from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("MyApp").getOrCreate()
We need to first initialize a Spark application to enable distributed data processing with Apache Spark.
you are initializing a Spark application. This is the entry point for using Spark.
(2) Driver Program Is Launched
from pyspark.sql import SparkSession
# This runs on the DRIVER
spark = SparkSession.builder.appName("SalesApp").getOrCreate()
df = spark.read.csv("sales.csv", header=True, inferSchema=True) # Transformation
result = df.groupBy("Region").sum("Revenue") # Transformation
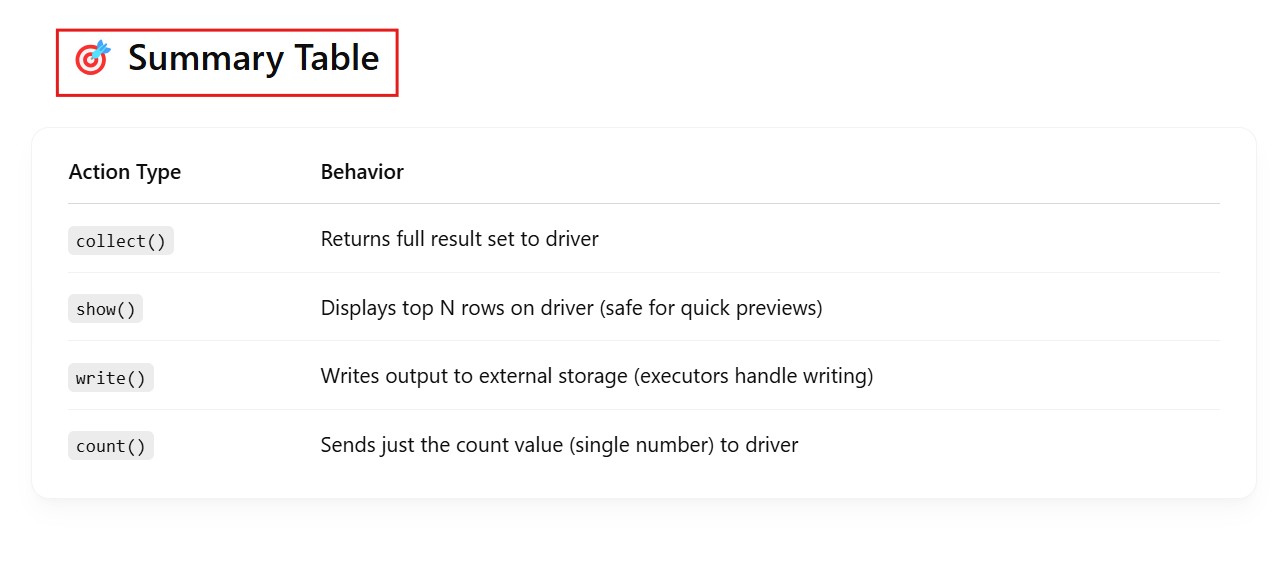
result.show() # Action
The actual processing is done by Workers, but Driver gives the instructions.
(3) Cluster Manager Allocates Resources
(4) Job Is Created On Action
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("LazyExample").getOrCreate()
df = spark.read.csv("employees.csv", header=True)
# These are only transformations (they're lazy)
filtered_df = df.filter(df["age"] > 30)
selected_df = filtered_df.select("name", "department")
# No data has been processed yet!
# Now this action triggers everything above
selected_df.show()
💡 Until you call .show(), Spark does nothing— it just builds a plan.
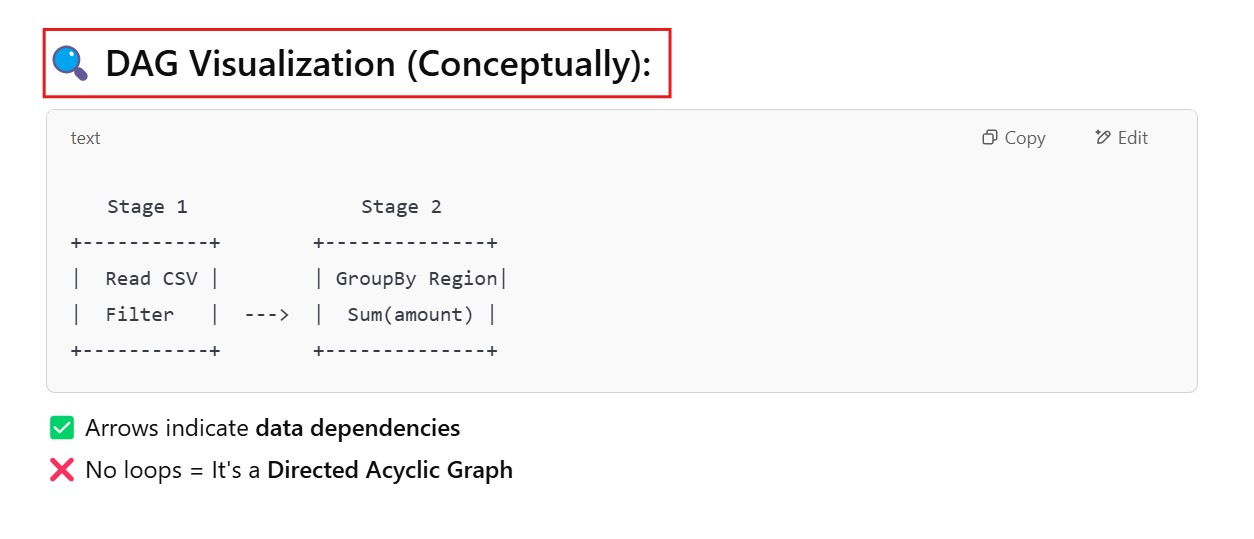
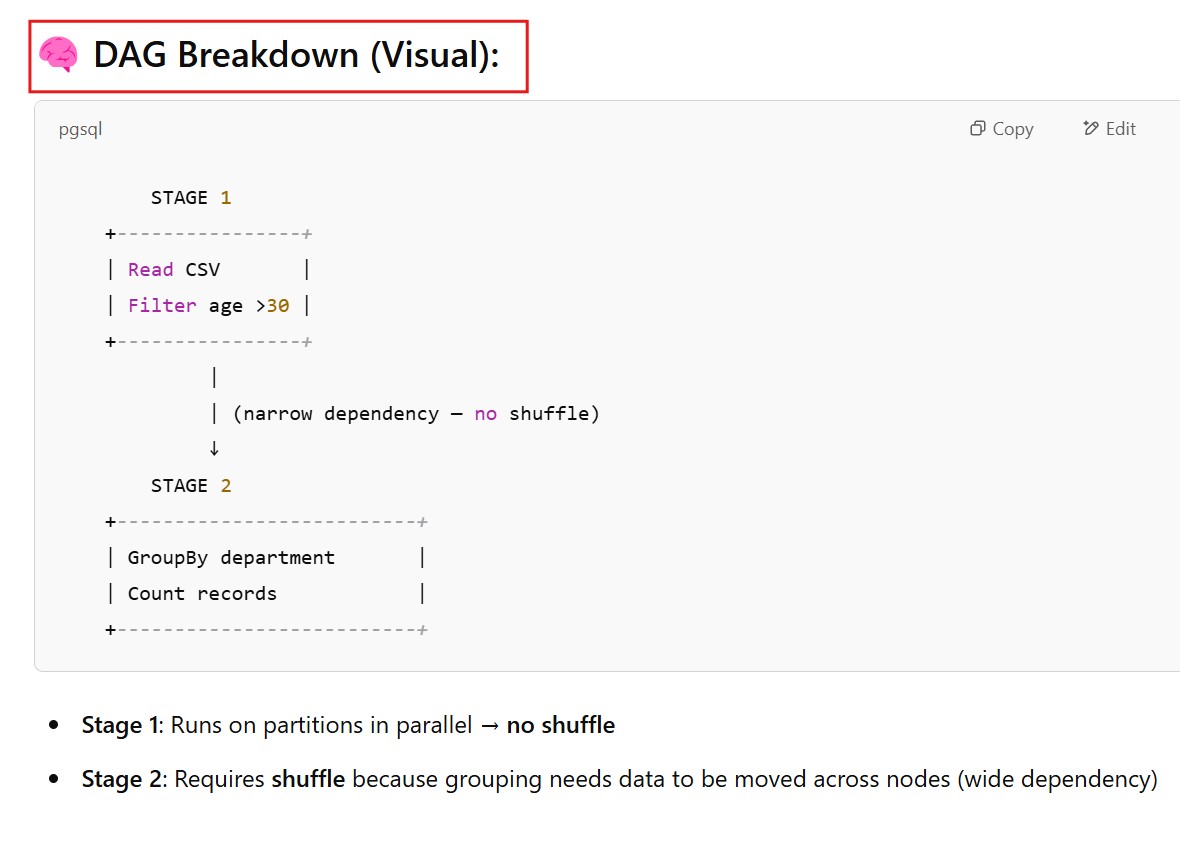
(5) DAG Scheduler Breaks Job into Stages
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DAGExample").getOrCreate()
# Step 1: Load the sales data
df = spark.read.csv("sales.csv", header=True, inferSchema=True)
# Step 2: Filter for high-value transactions
filtered_df = df.filter(df["amount"] > 500)
# Step 3: Group by region and sum the amounts
grouped_df = filtered_df.groupBy("region").sum("amount")
# Step 4: Show the result
grouped_df.show()