding. This is a “marker” that lets attention layers in the model identify where the word or text sequence they’re looking at was located. This nifty little trick means that these models can keep processing sequences of text in parallel, in large volumes with different lengths, and still know exactly what order they occur in the sentence.
- Making lookup easy: We noted earlier that one of the issues with RNN type models is that when they need to process text sequentially, it makes retrieving earlier words difficult. So in our “mouse” example sentence, an RNN would like to understand the relevance of the last word in the sentence, i.e. “laptop” or “cat”, and how it relates to the earlier part of the sentence. To do this, it has to go from N-1 word, to N-2, to N-3 and so on, until it reaches the start of the sentence. This makes lookup difficult, and that’s why context is tricky for unidirectional models to discover. By contrast, the Transformer based models can simply look up any word in the sentence at any time. In this way, it has a “view” of all the words in the sequence at every step in the attention layer. So it can “look ahead” to the end of the sentence when processing the early part of the sentence, or vice versa. (There is some nuance to this depending on the way the attention layers are implemented, e.g. encoders can look at the location of any word while decoders are limited to only looking “back” at words they have already processed. But we don’t need to worry about that for now).
As a result of these factors, being able to process text in parallel, embedding the position of the input in the embedding and enabling easy lookup of each input, models like BERT can “read” text bidirectionally.
Technically it’s not bidirectional, since these models are really looking at all the text at once, so it’s non-directional. But it’s better to understand it as a way to try and process text bidirectionally to improve the model’s ability to learn from the input.
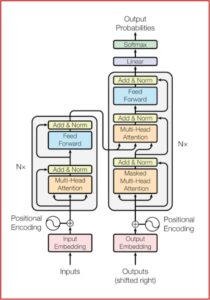
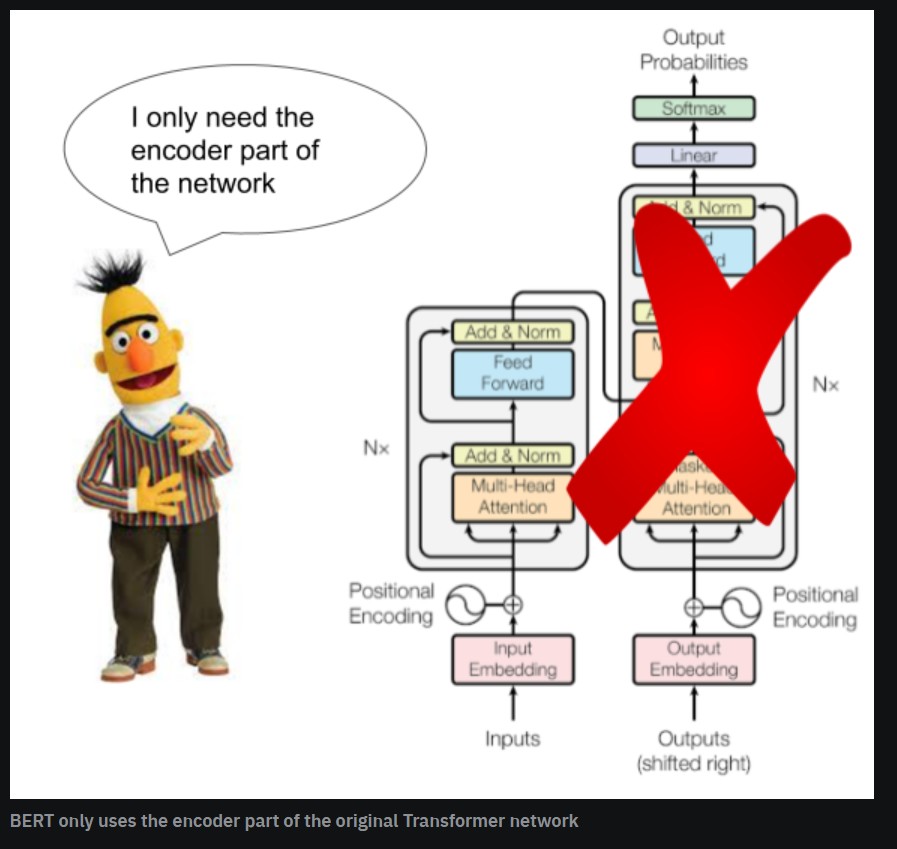
Being able to process text this way introduces some problems that BERT needed to address with a clever technique called “masking”, which we’ll discuss in section 8. But, now that we understand a little bit more about the Transformer architecture, we can look at the differences between BERT and the vanilla Transformer architecture in the original “Attention is all you need” paper.