(2) Step-by-Step Guide to Build HR Policy Assistant (RAG-based)
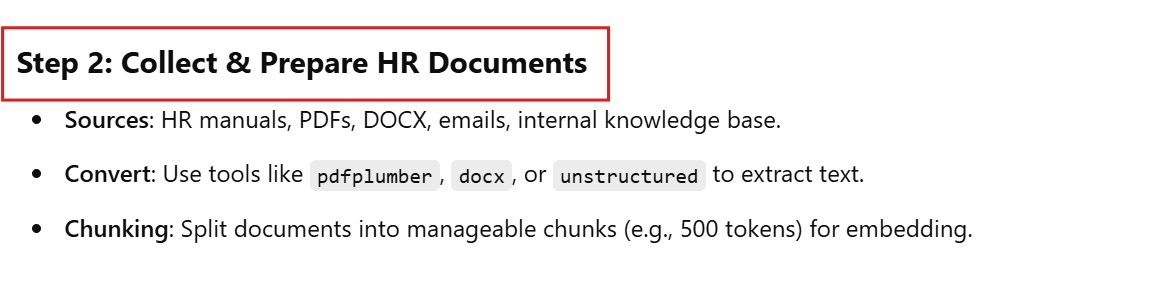
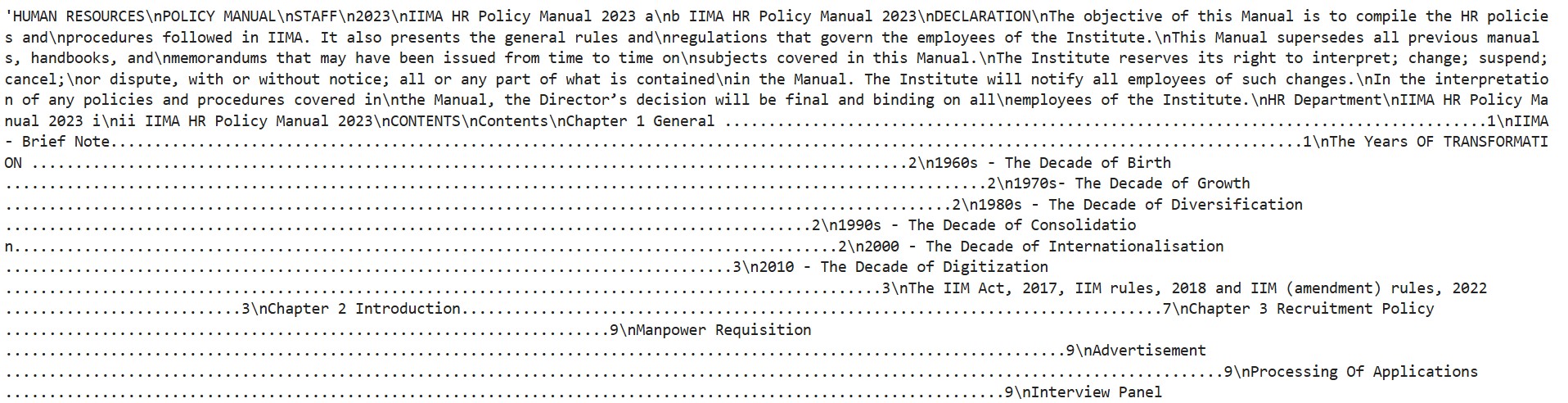
(3) Collect & Prepare HR Documents.
(1) Install Required Libraries
pdfplumber
python-docx
unstructured
pip install pdfplumber python-docx unstructured
(2) Load and Extract Text from Documents
import os
import pdfplumber
from docx import Document
def load_text_from_pdf(file_path):
text = ""
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
text += page.extract_text() + "\n"
return text
def load_text_from_docx(file_path):
doc = Document(file_path)
return "\n".join([para.text for para in doc.paragraphs])
def load_text_from_txt(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
def load_documents(folder_path):
documents = []
for filename in os.listdir(folder_path):
path = os.path.join(folder_path, filename)
if filename.endswith(".pdf"):
content = load_text_from_pdf(path)
elif filename.endswith(".docx"):
content = load_text_from_docx(path)
elif filename.endswith(".txt"):
content = load_text_from_txt(path)
else:
print(f"Skipped unsupported file: {filename}")
continue
documents.append({"filename": filename, "content": content})
return documents
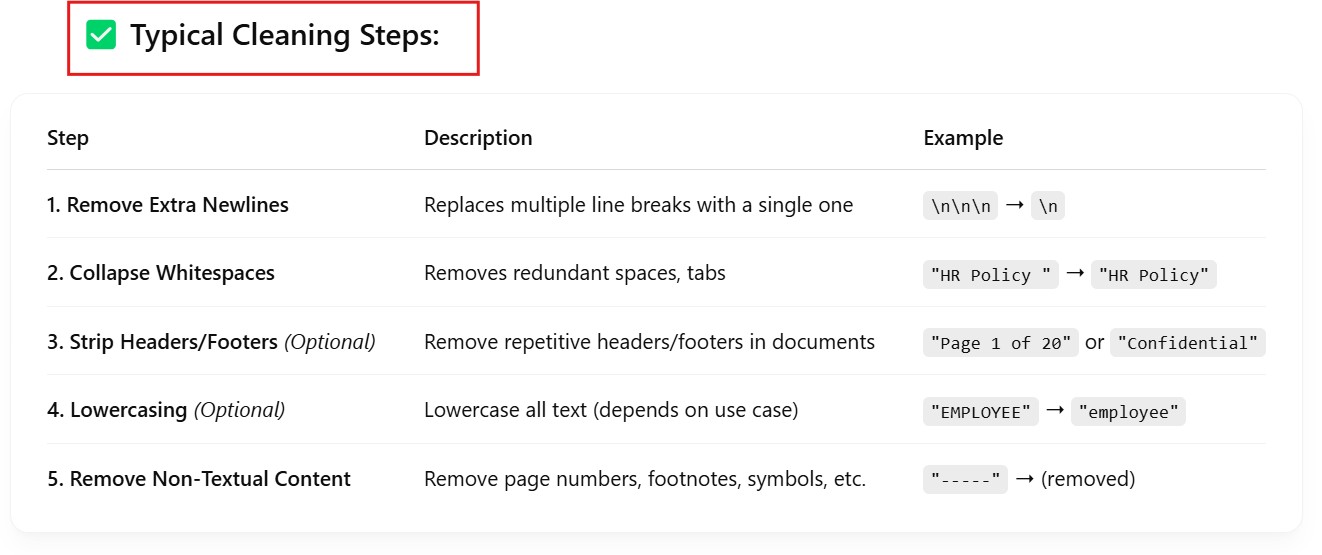
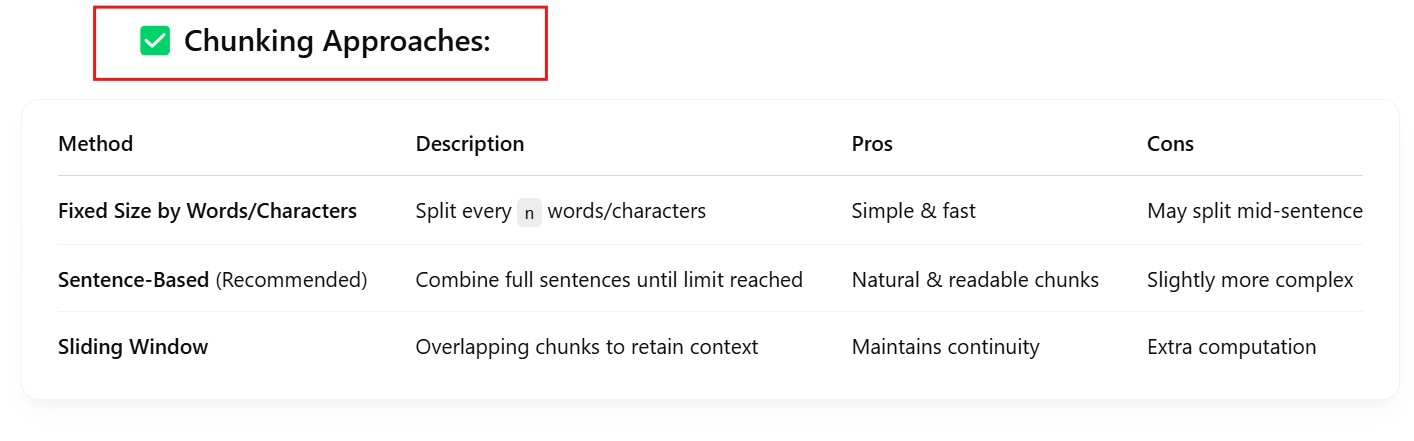
(3) Clean and Chunk Text for Embeddings
import re
def clean_text(text):
# Basic cleaning
text = re.sub(r'\n+', '\n', text) # Remove extra newlines
text = re.sub(r'\s+', ' ', text) # Collapse whitespaces
return text.strip()
def chunk_text(text, chunk_size=500):
# Simple sentence-based chunking
sentences = re.split(r'(?<=[.!?]) +', text)
chunks, current_chunk = [], ""
for sentence in sentences:
if len(current_chunk) + len(sentence) <= chunk_size:
current_chunk += " " + sentence
else:
chunks.append(current_chunk.strip())
current_chunk = sentence
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
(4) Run the Whole Pipeline
folder_path = "F:/Praudyog/OpenAI" # Your HR policy documents folder
documents = load_documents(folder_path)
all_chunks = []
for doc in documents:
cleaned = clean_text(doc["content"])
chunks = chunk_text(cleaned)
for i, chunk in enumerate(chunks):
all_chunks.append({
"source": doc["filename"],
"chunk_id": i,
"content": chunk
})
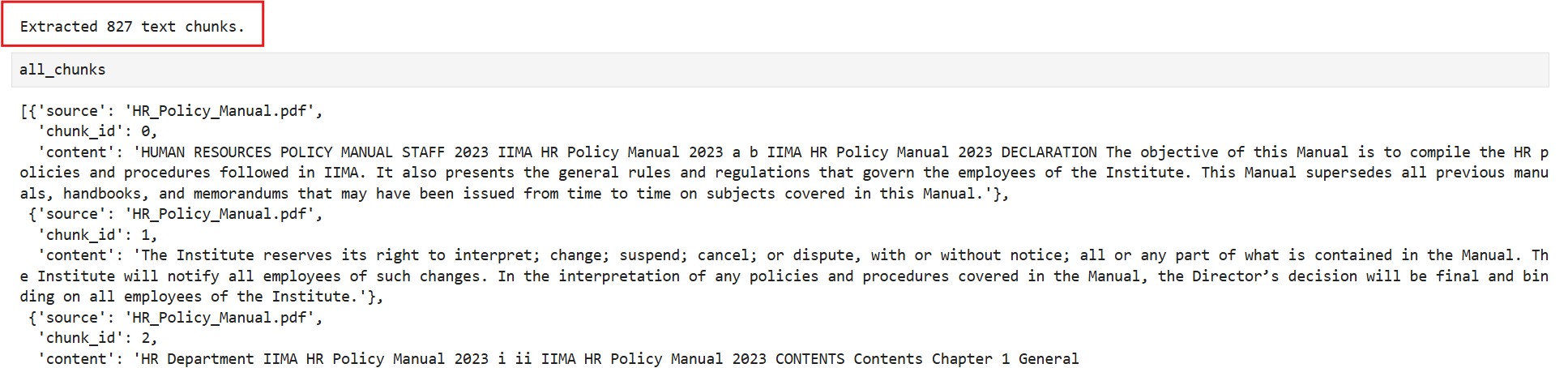
print(f"Extracted {len(all_chunks)} text chunks.")
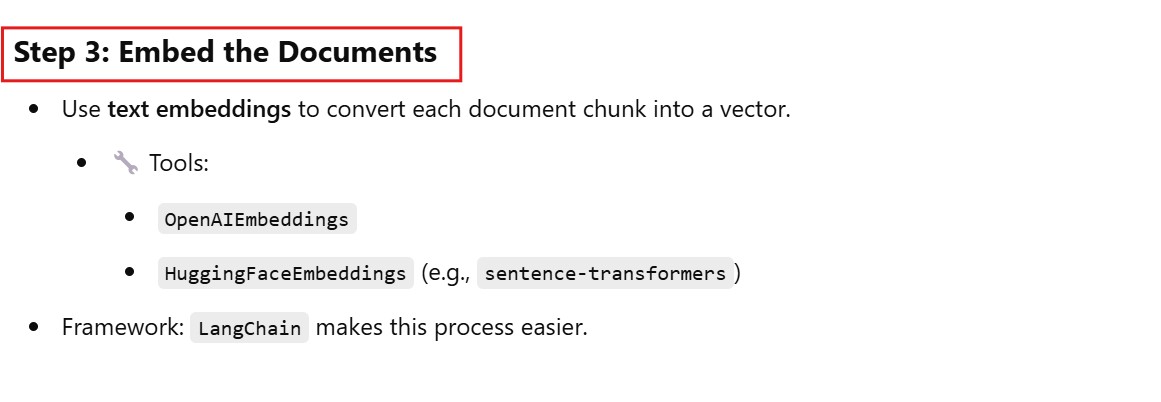
(4) Embed The Documents & Store In Vector DB
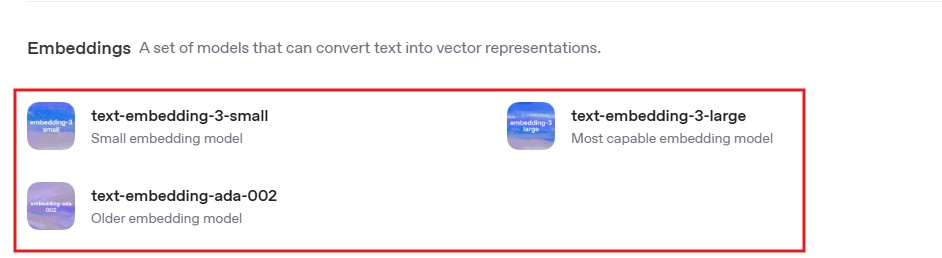
OpenAI Embedding Models
text-embedding-3-small
text-embedding-3-large
text-embedding-ada-002
Open Source Embedding Models
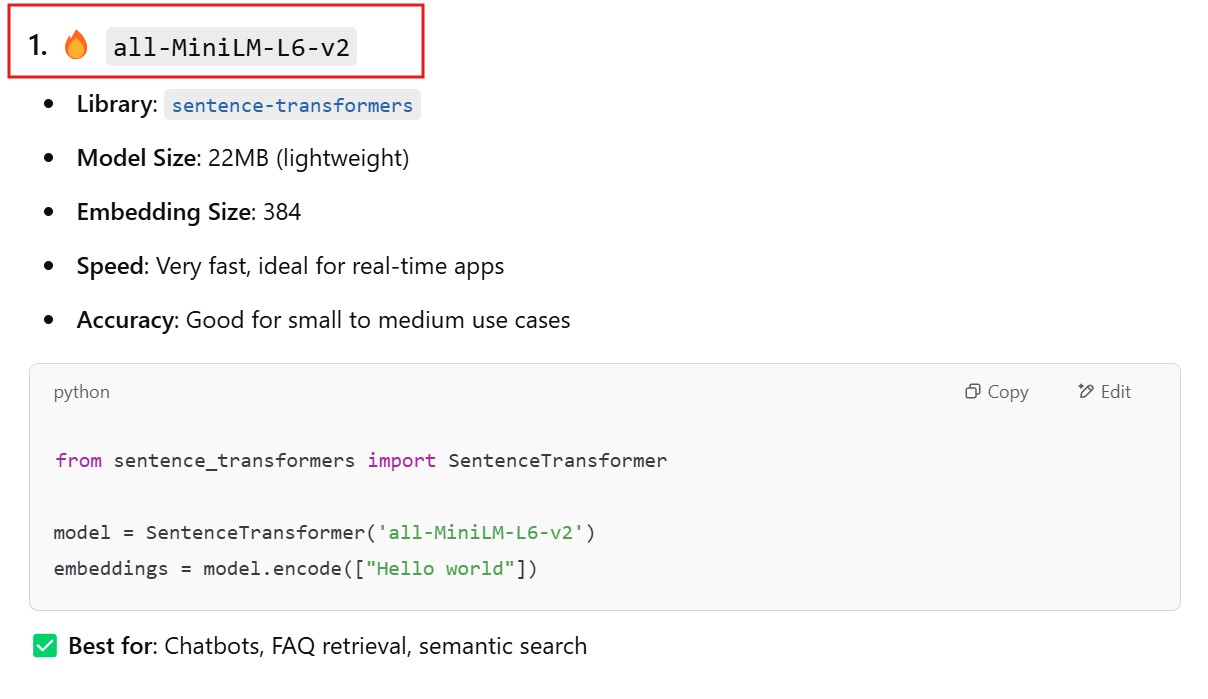
all-MiniLM-L6-v2
multi-qa-MiniLM-L6-cos-v1
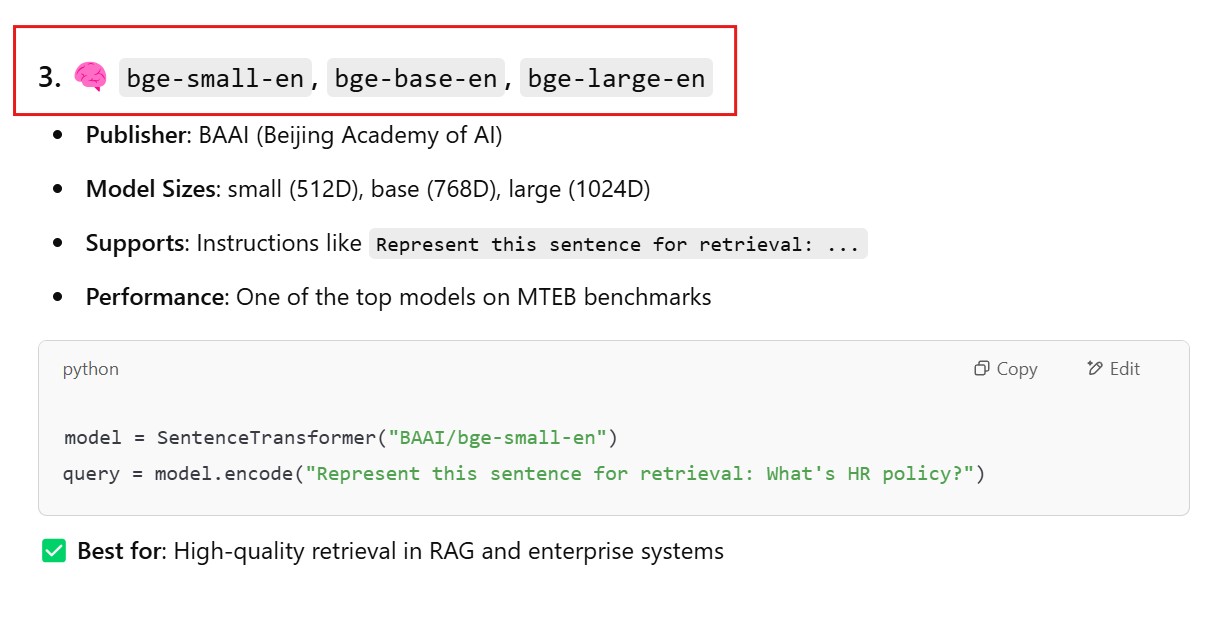
bge-base-en, bge-small-en, bge-large-en
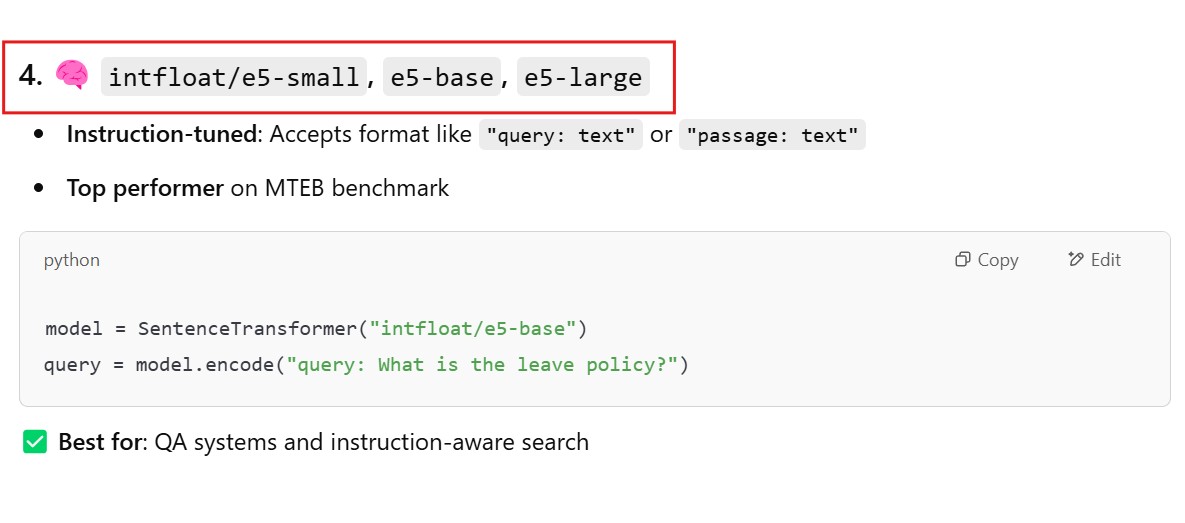
intfloat/e5-small, e5-base, e5-large
GTR-T5-base, GTR-T5-large
Available Vector DB
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Milvus
from langchain.docstore.document import Document
from dotenv import load_dotenv
import os
# Load your OpenAI API Key from .env file
load_dotenv()
# Prepare your HR policy chunks
chunks = [
"Employees are entitled to 12 days of casual leave annually.",
"The working hours are from 9 AM to 6 PM, Monday through Friday.",
"Any violation of company policies will result in disciplinary action."
]
# Wrap them into LangChain Documents
documents = [Document(page_content=chunk) for chunk in chunks]
# Create OpenAI embedding model (text-embedding-3-large)
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
# Connect to Milvus (assumes you have it running locally or via Zilliz Cloud)
milvus_vectorstore = Milvus.from_documents(
documents,
embedding_model,
connection_args={
"host": "localhost", # or your Milvus server IP
"port": "19530" # default Milvus port
},
collection_name="hr_policy_embeddings"
)
print("✅ Embeddings stored in Milvus!")
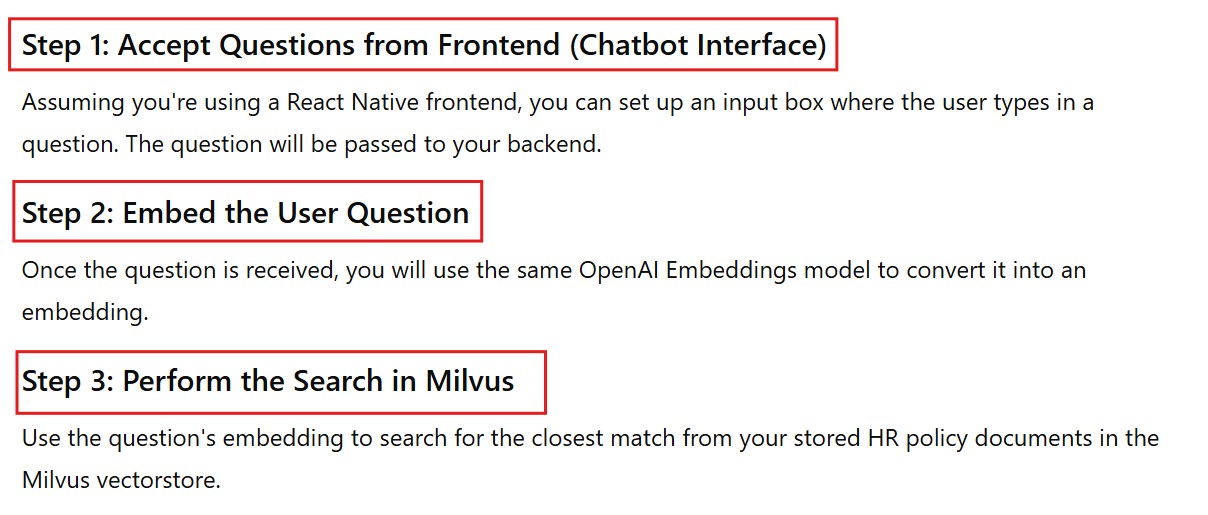
(5) Accept User Queries & Retrieve Relevant Context
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Milvus
from dotenv import load_dotenv
import os
# Load your OpenAI API Key from .env file
load_dotenv()
# Create OpenAI embedding model (text-embedding-3-large)
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
# Connect to Milvus (assumes you have it running locally or via Zilliz Cloud)
milvus_vectorstore = Milvus(
embedding_model,
connection_args={
"host": "localhost", # or your Milvus server IP
"port": "19530" # default Milvus port
},
collection_name="hr_policy_embeddings"
)
# Accept a new question (from your frontend/chatbot)
user_question = "How many days of casual leave do employees get annually?"
# Embed the user's question using the same OpenAI model
question_embedding = embedding_model.embed([user_question])
# Search for the closest matches in Milvus
search_results = milvus_vectorstore.similarity_search(question_embedding[0], k=3)
# Display the search results (HR policy content)
print("Matching HR Policy Content:")
for result in search_results:
print(result.page_content)
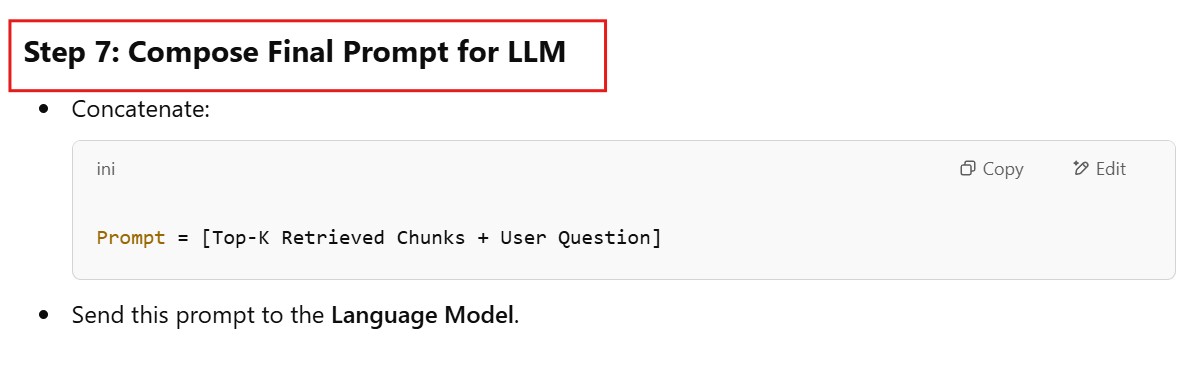
(6) Compose Final Prompt For LLM
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Milvus
from dotenv import load_dotenv
import os
# Load environment variables
load_dotenv()
# Create OpenAI embedding model (text-embedding-3-large)
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
# Connect to Milvus (assumes you have it running locally or via Zilliz Cloud)
milvus_vectorstore = Milvus(
embedding_model,
connection_args={
"host": "localhost", # or your Milvus server IP
"port": "19530" # default Milvus port
},
collection_name="hr_policy_embeddings"
)
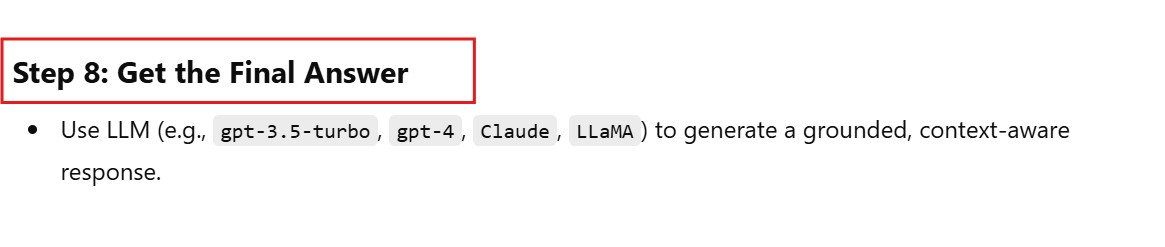
# Create OpenAI LLM
llm = OpenAI(model="text-davinci-003", temperature=0.5)
# Accept a new question (from your frontend/chatbot)
user_question = "How many days of casual leave do employees get annually?"
# Embed the user's question using the same OpenAI model
question_embedding = embedding_model.embed([user_question])
# Search for the closest matches in Milvus (retrieve top K results)
search_results = milvus_vectorstore.similarity_search(question_embedding[0], k=3)
# Concatenate the top-K retrieved chunks with the user question to create the final prompt
retrieved_chunks = "\n".join([result.page_content for result in search_results])
# Final prompt for LLM
final_prompt = f"HR Policy Information:\n{retrieved_chunks}\n\nUser Question: {user_question}\n\nProvide a detailed answer based on the HR policy information."
# Print the final prompt (optional for debugging)
print("Final Prompt for LLM:")
print(final_prompt)
# Pass the final prompt to the OpenAI model to get the response
response = llm(final_prompt)
# Display the response from the LLM
print("\nResponse from LLM:")
print(response)